If you have used Express.js, the Node.js web application framework, then you are aware of the concept of middleware. An Express application is essentially a series of middleware function calls, where middleware functions can run any code, modify the request and response objects, terminate the execution, and pass execution to the next middleware function in the stack.

The code below demonstrates a middleware function, which receives the request object req, the response object res, and the next middleware function in the application’s request-response cycle, next:
var express = require('express')
var app = express()
// Middleware function which prints the requested URL and calls the next function
app.use(function (req, res, next) {
console.log('Request URL:', req.originalUrl)
next()
})
Middleware helps to organize the codebase efficiently, splitting the logic into chunks that handle a single task and that can be reused in the same project for different requests (and also across projects through libraries), leading to code modularity and a clear separation of concerns.
Its main use case is the implementation of those functionalities cross-cutting the application, such as:
Several GraphQL servers have incorporated the concept of middleware, to be applied at the field resolver level. Middleware enables us to resolve the field through a series of simple resolver functions, in contrast to applying a single resolver function which executes plenty of business logic.
Being based in Express, graphql-yoga supports field resolver middleware out of the box, implemented through the graphql-middleware package.
In the code below, the field hello is implemented with this resolver:
const typeDefs = `
type Query {
hello(name: String): String
}
`
const resolvers = {
Query: {
hello: (root, args, context, info) => {
console.log(`3. resolver: hello`)
return `Hello ${args.name ? args.name : 'world'}!`
},
},
}
The resolver can be augmented with middleware functions, which execute arbitrary logic before and/or after the resolution of the field:
const { GraphQLServer } = require('graphql-yoga')
const logInput = async (resolve, root, args, context, info) => {
console.log(`1. logInput: ${JSON.stringify(args)}`)
const result = await resolve(root, args, context, info)
console.log(`5. logInput`)
return result
}
const logResult = async (resolve, root, args, context, info) => {
console.log(`2. logResult`)
const result = await resolve(root, args, context, info)
console.log(`4. logResult: ${JSON.stringify(result)}`)
return result
}
const server = new GraphQLServer({
typeDefs,
resolvers,
middlewares: [logInput, logResult],
})
server.start(() => console.log('Server is running on http://localhost:4000'))
Now, resolving the query { hello(name: "Bob") } produces a flow that has the shape of an onion:
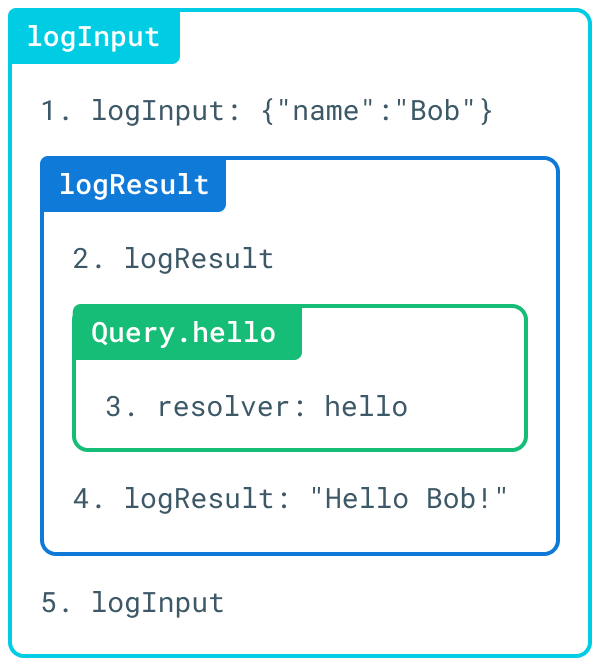
The Scala-based GraphQL server Sangria also supports middleware out of the box, providing functions beforeField and afterField to execute arbitrary code before and after the resolution of the field:
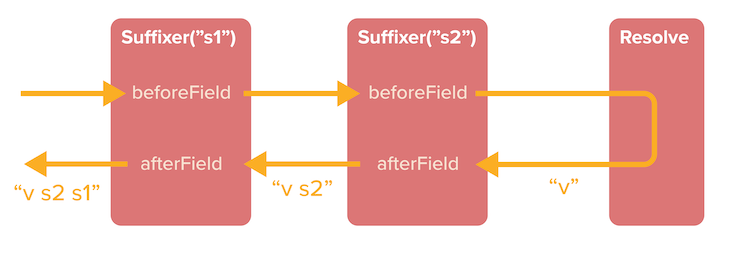
Other GraphQL servers that provide support for middleware include GraphQL .NET, Hot Chocolate, Ariadne, and Lighthouse.
Middleware functions as described in the section above are used for augmenting the resolution of fields. Yet GraphQL already has a feature that satisfies this same functionality: directives. Since they attain the same objective, it’s only natural to ask: Why is middleware needed at all? Why not use directives instead?
graphql-middleware answers:
GraphQL Middleware and directives tackle the same problem in a completely different way. GraphQL Middleware allows you to implement all your middleware logic in your code, whereas directives encourage you to mix schema with your functionality.
This response prompts another question: Since middleware as a design pattern naturally satisfies the functionality that directives are expected to satisfy, then wouldn’t the GraphQL server benefit from implementing directives as middleware?
That is to say, with a query like this one:
query {
field @directive1 @directive2
}
Would it make sense to have directives @directive1 and @directive2 be middleware, receiving the value of the resolved field, executing their arbitrary logic, and passing the result to the next directive down the line?
Let’s find out.
In general terms, the middleware execution flow looks like this:

Now, this execution flow is not completely suitable for executing directives because directives are executed in their established order from left to right. Thus, we can’t have a @directive1 update the field value after @directive2 is executed, as could be done after the U-turn.
As such, directive execution cannot be directly implemented as middleware. Instead of being a U-turn, what is required is a one-way execution flow, like this:

The design pattern that satisfies this execution flow is known as the chain-of-responsibility pattern:
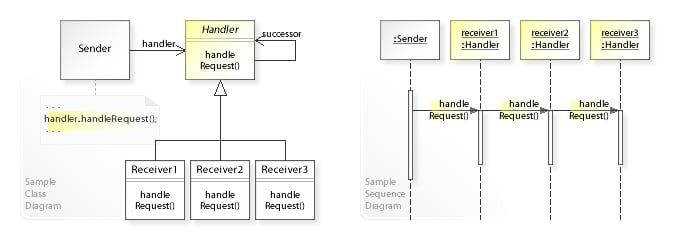
The corresponding structure, called a pipeline, can be easily adapted for executing directives:
It looks like this:

This design is simpler than middleware, and it can attain the same results: if @directive1 needs to execute some logic on the way back (the afterField logic), we can instead perform this logic through @directive3 placed at the end of the field:
query {
field @directive1 @directive2 @directive3
}
Middleware allows us to terminate the process at any moment, and this can also be attained through a pipeline.
Termination at some middle stage makes sense in some cases, as when a directive @validate indicates that some validation has failed, and the query must not be executed. This logic can be achieved by passing a Boolean flag skipExecution between stages in the pipeline, which is checked by each directive before running its logic, and can be set to true by any directive at any stage.
In conclusion, using a pipeline is more suitable for executing GraphQL directives than using middleware. Next, let’s architect the pipeline to make the most of GraphQL.
In my previous article GraphQL directives are underrated, I declared that, due to the potentially unbounded power of directives, GraphQL servers with good support for custom directives are the ones that will lead GraphQL into the future.
Motivated by this philosophy, for Gato GraphQL (my own GraphQL server in PHP), I decided to have the query resolution process placed right on top of the directive pipeline. As such, the directive can be considered a low-level component, giving the developer the power to manipulate the GraphQL server’s response as needed.
Let’s see how this architecture works, and why it is powerful.
Initially, we consider having the GraphQL server resolve the field through some mechanism and then pass this value as input to the directive pipeline.
However, it is much simpler to have a single mechanism to tackle everything: invoking the field resolvers (to both validate fields and resolve fields) can already be done through the directive pipeline. In this case, the directive pipeline is the single mechanism used to resolve the query.
For this reason, the GraphQL server is provided two special directives:
@validate calls the field resolver to validate that the field can be resolved (e.g., the syntax is correct, the field exists, etc.)@resolveValueAndMerge then calls the field resolver to resolve the field and merges the value into the response objectThese two are of the special “system-type” directives: they are reserved for the GraphQL engine only, and they are implicit on every field. In contrast, standard directives are explicit: they are added to the query by the user.
By using these two directives, this query:
query {
field1
field2 @directiveA
}
Will be resolved as this one:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}
The pipeline now looks like this (please note that the pipeline receives the field as input, and not its initial resolved value):

Directives are normally executed after @resolveValueAndMerge since they most likely involve updating the value of the resolved field. However, there are other directives that must be executed before @validate, or between @validate and @resolveValueAndMerge.
For instance:
@traceExecutionTime can obtain the current time before and after the field is resolved by placing the subdirectives @startTracingExecutionTime at the beginning and @endTracingExecutionTime at the end of the pipeline@cache must check whether a requested field is cached and return this response before executing @resolveValueAndMergeThe pipeline will then offer three different slots, and the directive will indicate in which one it must be executed:
"beginning" slot – before the validation takes place"middle" slot – after the validation and before the field resolution"end" slot – after the field resolutionThe directive pipeline now looks like this:

Please note how directives @skip and @include can be so easily satisfied given this architecture: placed in the "middle" slot, they can inform directive @resolveValueAndMerge (along with all directives in later stages in the pipeline) to not execute by setting flag skipExecution to true.
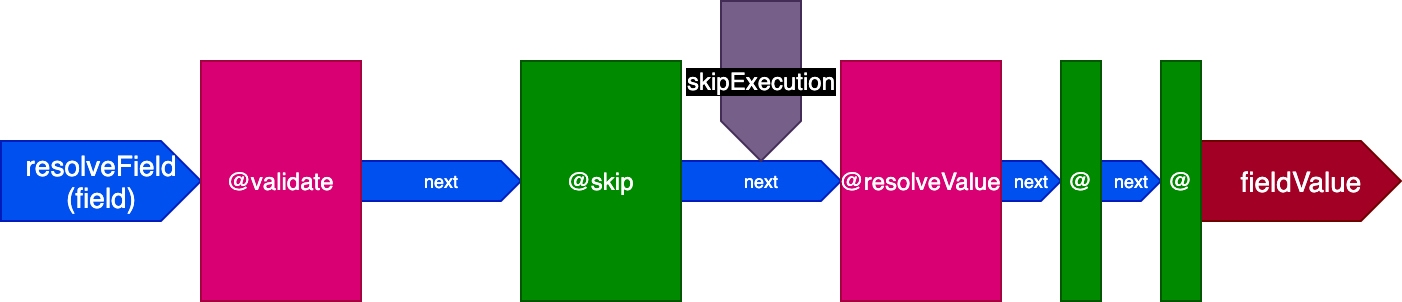
Until now, we have considered a single field being input to the directive pipeline. However, in a typical GraphQL query, we will receive several fields on which to execute directives. For instance, in the query below, directive @upperCase is executed on fields "field1" and "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}
Moreover, since the GraphQL engine adds system directives @validate and @resolveValueAndMerge to every field in the query, this query:
query {
field1
field2
field3
}
Is resolved as this query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}
Then, the system directives will always receive all the fields as inputs.
As a consequence, we can architect the directive pipeline to receive multiple fields as input, and not just one at a time.
This architecture is more efficient because executing a directive only once for all fields is faster than executing it once per field, and it will produce the same results. For instance, when validating if the user is logged in to grant access to the schema, the operation can be executed only once. Running the following code:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}
Is more efficient than running this code:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}
This may not seem like a big deal when calling a local function such as isUserLoggedIn, but it can make a big difference when interacting with external services, such as resolving REST endpoints through GraphQL. In these cases, executing a function once instead of multiple times could make the difference between being able to provide a certain functionality or not.
Let’s see an example. When interacting with Google Translate through a @translate directive, the GraphQL API must establish a connection over the network. Then, executing this code will be as fast as it can ever be:
googleTranslateFields([$field1, $field2, $field3]);
In contrast, executing the function separately — multiple times — will produce a higher latency that will result in a higher response time, degrading the performance of the API. This may not be a big difference for translating three strings (where the field is the string to be translated), but for 100 or more strings it will certainly have an impact:
googleTranslateField($field1); googleTranslateField($field2); googleTranslateField($field3);
Additionally, executing a function once with all inputs may produce a better response than executing the function on each field independently. Using Google Translate again as example, the translation will be more precise the more data we provide to the service.
For instance, when execute the code below:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");
For the first independent execution, Google doesn’t know the context for "fork", so it may well reply with fork as a utensil for eating, as a road branching out, or as another meaning. However, if we execute instead:
googleTranslate(["fork", "road", "sign"]);
From this broader amount of information, Google can deduce that "fork" refers to the branching of a road and return a precise translation.
It is for these reasons that the directives in the pipeline should receive the input fields all together, and then each directive can decide the best way to run its logic on these inputs — a single execution per input, a single execution comprising all inputs, or anything in between. The pipeline now looks like this:

Just now, we learned that it makes sense to execute multiple fields per directive — this works well as long as all fields have the same directives applied on them. When the directives are different, it can lead to greater complexity, which makes its implementation difficult and would diminish some of the gained benefits.
Let’s see how this happens. Consider the following query:
query {
field1 @directiveA
field2
field3
}
The directive above is equivalent to this one:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}
In this scenario, fields field2 and field3 have the same set of directives, and field1 has a different one. We would then have to generate two different pipelines to resolve the query:
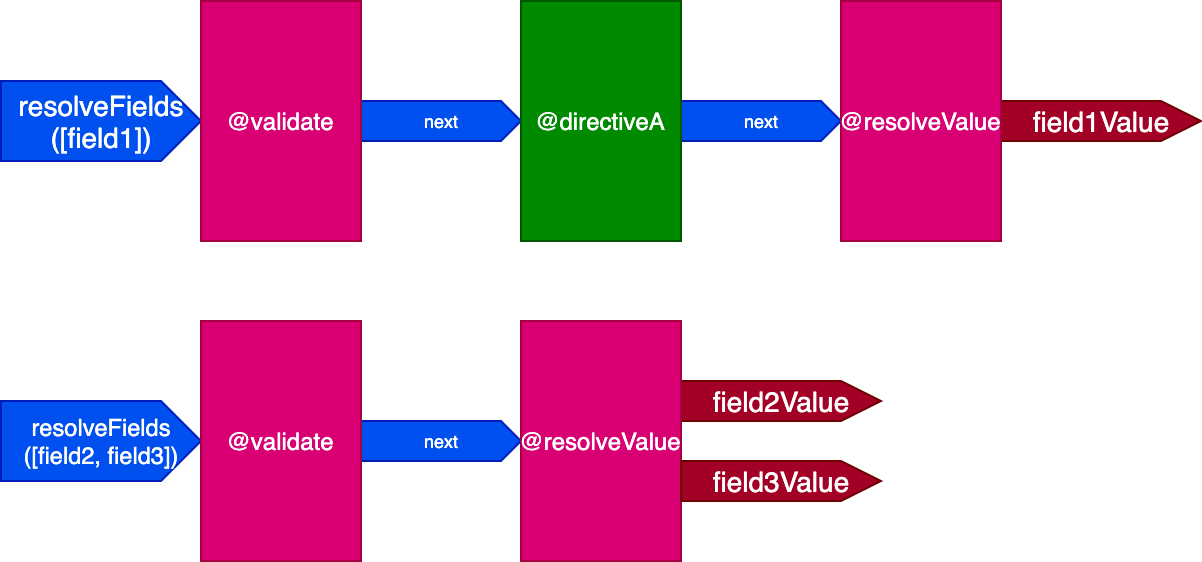
And when all fields have a unique set of directives, the effect is more pronounced. Consider this query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}
Which is equivalent to this:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}
In this situation, we will have three pipelines to handle three fields, like so:
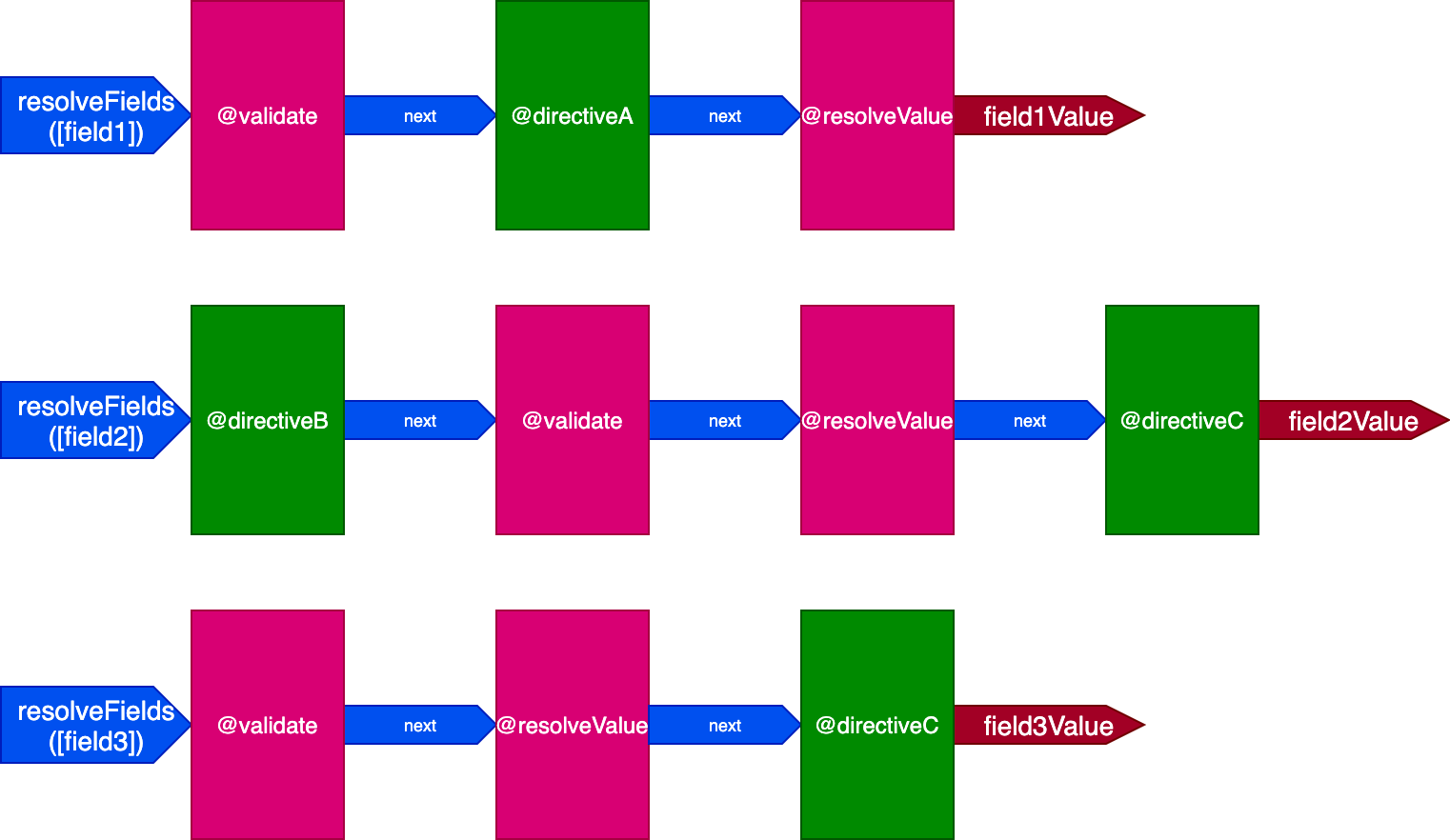
In this case, even though directives @validate and @resolveValueAndMerge are applied on the three fields, they will be executed independently of each other because they are executed through three different directive pipelines — which takes us back to having a directive being executed on a single item at a time.
The solution to this problem is to avoid producing multiple pipelines and instead deal with a single pipeline for all the fields. As a consequence, we can’t pass the fields as input to the pipeline any longer since not all directives from a single pipeline will interact with the same set of fields; rather, every directive must receive its own list of fields as its own input.
Then, for this query:
query {
field1 @directiveA
field2
field3
}
The directives @validate and @resolveValueAndMerge will get all three fields as inputs, and directiveA will only get "field1":
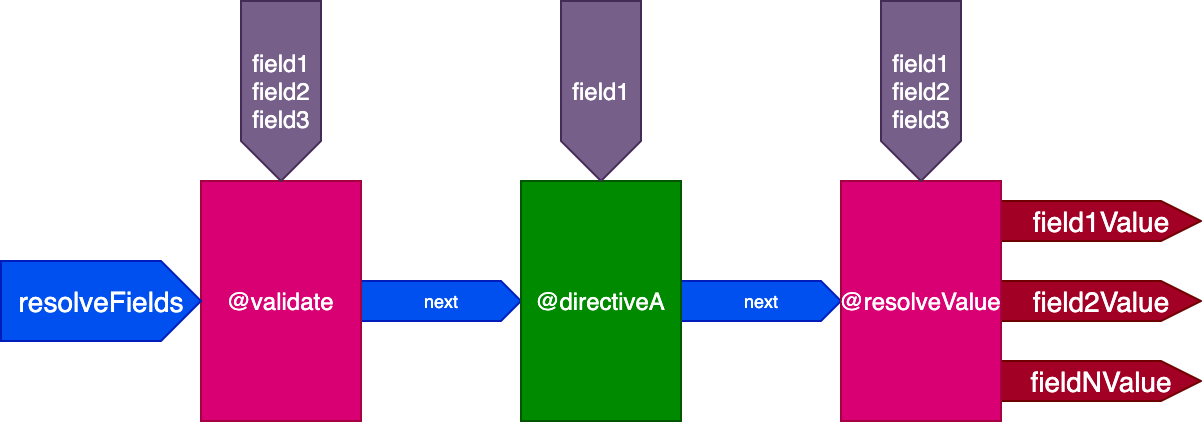
And for this query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}
The directives @validate and @resolveValueAndMerge will get all three fields as inputs; directiveA will only get "field1"; directiveB will only get "field2"; and directiveC will get "field2" and "field3":
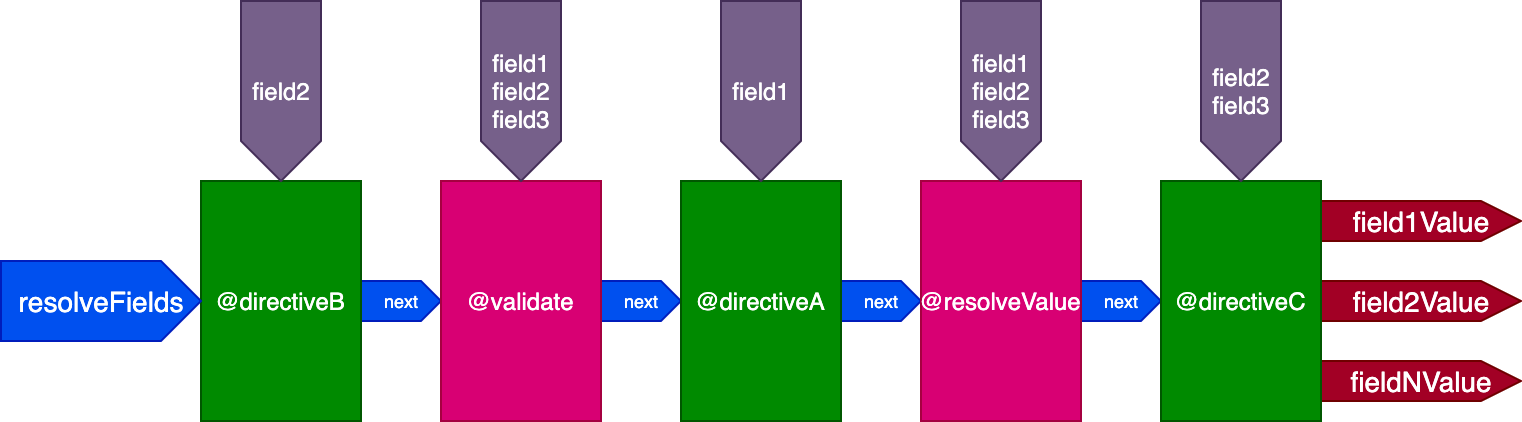
Until now, a directive at some stage could influence the execution of directives at later stages through the flag skipExecution. However, this flag is not granular enough for all cases.
For instance, consider a @cache directive, which is placed in the "end" slot to store the field value so that next time the field is queried, its value can be retrieved from the cache through a directive @getCache placed in the "middle" slot:
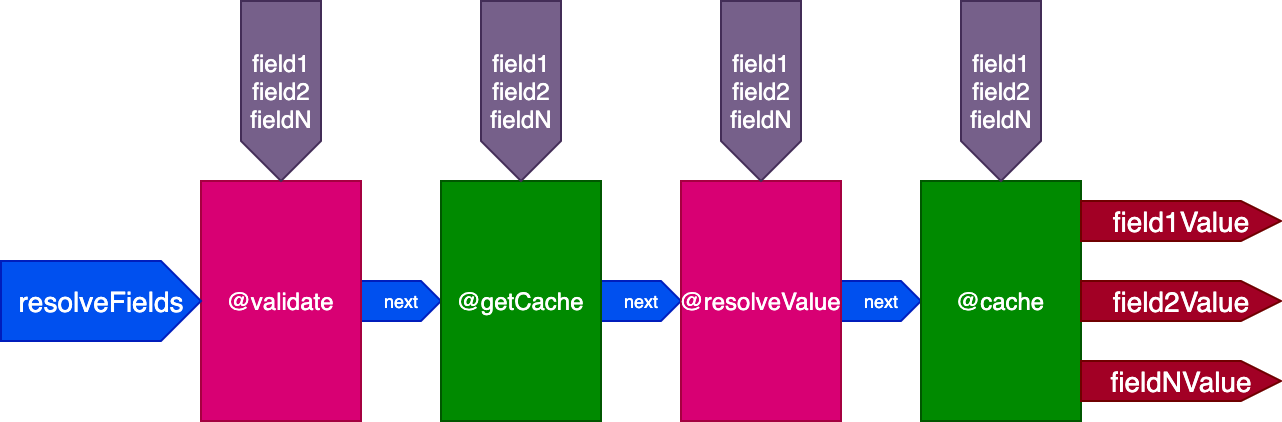
N.B.: Similar to system directives,
@getCacheis implicit, automatically added by@cache, so it must not be added to the query. More on this later on.
When executing this query:
{
posts(limit: 2) {
title @translate @cache
}
}
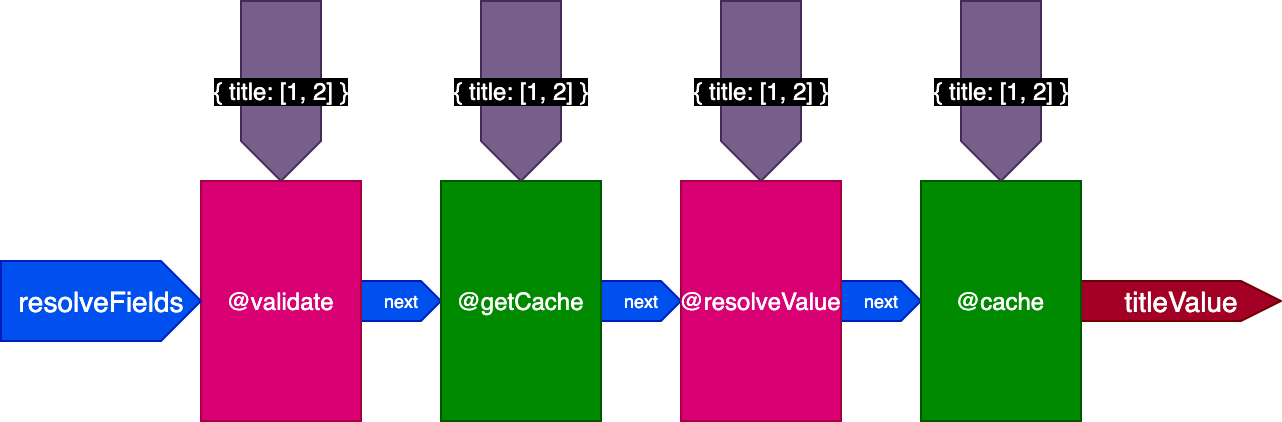
The server will retrieve and cache two records. Then, we execute the same query, but applied to four records:
{
posts(limit: 4) {
title @translate @cache
}
}
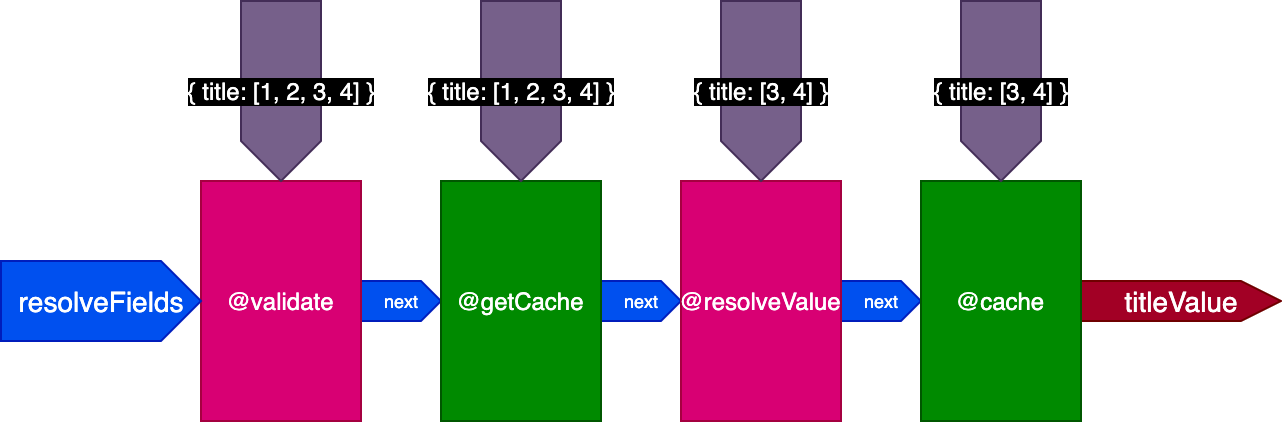
When executing this second query, the two records from the first query were already cached, but the other two records were not. However, we would need all four records to have been cached already in order to use flag skipExecution. It would be better if we could retrieve the first two records from the cache and resolve only the two other records.
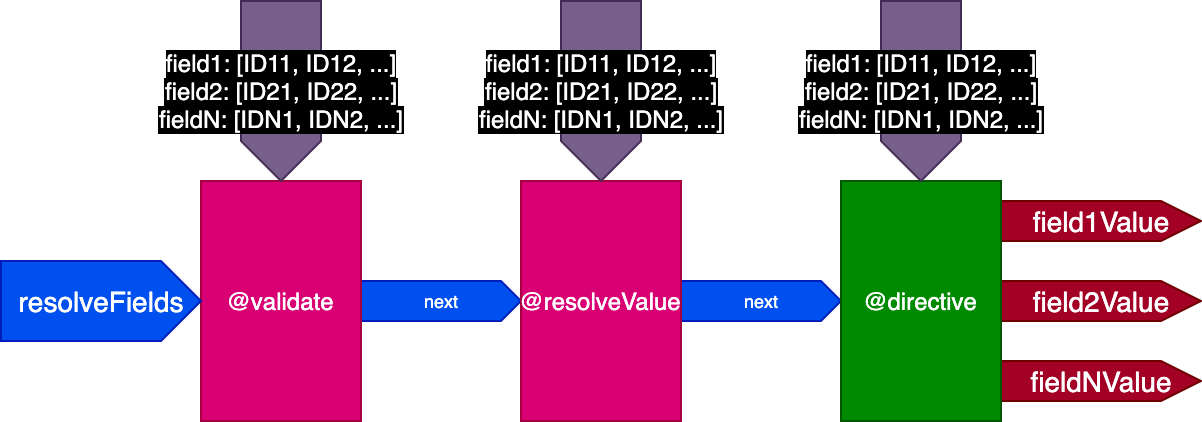
So we update the design of the pipeline again. We dump the skipExecution flag and instead pass to each directive the list of object IDs per field where the directive must be applied through a fieldIDs object input:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}
The variable fieldIDs is unique to each directive, and every directive can modify the instance of fieldIDs for all directives at later stages. Then, skipExecution can be done granularly on an ID-by-ID basis, by simply removing the ID from fieldIDs for all upcoming directives in the stack.
The pipeline now looks like this:
Applied to the previous example, when executing the first query translating two records, the pipeline looks like this:
When executing the second query translating four records, directive @getCache gets the IDs for all four records, but both @resolveValueAndMerge and @cache will only receive the IDs for the last two records only (which are not cached):
This is the final design of the directive pipeline:
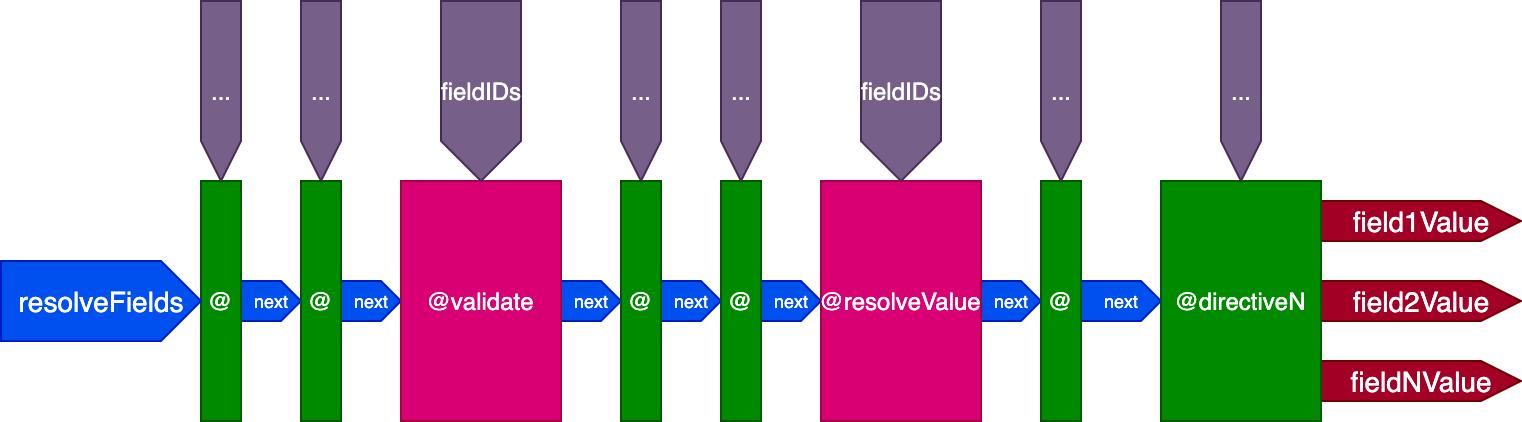
In sum, these are its characteristics:
@validate and @resolveValueAndMerge"beginning", before @validate; "middle", between @validate and @resolveValueAndMerge; and "end", after @resolveValueAndMergefieldIDsfieldIDs for all directives at a later stage in the pipelineDirective-based middleware is at least as good as field-based middleware, because it can implement all the same functionalities. In addition, it provides several features which would require hacks or extra complexity to achieve with the field-based middleware.
Let’s check these out.
As mentioned earlier on, the graphql-middleware project states that “directives encourage you to mix schema with your functionality.”
This is true for SDL-first GraphQL servers, but not necessarily for code-first GraphQL servers (I explained the difference between them in a previous article). For the latter approach, we can execute a directive in the query directly, without having to define it in the schema.
Gato GraphQL follows the code-first approach. It provides the possibility of declaring IFTTT (If This, Then That) rules to automatically execute a directive:
As we saw earlier on, this last rule is used by the directive @cache to implicitly add @getCache to the beginning of the pipeline.
With these rules, we can automatically add a certain directive to the query without modifying the schema, while at the same time being able to add the directive manually if required. In contrast, we can’t indicate to execute certain field-resolver middleware function through the query, at least without a hack.
For instance, a @traceExecutionTime directive (implemented here) can help analyze the performance of the API in a granular fashion:
"any" field on "any" type@traceExecutionTime directive in the query on the field(s) that need be evaluatedAs explained earlier on, there are certain operations that cannot be executed independently for each field or else the quality of the API may degrade too much. As an example, I mentioned a @translate directive connecting to the Google Translate service.
Using the directive pipeline, we can execute a single call containing all involved fields as inputs. Then, directive @translate can translate dozens of strings all together in a single request.
This could also be achieved using the field-based middleware, but then we are in charge of implementing the extra logic (batching/deferring), and the code would be more complex and difficult to maintain.
As a design decision, the GraphQL engine depends directly on the directive pipeline for resolving the query. For this reason, directives are treated as low-level components, with access to the object where the response is stored.
As a result, any custom directive has the power to modify the GraphQL response. An evident use case for this is directive @removeIfNull (implemented here), which allows us to indicate in the query if we’d rather omit the response from a field than to receive a null value (there is an issue in the spec concerning this feature).
Designing the architecture is fun, but explaining its underlying code is not, so I just provide the links to the logic generating the directive pipeline and to the directive interface.
Concerning the directive interface, please pay attention to the parameters that function resolveDirective receives:
public function resolveDirective( TypeResolverInterface $typeResolver, array &$idsDataFields, array &$succeedingPipelineIDsDataFields, array &$succeedingPipelineDirectiveResolverInstances, array &$resultIDItems, array &$unionDBKeyIDs, array &$dbItems, array &$previousDBItems, array &$variables, array &$messages, array &$dbErrors, array &$dbWarnings, array &$dbDeprecations, array &$dbNotices, array &$dbTraces, array &$schemaErrors, array &$schemaWarnings, array &$schemaDeprecations, array &$schemaNotices, array &$schemaTraces ): void;
These parameters evidence the low-level nature of the directive. Concerning the design decisions explained earlier on, we have parameters:
$idsDataFields – the list of IDs per field to be processed by the directive$succeedingPipelineIDsDataFields – the list of IDs per field to be processed by directives at a later stage in the pipeline$resultIDItems – the response objectThe other parameters make it possible to: access the query variables and define dynamic variables (as done by the @export directive); pass messages with custom data across directives; raise errors and warnings; identify and display deprecations; pass notices to the user; and store metrics.
Directives are among GraphQL’s most powerful features, but that is only if the GraphQL server provides a good support for them.
In this article, we identified middleware as a starting point from which to design a suitable architecture for executing directives in GraphQL, but we ultimately settled on using the chain-of-responsibility design pattern instead, based on the structure called “pipeline.”
With this decision, we had a step-by-step tour of the decisions taken for designing a directive pipeline that makes the most out of GraphQL.
This article is part of an ongoing series on conceptualizing, designing, and implementing a GraphQL server. The previous articles from the series are:
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

