When managing products, product managers often use statistical testing to evaluate the impact of new features, user interface adjustments, or other product modifications. Statistical testing provides evidence to help product managers make informed decisions based on data, indicating whether a change has significantly affected user behavior, engagement, or other relevant metrics.

However, statistical tests aren’t always accurate, and there is a risk of type 1 errors, also known as “false positives,” in statistics. A type 1 error occurs when a null hypothesis is wrongly rejected, even if it’s true.
PMs must consider the risk of type 1 errors when conducting statistical tests. If the significance level is set too high or multiple tests are performed without adjusting for multiple comparisons, the chance of false positives increases. This could lead to incorrect conclusions and waste resources on changes that don’t significantly affect the product.
In this article, you will learn what a type 1 error is, the factors that contribute to one, and best practices for minimizing the risks associated with it.
A type 1 error, also known as a “false positive,” occurs when you mistakenly reject a null hypothesis as true. The null hypothesis assumes no significant relationship or effect between variables, while the alternative hypothesis suggests the opposite.
For example, a product manager wants to determine if a new call to action (CTA) button implementation on a web app leads to a statistically significant increase in new customer acquisition.
The null hypothesis (H₀) states no significant effect on acquiring new customers on a web app after implementing a new feature, and an alternative hypothesis (H₁) suggests a significant increase in customer acquisition. To confirm their hypothesis, the product managers gather information on user acquisition metrics, like the daily number of active users, repeat customers, click through rate (CTR), churn rate, and conversion rates, both before and after the feature’s implementation.
After collecting data on the acquisition metrics from two different periods and running a statistical evaluation using a t-test or chi-square test, the PM* *falsely believes that the new CTA button is effective based on the sample data. In this case, a type 1 error occurs as he rejected the H₀ even though it has no impact on the population as a whole.
A PM must carefully interpret data, control the significance level, and perform appropriate sample size calculations to avoid this. Product managers, researchers, and practitioners must also take these steps to reduce the likelihood of making type 1 errors:
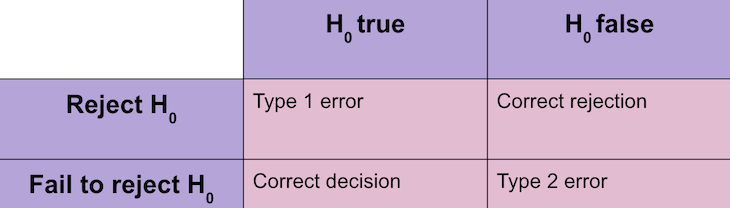
Before comparing type 1 and type 2 errors, let’s first focus on type 2 errors. Unlike type 1 errors, type 2 errors occur when an effect is present but not detected. This means a null hypothesis (Ho) is not rejected even though it is false.
In product management, type 1 errors lead to incorrect decisions, wasted resources, and unsuccessful products, while type 2 errors result in missed opportunities, stunted growth, and suboptimal decision-making. For a comprehensive comparison between type 1 and type 2 errors with product development and management, please refer to the following:
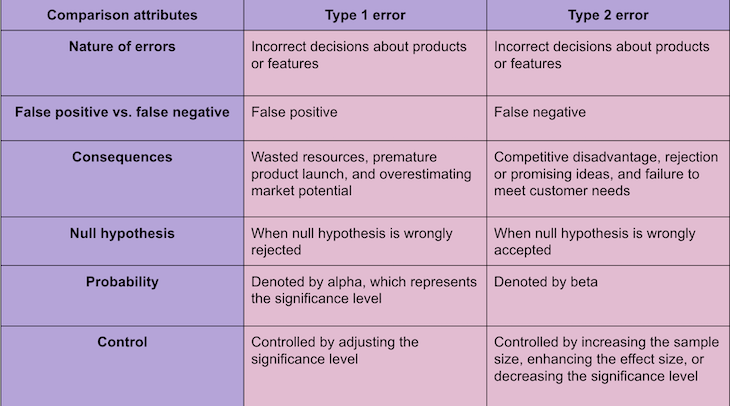
To understand the comparison table above, it’s necessary to grasp the relationship between type 1 and type 2 errors. This is where the concept of statistical power comes in handy.
Statistical power refers to the likelihood of accurately rejecting a null hypothesis( Ho) when it’s false. This likelihood is influenced by factors such as sample size, effect size, and the chosen level of significance, alpha (α).
With hypothesis testing, there’s often a trade-off between type 1 and type 2 errors. By setting a more stringent significance level with a lower α, you can decrease the chance of type 1 errors, but increase the chance of Type 2 errors.
On the other hand, by setting a less stringent significance level with a higher α, we can decrease the chance of type 2 errors, but increase the chance of type 1 errors.
It’s crucial to consider the consequences of each type of error in the specific context of the study or decision being made. The importance of avoiding one type of error over the other will depend on the field of study, the costs associated with the errors, and the goals of the analysis.
Type 1 errors can be caused by a range of different factors, but the following are some of the most common reasons:
When sample sizes are too small, there is a greater chance of type 1 errors. This is because random variation may affect the observed results rather than an actual effect. To avoid this, studies should be conducted with larger sample sizes, which increases statistical power and decreases the risk of type 1 errors.
When multiple statistical tests or comparisons are conducted simultaneously without appropriate adjustments, the likelihood of encountering false positives increases. Conducting numerous tests without correcting for multiple comparisons can lead to an inflated type 1 error rate.
Techniques like Bonferroni correction or false discovery rate control should be employed to address this issue.
Publication bias is when studies with statistically significant results are more likely to be published than those with non-significant or null findings. This can lead to misleading perceptions of the true effect sizes or relationships. To mitigate this bias, meta-analyses or systematic reviews consider all available evidence, including unpublished studies.
When conducting experimental studies, selecting the wrong control group or comparison condition can lead to inaccurate results. Without a suitable control group, distinguishing the actual impact of the intervention from other variables becomes difficult, which raises the likelihood of making type 1 errors.
When researchers allow their personal opinions or assumptions to influence their analysis, they can make type 1 errors. This is especially true when researchers favor results that align with their expectations, known as confirmation bias.
To reduce the chances of type 1 errors, it’s crucial to consider these factors and utilize appropriate research design, statistical analysis methods, and reporting protocols.
In software product management, minimizing type 1 errors is important. To help you better understand, here are some examples of type 1 errors from product management in the context of null hypothesis (Ho) validation, alongside strategies to mitigate them:
Here, the assumption is that specific features of your software would greatly improve user involvement. To test this hypothesis, a PM conducts experiments and observes increased user involvement. However, it later becomes clear that the boost was not solely due to the feature, but also other factors, such as a simultaneous marketing campaign.
This results in a type 1 error.
Experiments focusing solely on the analyzed feature are important to avoid mistakes. One effective method is A/B testing, where you randomly divide users into two groups — one group with the new feature and the other without. By comparing the outcomes of both groups, you can accurately attribute any observed effects to the feature being tested.
In this case, a PM believes there is a direct connection between the number of bug fixes and customer satisfaction scores (CSAT). However, after examining the data, you find a correlation that appears to support your hypothesis that could just be coincidental.
This leads to a Type 1 error, where bug fixes have no direct impact on CSAT.
It’s important to use rigorous statistical analysis techniques to reduce errors. This includes employing appropriate statistical tests like correlation coefficients and evaluating the statistical significance of the correlations observed.
Another potential instance comes when a hypothesis states that the performance of the software can be greatly enhanced by implementing a particular optimization technique. However, if the optimization technique is implemented and there is no noticeable improvement in the software’s performance, a type 1 error has occured.
To ensure the successful implementation of optimization techniques, it is important to conduct thorough benchmarking and profiling beforehand. This will help identify any existing bottlenecks.
A type 1 error occurs when an algorithm claims to predict user behavior or outcomes with high accuracy and then often falls short in real-life situations.
To ensure the effectiveness of algorithms, conduct extensive testing in real-world settings, using diverse datasets and consider various edge cases. Additionally, evaluate the algorithm’s performance against relevant metrics and benchmarks before making any bold claims.
Designing rigorous experiments, using proper statistical analysis techniques, controlling for confounding variables, and incorporating qualitative data are important to reduce the risk of type 1 error.
To reduce the chances of type 1 errors, product managers should take the following measures:
Product managers must grasp the importance of type 1 errors in statistical testing. By recognizing the possibility of false positives, you can make better evidence-based decisions and avoid wasting resources on changes that do not truly benefit the product or its users. Employing appropriate statistical techniques, considering effect sizes, replicating findings, and conducting rigorous experiments can help mitigate the risk of type 1 errors and ensure reliable decision-making in product management.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

PMs don’t need fake authority to lead well. Learn how shared context, clearer trade-offs, and better decision-making build stronger teams.
Learn how PMs can spot novelty effects in A/B tests, validate wins over time, and avoid mistaking short-term lifts for impact.

Map AI data risks, vet vendors, run safer pilots, and build legal buy-in for AI tools without creating security gaps.

SVP of Product Sriram Iyer visits to chat about how he uses AI to launch the “thinnest slice of pizza” product and shift mindsets around AI.


