Data analysis is one of the cornerstones of product management. It’s the compass guiding our decision-making process. What few people understand about the “data-driven” decision making, however, is that misinterpretation can be worse than just following gut feelings.

One such pitfall in this analytical journey is the under-appreciated and often overlooked type II error, representing missed opportunities and false assumptions that can profoundly impact our products.
In this article, we’ll delve into how these errors can affect product management decisions and explore various strategies for minimizing their occurrence. Whether you’re a seasoned product manager, a data analyst, or a newcomer to the field, navigating the complexities of type II errors will only improve your product game.
Ever since Eric Ries published The Lean Start-up, product management has been all about learning and less about delivering. With learning at the center, data has become the building block of knowledge, and data analysis has become the indispensable tool for product managers to build that knowledge. From decision-making to crafting winning strategies, product managers must navigate a sea of information to identify what matters among the noise.
However, data analysis is a double-edged sword. While it is fundamental to promote discovery, it can also lead you to misteps if not correctly leveraged. An almost century old statistical concept lies between success and failure: the type I and type II errors. Often referred to as false-positives and false negatives, they are both halves of the same phenomenon.
A type II error is a false negative — it occurs when you fail to reject a null hypothesis. This happens when you conclude that your experiment did not have any meaningful effect (or that there is no difference between two groups you’re testing) even though there actually was one! Think of it as a missed opportunity to discover something because our test erroneously indicated that there’s “nothing to see here:”
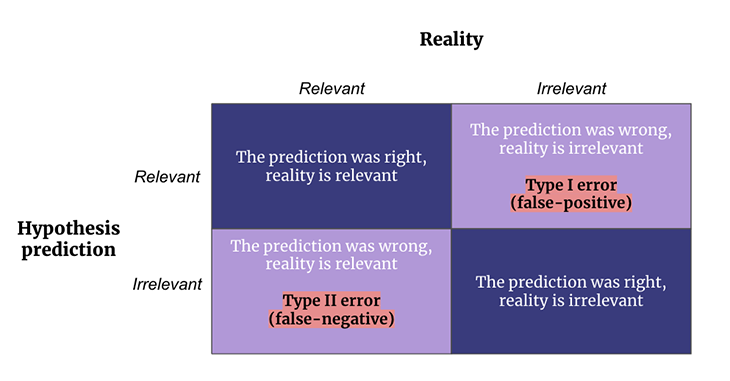
For product managers, an example of a type II error would be disregarding a promising lead based on flawed evidence, something no product manager wants on their conscience:

The implications of a type II error in data analysis for product discovery and prioritization are far-reaching. It represents the risk of sticking with the status quo when change could be beneficial. Even worse, it could mean changing, expecting the best, but ultimately compromising with the wrong bet and having a worse product than what you started with.
And how do you avoid doing type II errors then? Where should you be looking at so that you mitigate the risks of missing-out? Let’s see how you can do it.
Picture this — you have been working on a new feature based on months of customer feedback. Before committing with a full launch, you use A/B testing to determine whether the change is worth it or not. The results come back inconclusive. Based on the data, you decide to pull the feature, deeming it ineffective.
Later, you learn that the users who did take advantage of the new feature were among your most valuable customers, showing increased activity and higher retention rates. Here, you’ve fallen prey to a type II error, mistakenly accepting the null hypothesis that the feature change isn’t worth it and missing out on the potential advantage of the new feature.
This is one of many real-life examples where type II errors can make a significant impact on product management. Every false negative — each time a type II error makes us overlook a true effect or difference — is an opportunity lost.
Beyond technical problems with tests or result collections, the prevalence of type II errors often traces back to small sample sizes, poor sample distribution, or biases in hypothesis testing:
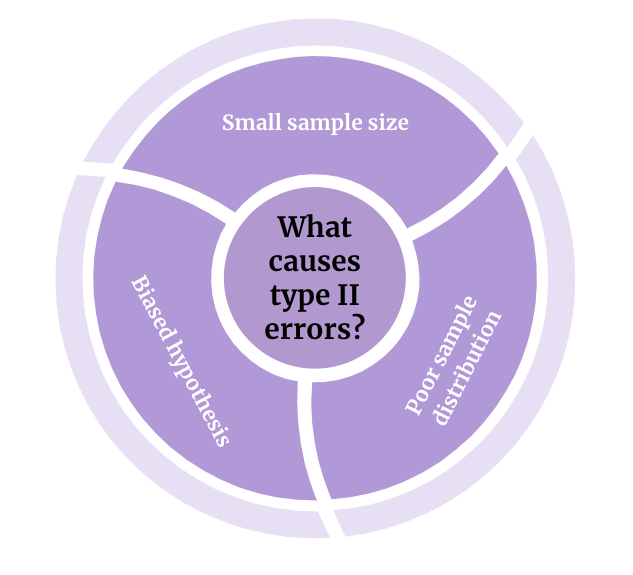
When your sample size is too small, the statistical power of your test decreases. This means you might not detect an actual effect even when it exists. The less data you have, the more your results tend to be random.
If you only ask three people “what’s the best type of cuisine in Europe,” you most probably won’t have a faithful conclusion. If you ask the same question to a thousand people, some cuisines will visibly stand out more than others because you polled a ton of people.
Another critical factor for getting type II errors is poor sample distribution. Sample distribution is the exercise of collecting data from the most diverse possible population. A test with poor sample distribution could lean into bias distortion, increasing the risk of type II errors.
With the same example shared before, imagine that your 1,000 people sample are mostly from France. English cuisine would probably come up as one of the worst cuisines in Europe, even though this might not be true if you ask the same question to other Europeans.
When your hypothesis is ill-formulated, no amount of sampling caution can save you from statistical error. Sticking with European cuisine, let’s say that we change the question from “which is the best” to “is French your favorite cuisine?”
It’s highly possible that more than half of your sample say “no,” and that you could presume that French was not the best cuisine from Europe. By not taking into consideration the preference for alternatives to French food, you would be incapable of saying if there was any other cuisine that would get better results with the same question — meaning you have a false-negative in your hands.
Recognizing these factors and understanding how they contribute to type II errors can significantly shape the outcome of your product management efforts. It’s not just about understanding the theory; it’s about learning how to apply that understanding to improve your decision-making.
As we move on, let’s further dissect the methods that can help us mitigate these errors. Stay with me; you’re on the right path to becoming a more data-savvy product manager.
Now that we’ve identified the traps of type II errors and their causes, let’s navigate the route to minimizing these statistical hurdles. In this journey towards data-savvy product management, there are various strategic approaches and tools at your disposal.
Expanding your sample size not only reduces the likelihood of type II errors but also lends more credibility to your findings. But remember, size isn’t everything. Ensuring a diverse and representative sample distribution is equally vital. The world of your product users is a melting pot of different behaviors, preferences, and needs, and your sample should reflect this diversity to give you an accurate picture.
Enhancing your sample doesn’t always mean reaching out to more users. You can also broaden the scope of your data. For instance, if you’re testing a feature, consider monitoring its effects over a more extended period of time or in different usage contexts. These approaches can help expose effects or differences that may not be immediately apparent.
If you have the time and resources for it, perform a statistical power analysis. This way, you can identify what is the ideal sample size and distribution for your testing. Software like G*Power or programming languages with statistical capacities like Python and R can help you manage your statistical power and other aspects of your data
Here, the solution is more art than science. Crafting unbiased hypotheses requires you to remain open, curious, and skeptical. You need to question your assumptions, consider alternatives, and be prepared to be proved wrong.
Another key element in avoiding bias is leveraging diversity in your team or organization. Diverse teams bring a multitude of perspectives and challenge each other’s assumptions, which helps in questioning and validating hypotheses from various standpoints. In a sense, a diverse team serves as a ‘built-in’ mechanism for avoiding bias.
Iterative hypothesis testing is another practical strategy to minimize bias. Instead of crafting a single hypothesis and running one test, consider creating multiple hypotheses and conducting a series of tests. This iterative approach can reveal hidden patterns, allowing you to refine or even redefine your hypothesis based on real, tangible data.
Addressing type II errors is not a one-and-done deal, but a continuous process. It involves refining your techniques, questioning your results, and constantly learning from your mistakes. The more you exercise these strategies, the more they will become second nature, and the fewer type II errors will sneak past your watchful eye.
Type II errors represent the potentially correct step you didn’t take, rather than the erroneous one you did. It’s a silent specter of missed opportunities and incorrect assumptions that can hinder your product’s potential.
Addressing type II errors is about thoughtful hypothesis formulation, comprehensive sampling, and iterative testing. It requires continuous learning, leveraging statistical tools, methodologies, and multidisciplinary teams.
Evading type II errors is more than just improving data reliability; it’s about enhancing your decision-making prowess. As a product manager, recognizing and mitigating these errors equips you to identify real opportunities and steer your product on the right path.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.

Memos don’t have to be complicated. Just keep them clear, concise, and focused on actionable items. More on that in this blog.


