I find cycle time one of the most underrated metrics for product managers to track. Improving cycle time leads to smoother delivery, better efficiency, faster learning, and in the long run, a better product.

Although some could argue that tracking smooth delivery is a team’s or project manager’s responsibility, the reality is that in many companies, the product manager wears both the product and delivery hats.
Cycle time is the amount of time that elapses between starting work on an item and completing it.
Cycle time is one of the primary speed measures — and speed is good. Reducing cycle time leads to:
Moreover, I find cycle time to be the most holistic delivery metric to track. Achieving low cycle times requires us to follow best practices such as:
In short, low cycle time is often the result of a healthy delivery process.
Below are some of the highest-leverage tactics to reduce cycle time I’ve discovered over the last few years working with various teams.
Automation is key. If a computer can do something, humans shouldn’t have to.
CI/CD pipeline is a cornerstone of reducing the cycle time. You don’t want to spend time doing integration work if it can be done for you.
The same goes for E2E test automation. If you have to wait a few days for every release because QAs are doing the whole regression manually, you are doing it wrong.
As a rule of thumb, the more automated the delivery process is, the better.
If your product is past the initial MVP phase, it’s probably time to start building a design system and reusable components.
You don’t want your developers to code the same button from scratch every time. Building new pages from components is like using Lego blocks. Everything is already there. All you need is to connect them correctly to build the desired figure.
Start small. Give your designers time to prepare well-documented components for the most commonly used interface elements. Then, give your developers space to build up a components repository.
It will slow you down in the short run but will pay off greatly in the long run.
Whether it’s waiting for reviews, fixing comments, or getting approvals, code review (CR) might be a significant time-waster. However, implementing minor improvements here might yield great results.
To better understand how one can improve the CR process, let’s break it down into its elements:
Code review time = Time to first review + Time to approval + Time to merge
Time to first review indicates how long it takes from a person opening a pull request (PR) to the first person reviewing it.
While you don’t want people to drop everything and jump into review mode every time there’s a new PR, a long time to first review means more multitasking on the author’s side.
The healthy time to first review should be in hours, not days.
One tactic that worked well in my teams was creating two to three code review slots during the day. I asked the teams to check the repository and tackle any code review processes at least at the start of the day and after the lunch break.
It caps the time to first review time to about four working hours.
Time to approval measures the time from the first review to getting all required approvals. Things that impact this metric include:
The number of comments is usually high when the team is getting up to speed and learning how to code together, but it should be minimized over time. The request size is the most significant factor here. If there are 50 comments in a PR, it’s probably an unhealthy big PR.
The time to resolve the comments shows the intensity of the team’s work on a given PR. Once again, you don’t want people to drop everything just because there’s an open PR, but closing PRs in progress should be a priority over creating new pull requests.
The number of approvals needed impacts both the code review time as well as its time consumption. While there’s no silver bullet, you should ensure this number is relevant to your goals.
If you are launching an MVP, four approvals might be an overkill. If you are a mature team with plenty of juniors joining recently, one approval might not be enough to maintain code quality.
Time to merge tells us how much time elapses from the last approval to merging the code and closing the pull request. Ideally, it should be close to zero.
A healthy CI/CD pipeline should handle it for the team.
Focus on making your testing process as quick as possible while maintaining quality standards. Some of the tactics include:
Testing shouldn’t be the very last step in the process. The later you find an issue, the more time-consuming it is to be solved. The sooner you engage a QA specialist, the better.
Having a QA specialist review specifications and design before starting development might save you a lot of headaches.
Although a QA engineer is the quality expert in the team, it doesn’t mean that only they are responsible for increment quality. Implement the quality assurance process for the whole team.
Engineers should double-check and self-test their work before handing it off to a QA specialist. Otherwise, the chance of finding late bugs increases dramatically.
It’s highly improbable that all work items will have the same cycle time. Look out for outliers, especially those that took significantly longer than the median cycle time:
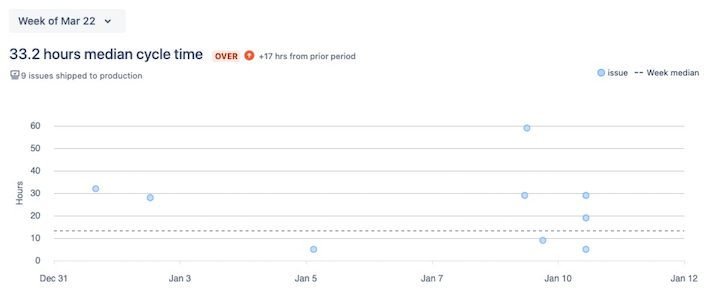
Investigate these outliers and discover why they took so long. Were these outliers too big? Did the CR or QA take too long? Is it due to technical debt? Then focus on addressing these issues.
You can learn a lot about your process efficiency by thoroughly reviewing outliers.
I treat technical debt as a gap between the state of technical excellence and the current state. It can result either from oversight or a conscious tradeoff. Examples include:
In the long run, the higher the tech debt levels, the higher the cycle time:
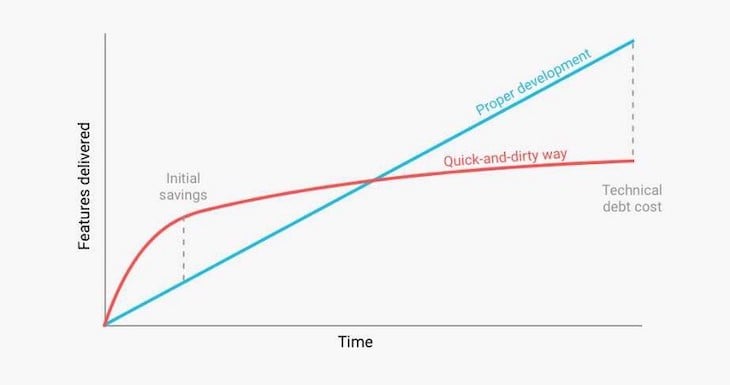
One tactic I like is discussing tech debt on a regular cadence (e.g., monthly risk assessment meetings).
It’s also beneficial to have guidelines for taking and reporting the debt.
For example, whenever we take shortcuts or notice gaps, I ask the team to report a special tech debt ticket with a guardrail rule that the total backlog of tech debt tickets can’t be bigger than 200 percent of the average sprint velocity (the number varies, depending on circumstances).
While there’s no perfect answer to how much tech debt is acceptable, it’s critical to consciously monitor and manage tech debt levels. High levels of debt can significantly slow you down.
Make sure your work items are as small as they are feasible. The bigger the task, the longer it will take and the more process and product risk it will bring.
Although not every PBI can be split into smaller ones, most of them can.
My favorite tactic for reducing item size is slowly capping the maximum number of story points per ticket.
Say, if most of my team’s tickets are 1, 2, 3, 5, 8, 13, and 21 story points, the first step would be to aim to eliminate 21 story points tickets from further sprints. Then, whenever we have 21 story point ticket, we do whatever we can to break it down.
Once we master it, we switch our focus to 13 story points tickets, and so on, until we are satisfied with the size of our work items.
Give it a try. It’s often easier than it sounds.
Cycle time is a critical metric that is worth experimenting on in a similar manner as you would experiment with the product.
Dig around, set hypotheses, plan experiments and see how the metric changes. The results might surprise you.
For example, I ran one experiment with the team to implement a slack bot reminder to catch up on PRs twice a day.
After running the experiment, the team said they were annoyed by the bot’s constant reminders and recommended that we kill it. But they changed their opinions when they saw that our total CR time had dropped by roughly 40 percent since implementing the bot.
Small changes can yield surprising results, so keep experimenting and measuring the outcomes.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.
Learn how product managers can use human-in-the-loop AI to manage decision risk, set oversight, and keep ownership and accountability human.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.


