Prisma is an open source ORM that allows you to easily manage and interact with your database. In this guide, we’ll discuss the features, benefits, and use cases of Prisma to help you decide if it’s the right choice for your next project.

Let’s get started.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Prisma is an ORM for Node.js and Typescript that serves as an alternative to writing plain SQL or using other database access tools, such as Knex or Sequelize. It simplifies database access and management by providing developers with a type-safe query builder and auto-generator.
The Prisma Labs team founded Prisma in 2016, aiming to make working with databases more fun, productive and delightful. They started with Graphcool and Prisma 1, where both were focused on simplifying GraphQL API building and deployment.
As the project evolved and became more popular, Prisma became a standalone project that was released as Prisma 2.0 in 2020. Its main features included:
At the time of this writing, Prisma is currently on v5.10. The Prisma ecosystem now features the Prisma Migrate tool, products like Prisma Accelerate and Prisma Pulse to extend Prisma ORM, and more.
Let’s get to know how Prisma works. Everything starts with the Prisma schema, where you can define database models and relations using Prisma’s schema language, a more intuitive data modeling language.
You can write a Prisma schema in your project from scratch or generate it from an existing database. Since Prisma is database-agnostic, let’s take a quick look at how we can define a schema model in Prisma for both relational databases and non-relational databases.
Here’s an example schema model for relational databases using SQLite as the provider:
schema.prisma
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model Author {
author_id Int @id @default(autoincrement())
author_name String
email String
created_at DateTime
// Define the relation to the Posts model
posts Post[]
// Define the relation to the Comments model
comments Comment[]
}
// Define the Posts model
model Post {
post_id Int @id @default(autoincrement())
title String
content String
created_at DateTime
// Define the relation to the Author model
author Author @relation(fields: [author_id], references: [author_id])
author_id Int
// Define the relation to the Comments model
comments Comment[]
}
// Define the Comments model
model Comment {
comment_id Int @id @default(autoincrement())
content String
created_at DateTime
// Define the relation to the Author model
author Author @relation(fields: [author_id], references: [author_id])
author_id Int
// Define the relation to the Post model
post Post @relation(fields: [post_id], references: [post_id])
post_id Int
}
Here’s an example schema model for non-relational databases using MongoDB as the provider:
schema.prisma
datasource db {
provider = "mongodb"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
// Define the Author model
model Author {
id String @id @default(auto()) @map("_id") @db.ObjectId
authorName String
email String @unique
createdAt DateTime @default(now())
posts Post[]
comments Comment[]
}
// Define the Post model
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String
content String?
createdAt DateTime @default(now())
author Author @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
comments Comment[]
}
// Define the Comment model
model Comment {
id String @id @default(auto()) @map("_id") @db.ObjectId
content String
created_at DateTime @default(now())
author Author @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
post Post @relation(fields: [postId], references: [id])
postId String @db.ObjectId
}
In these two schemas, we first configured our datasource by specifying our database connection using an environment variable to carry the connection string. In our examples above, we’re using sqlite and mongodb. However, it’s easy to adapt this to any other database provider.
Let’s say your database provider is PostgreSQL. All you need is to load the connection string using the environment variable and specify the provider as postgresql:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
Also, we configured the generator, which specifies that we want to generate Prisma Client.
Lastly, we defined some data models: Author, Posts, and Comments. A model has two main functions: to represent a table in a relational database or a collection in a non-relational database like MongoDB, and to provide the foundation for queries in the Prisma Client API.
Before Prisma, working with and debugging complex ORM objects and SQL queries using relational databases often caused critical bottlenecks in the development process.
Prisma makes it easier for developers to work with database queries by providing clean and type-safe APIs for submitting database queries that return plain old JavaScript objects. Some of its benefits include:
Prisma is not only database agnostic, but also platform agnostic. It’s compatible with several frontend technologies, which means we can use Prisma for database operations while working with backend APIs in Next.js, Vue.js, Angular, and more.
Let’s take Next.js as an example. Next bridges the gap between the client and server with its support for both SSG and SSR. Frontend developers working with databases in a Next.js app can access their database with Prisma at build time (SSG) or during request time (SSR) using the API routes.
While we’ve seen how great Prisma can be, it’s only fair to also discuss some of the cons of this tool:
With that in mind, Prisma’s drawbacks should only affect specific situations and project needs. For the most part, its pros outweigh the cons, making Prisma a great choice for many developers and projects.
Setting Prisma up in your project is easy and straightforward. You’ll need the following prerequisites to integrate Prisma to your project:
Once you have fulfilled these two prerequisites, initialize a new Node.js project if you are starting from scratch. Run these commands on your machine’s terminal:
mkdir node-prisma-project cd node-prisma-project npm init -y
Running this command will create a directory for your project, change into that directory, and then create a basic Node.js project using the command.
Then, you can install the Prisma CLI into the project as a dependency using the command below:
npm install prisma / yarn add prisma
Using the Prisma CLI, you can initialize Prisma in your project using this command:
npx prisma init
This will create a new Prisma directory in your project folder with a schema.prisma file and also initialize a .env file for environment variables.
You can also directly specify the database you want to use when setting up the Prisma ORM with the Prisma CLI’s init command:
npx prisma init --datasource-provider mysql
This will create a new Prisma directory with your schema.prisma file like the previous command and configure MYSQL as your database. With this, you can model your data and create your database with some tables.
Next, create a model that will represent the tables in your database and also serve as the foundation for the generated Prisma Client API:
//schema.prisma.ts
model User {
id Int @id @default(autoincrement())
name String
}
Then run the command below:
npx prisma migrate dev -name migrationName
This will execute SQLite migration file against the database you provided and create a new SQLite migration file for this migration in the prisma/migrations directory. When you reload your SQLite database, you’ll see that you now have a table called Users that you can interact with:
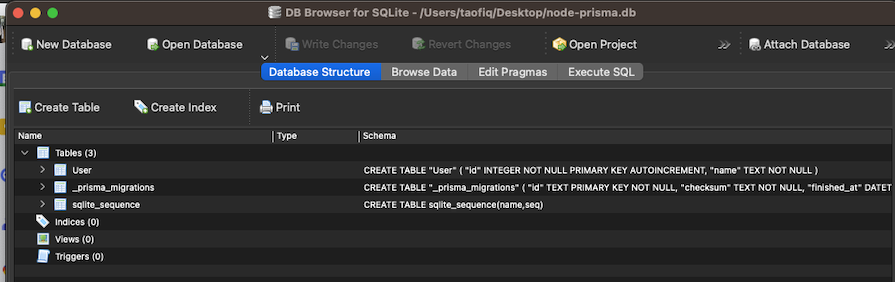
As an important note, always remember to include your DATABASE_URL in your .env value, whether you’re using MongoDB, SQLite, MySQL or any other database.
Next, let’s try to write to our database by creating a new user in our database. Create a new file called index.ts in the root directory of your project:
// index.ts
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
async function main() {
const user = await prisma.user.create({
data: {
name: "Alice",
},
});
console.log(user);
}
main()
.then(async () => {
await prisma.$disconnect();
})
.catch(async (e) => {
console.error(e);
await prisma.$disconnect();
process.exit(1);
});
This piece of code has a function named main that gets called at the end of the script. The PrismaClient is instantiated, which represents the query interface of your database. Inside the main function, there is a query to create a new User record in the database using the create method on the PrismaClient instance.
Run this command to execute the script:
npx ts-node index.ts
In the console, we have this logged:
![]()
Then, we can check if the user record is saved inside our database:
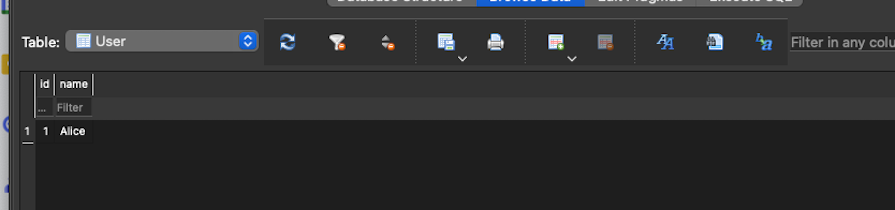
Now, you can go on to perform other database operations like getting all users, getting one user, or editing and deleting users using the query interface of the PrismaClient instance.
Now that we’ve discussed why you should use Prisma and explored some quick getting-started steps, let’s dive into some of Prisma’s standout features. This will help us learn more about what sets this tool apart and makes it such a great choice for frontend projects.
Prisma Client is an auto-generated and type-safe query builder that is tailored to your data and provides a more convenient way to interact with databases. This feature means you don’t need to write raw SQL queries manually, which simplifies database interactions and improves the frontend development process.
To set up Prisma Client in your project, you need to generate a Prisma schema file with your database connection, the Prisma Client Generator, and a model. For example:
datasource db {
url = env("DATABASE_URL")
provider = "sqlite"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
name String?
}
This defines the structure of our database, specifying that we’re using sqlite as our database and prisma-client-js as our provider. Lastly, we define a simple model that defines a database table in our SQLite database called User. It also specifies the columns that this table has.
To start using Prisma Client to query your database, you have to import the PrismaClient API in your client-side app:
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
Here, we instantiate a new instance of the PrismaClient class provided by the Prisma Client library. This creates a connection to the database and initializes the Prisma Client API, allowing you to make queries to your database.
Let’s say we have a CRUD application where we want to create new users. We can do so like this with Prisma:
const createUser = async (username, email) => {
try {
const newUser = await prisma.user.create({
data: {
username,
email,
},
});
return newUser;
} catch (error) {
console.error("Error creating user");
}
};
Here, we use the instance of Prisma Client to interact with our database. We create a user using the username and email payload sent to us from the client side using the create method. Then, we save the user to the database:
const getUsers = async () => {
try {
const users = await prisma.user.findMany();
return users;
} catch (error) {
console.error("Error getting users");
}
};
This block of code uses the instantiated Prisma Client to retrieve the list of users from the database using the findMany method. This returns an array of users to us from the database.
The Prisma schema serves as the base configuration file for your Prisma setup. In other words, it serves as the base of building and structuring your database models, relationships and constraints.
The Prisma schema file is usually called schema.prisma and basically comprises three main parts: generators, data sources, and the data model. Let’s start with generators.
Generators determine what the client should be generating based on the data model. They basically determine which assets will be created when you run the prisma generate command. The generator field accepts:
provider: This field is required and defines which Prisma Client should be used. At the moment, only prisma-client-js is available as the provideroutput: This optional field determines the location for the generated clientPreviewFeatures: This optional field uses IntelliSense to see the latest available Preview featuresEngineType: This field defines the query engine type for download and use.Here’s an example of how to write a generator:
generator client {
provider = "prisma-client-js"
}
Next, data sources specify the details of the data sources that Prisma should connect to. For example, if you specify your data source as sqlite, then Prisma will source and interact with data from the SQLite DATABASE_URL that you provide:
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
Finally, the data model defines how your application models and their relations should look:
model User {
id String @id @default(uuid())
name String?
}
Here, we specify our data model and name it User. A model in Prisma basically represents a table (relational database) or a collection (non-relational database). This model has two fields that will be created when the initial migration is run. We’ll discuss this more later.
Prisma Migrate helps automate the process of managing changes in your codebase’s database schema. It generates a history of the migration file and allows you to keep your database schema in sync with your Prisma schema as it changes during development and production.
Without Prisma, developers would have to manually write their SQL scripts to perform migrations. Prisma Migrate makes the process of managing database schema changes more streamlined and developer-friendly.
To get started with Prisma Migrate, you once again need to create your Prisma schema first:
schema.prisma
datasource db {
url = env("DATABASE_URL")
provider = "sqlite"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
name String?
}
Next, we will, run the migration command to create our first migration:
npx prisma migrate dev -name init
Once done, we should see a success message like this in the terminal:
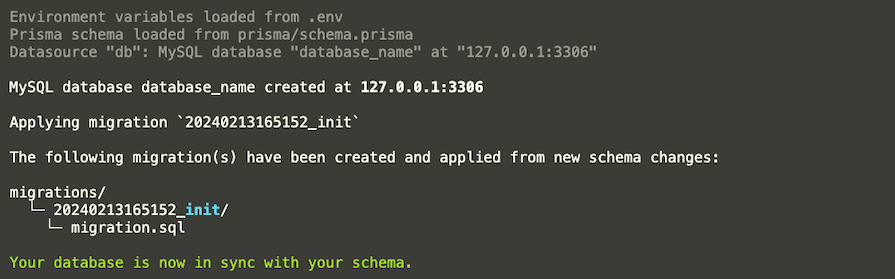
Now, your Prisma schema is in sync with your database schema. You should also now see a migration history, as shown in the image above.
Note that you must replace the value of the env("DATABASE_URL") field with your actual database url in the .env file.
Let’s say we have this schema defined for our application and we decide to make a change to the predefined model to add a new field called address. Remember that the model currently creates a table called User in our SQLite database. Now, let’s add the address field to the schema:
datasource db {
url = env("DATABASE_URL")
provider = "sqlite"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
name String?
address String?
}
Next, since we added a new address field, let’s create our second migration:
npx prisma migrate dev --name add_address_field
You will be prompted to add a name for your migration:

Enter the migration name and press Enter. You should see a success message once the migration is successful:
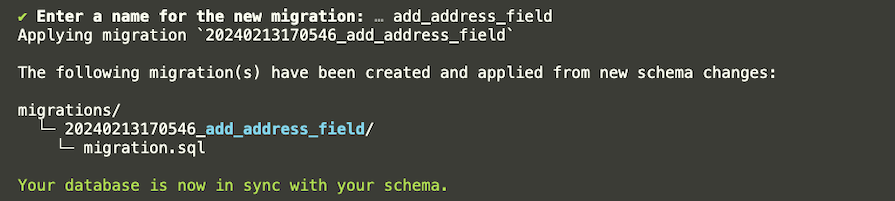
Now, you should have a new migration history. You can have control over and deploy the changes. This is how Prisma streamlines database migrations and makes the process less complex.
The Prisma model represents a table in your database and serves as the baseline for your data while providing a strongly typed schema for your application. Models define the structure of the data by specifying:
They also form the foundation of the queries available in the generated Prisma Client API.
Let’s take example of a platform with some users and posts to illustrate better how models work:
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String
name String?
posts Post[]
@@map("users")
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
userId Int
user User @relation(fields: [userId], references: [id])
@@map("posts")
}
Here, we predefined two related models.
The User model represents a user in the system and has an id that serves as its primary key, along with email, name, and post fields that set up a one-to-many relationship with the Post model. The @map attribute specifies the table name in the database when it is created.
The Post model represents a post created by one single user. It has id, title, content, and userId fields that serve as our foreign keys — in this instance, to reference or establish the relationship between a user and their posts. The @relation attribute specifically states the relationship, indicating the fields that are used to connect the models.
Introspection is mostly used to generate the initial version of the data model when adding Prisma to an existing project. The key function of introspection is to populate the Prisma schema with a data model that reflects the current database schema.
One relevant and practical use case for Prisma is building a server-side application that interacts with a database. It’s great for developing web apps with frequent database interactions. For example, for a simple web app that performs CRUD operations on the server side, Prisma helps simplify these operations while ensuring type safety.
Prisma is also useful during API development. With Prisma, you can streamline database operations such as data fetching and mutations when developing API endpoints, whether you’re building RESTful or GraphQL APIs.
Thirdly, Prisma is a very good option if you are looking to abstract away complex conventional database queries and workflows. This allows you and other developers on your team to focus more on other business logic and aspects of development, thus improving productivity.
As previously mentioned, Prisma covers much of the database workflows that developers need when interacting with databases. Examples include database querying with Prisma Client, data modeling using the Prisma schema, migrations with Prisma Migrate, seeding using the command prisma db seed, and many other workflows.
However, Prisma might not be a good use case if you want full control over your database queries, as it abstracts low-level database queries away. For example, if you want to work with raw or plain SQL queries, Prisma Client — which is for database querying — will be less effective in this scenario.
One of the main reasons behind creating the Prisma ORM was to make life easier for developers when interacting with or querying databases while providing a clean and type-safe API for submitting or working with these queries. This gives Prisma an edge over plain SQL and SQL query builders in several significant ways.
Before Prisma, the database tools that existed in the Node and TypeScript ecosystem required developers to make a hard choice between productivity and abstraction or control.
Some developers would have to work with lower-level database drivers and query builders to have more control over their database queries, transactions, and optimizations.
Meanwhile, choosing productivity would mean using ORMs with higher levels of abstraction that provided features such as migrations, auto query generation, type safety, data modeling, and more.
Prisma provides modern ORM for Node.js and TypeScript while offering out-of-the-box features like schema migrations, type-safe database access, seeding, and query builders that provide effective SQL queries.
Working with plain SQL gives developers more control and access over the queries. However, writing raw SQL queries can be time-consuming and not fully type-safe. SQL query builders are abstracted just like Prisma for database interactions, but usually lack features such as type safety and schema migrations.
Prisma performance is deeply rooted in its high-level abstraction of database queries and interactions while providing type-safe queries. It allows developers to carry out data fetching by generating SQL based queries from the Prisma schema.
Its excellent performance can also be seen in the way it handles database query optimizations by minimizing the number of separate queries made to the database, especially for relational databases.
Performance with plain SQL generally depends on the developer writing the queries, since plain SQL provides more control for database interactions. A well-optimized SQL query can yield good performance, but these can take time, effort, and some trial and error to write — and a poorly optimized query can impact performance.
Meanwhile, like Prisma, SQL query builders such as Knex or Sequelize allow developers to build their queries using their interface giving them more control over query building. These query builders might not be as efficient as Prisma, since developers still need to ensure their queries are properly optimized for performance.
Prisma offers very comprehensive documentation. The documentation covers everything from the basics of what Prisma is and why it was created to installation, getting started guides and video tutorials, advanced topics, and API references.
With Plain SQL, developers mostly have to use database and SQL documentation as they seek to build their queries from scratch. Popular query builders like Knex and Sequelize also have very good and solid documentation that make the learning curve for developers much easier.
Prisma has a large and ever-evolving community of developers and guest contributors. It also has an active GitHub repository where developers can raise issues regarding the Prisma toolkit and submit merge requests for fixes and new features. There are also Discord and Slack channels for community questions and suggestions.
With plain SQL, developers often need to rely on forums like Stack Overflow or online communities like Reddit. Meanwhile, just like Prisma, SQL query builders typically have their own developer communities with channels for communications and learning purposes.
You can use the comparison table below to quickly review the information we covered above:
| Features | Prisma | Plain SQL | SQL query builders |
|---|---|---|---|
| Abstraction level | High abstraction | Low abstraction — i.e., direct queries | Varies between tools, but typically neither as abstracted as ORMs like Prisma, nor as direct as SQL |
| Features | Schema migrations, type safety, database seeding | Direct database features | Migrations, query building; lack some ORM features |
| Type Safety | Has strong type safety, integrated with TypeScript | Depends on the developer’s implementation | Varies between tools; some have type safety out of the box while others don’t |
| Performance | Good performance optimization at its core handled by Prisma | Can be better, as developers can optimize their queries directly | Good performance, but reliant on developer optimizations |
| Documentation | Comprehensive and detailed docs, video guides, and API reference examples | Depends on the database connection | Detailed docs and guides with well-structured API reference examples |
| Community | Wide and growing community with active contributions | Relies on database communities | Active and engaged communities for developer interaction |
Hopefully, this comparison table will help you better assess and select a tool that works for your needs.
Prisma ORM is a next-generation, database-agnostic Node.js and TypeScript ORM that provides developers with an easier, more streamlined workflow when working with databases. It offers features such as automated migrations, type safety, developer experience, and auto-completion.
As discussed earlier, Prisma’s performance is great while also offering optimized database access and management. It also improves the developer experience through its comprehensive documentation, guides, and great community and ecosystem.
A potential drawback with Prisma is that the learning curve can be steep for developers coming from writing plain SQL queries or using SQL query builders. However, these alternatives typically don’t provide the features and ease of use that Prisma does.
Keep in mind that Prisma might not be a good fit for projects that rely heavily on SQL queries or require more database control. However, its powerful features — including type safety, ease of integration, database access and management, DX, and more — give it an edge over plain SQL, SQL query builders, or other ORMs.
Prisma also offers a number of other features, like Prisma Client and Prisma Migrate, that make it highly suitable for modern web development. I encourage you to try Prisma out and experience its great features and DX for yourself. If you have any questions, feel free to comment below.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how AI-assisted development governance uses rules, agents, hooks, and protocols to help AI coding tools produce safer, more consistent code.

A step-by-step guide to building your first MCP server using Node.js, covering core concepts, tool design, and upgrading from file storage to MySQL.

Using security headers in your Next.js apps is a highly effective way to secure websites from common security threats.

A deep dive into May 2026’s AI model and tool rankings. We break down performance, usability, pricing, and real-world capabilities across 50+ features to help you pick the right tools for your development workflow.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

