If you have ever implemented a GraphQL server using some available framework — Apollo Server, graphql-yoga, graphql-php, Sangria, or any of any of the others in any language — you probably found many features you liked and that satisfied your application’s requirements.

However, quite possibly, you also hit a few roadblocks. You may have been unable to implement certain features that would improve your application, related to concerns such as:
Similar to your own experience? If so, have you checked the documentation and the code from the open-source framework you are using to understand why it is hitting those roadblocks? Is it due to its language (i.e., limitations inherent to Node.js/Ruby/PHP/etc.)? Or due to its underlying architecture? Could it be improved?
Taking it even further, have you attempted to provide the missing features your application needs by contributing a pull request or, if you’re of the daring kind, building your own server by forking an existing one? Or even from scratch? If you have, how did it go? What lessons did you learn? Did you succeed? (Please let us know in the comments!)
I have, by taking the wildest road: I built my own GraphQL server, implemented in PHP. I finished its implementation recently (as in “it’s working,” not “it’s 100 percent complete and I will not work on it anymore”), open-sourced it, and gave it a name: GraphQL by PoP. And in the process of doing it, I gained a great amount of knowledge, which I want to share with everyone.
This is a series of articles in which I describe how to design a GraphQL server based on my own experience. Each article will focus on some specific feature (concerning performance, productivity, extensibility, usability, and others), describe the strategy to implement it, and, finally, demonstrate some implementation code.
I will attempt to describe the concepts and solutions in an abstract way as much as possible, so that even though the implementation code is PHP, the strategy can be replicated across other languages, too. And there will be lessons and applications not just for the server side, but also for the client side (e.g., how we can reduce the amount of JavaScript code to execute).
Let’s start! In this article, we will talk about performance and learn how a GraphQL server can avoid the N+1 problem already by architectural design.
The N+1 problem basically means that the amount of queries executed against the database can be as large as the amount of nodes in the graph.
Let’s check it out with an example. Let’s say we want to retrieve a list of directors and, for each of them, their films, using the following query:
{
query {
directors(first: 10) {
name
films(first: 10) {
title
}
}
}
}
To be efficient, we would expect to execute only two queries to retrieve the data from the database: one to fetch the directors’ data, and one to retrieve the data for all films by all directors.
However, in order to satisfy this query, GraphQL will need to execute N+1 queries against the database: one first to retrieve the list of the N directors (10 in this case) and then, for each of the N directors, one query to retrieve their list of films. In our case, we must execute 1+10=11 queries.
This problem arises because GraphQL resolvers only handle one object at a time, and not all the objects of the same kind at the same time. In our case, the resolver handling objects of the Query type (which is the root type) will be called once the first time to get the list of all the Director objects, and then the resolver handling the Director type will be called once for each Director object to retrieve their list of films.
In other words, GraphQL resolvers see the tree, not the forest.
This problem is actually worse than it initially appears because the number of nodes in a graph grows exponentially on the number of levels of the graph. So the name N+1 is valid only for a graph two levels deep. For a graph three levels deep, it should be called the “N2+N+1″ problem! And so on…
Mathematicians may want to call it the “
∑Ni” problem, withiiterating between 0 and the number of levels in the graph minus 1, andNbeing the number of results from the query at each level in the graph… But luckily for all of us developers, we just call it the N+1 problem 😂.
For instance, following our example above, let’s also add each film’s list of actors/actresses to the query, like this:
{
query {
directors(first: 10) {
name
films(first: 10) {
title
actors(first: 10) {
name
}
}
}
}
}
The queries executed against the database are: one first to retrieve the list of the 10 directors; then one query to retrieve each director’s list of films for each of the 10 directors; and, finally, one query to retrieve each list of actors/actresses for each of the 10 films for each of the 10 directors. This gives a total of 1+10+100=111 queries.
After noticing this behavior, the N+1 problem can easily be considered GraphQL’s biggest performance hurdle. If left unchecked, querying graphs a few levels deep may become so slow as to effectively render GraphQL pretty much useless.
The solution to the N+1 problem was first provided by Facebook through its utility called DataLoader, implemented for Node.js. Its strategy is very simple: through promises, it defers resolving segments of the query until a later stage, wherein all objects of the same kind can be resolved all together in a single query. This strategy, called batching, effectively solves the N+1 problem.
In addition, DataLoader caches objects after retrieving them so that if a subsequent query needs to load an already-loaded object, it can skip execution and retrieve the object from the cache instead. This strategy, which is (unsurprisingly) called caching, is mostly an optimization on top of batching.
The batching strategy (sometimes renamed as “deferred,” or similar) has become the standard solution to the N+1 problem, being replicated by different GraphQL servers in several languages, such as: GraphQL::Batch for graphql-ruby (Ruby), graphql-php by Webonyx (PHP), and Sangria (Scala).
Technically speaking, there is no problem whatsoever with the batching/deferred strategy; it just works. (For simplicity’s sake, from now on, I’ll refer to the strategy as “deferred.”)
The problem, though, is that this strategy is an afterthought; the developer may first implement the server and then, noticing how slow it is to resolve the queries, will decide to introduce the deferring mechanism.
Thus, implementing the resolvers may involve some faux steps, adding friction to the development process. In addition, since the developer must understand how the deferred mechanism works, it makes its implementation more complex than it could otherwise be.
This problem doesn’t lie in the strategy itself, but in having the GraphQL server offering this functionality as an add-on — even though without it, querying may be so slow as to render GraphQL pretty much useless (as I mentioned earlier on).
The solution to this problem, then, is straightforward: the deferred strategy should not be an add-on but baked into the GraphQL server itself. Instead of having two query execution strategies — normal and deferred — there should only be only one: deferred. And the GraphQL server must execute the deferred mechanism even though the developer implements the resolver the normal way (in other words, the GraphQL server takes care of the extra complexity, not the developer).
How to achieve this?
The problem is that resolving the object types (object, union, and interface) as objects is done by the resolver itself when processing the parent node (e.g., films => directors).
The solution is to transfer this responsibility from the resolver to the server’s data loading engine, like this:
DataLoader entity that, given a list of IDs of a certain type, obtains the corresponding objects from that typeDataLoader (which can efficiently include all the IDs into a single query)This approach can be summarized as: “Deal with IDs, not with objects.”
Let’s use the same example from earlier to visualize this new approach. The query below retrieves a list of directors and their films:
{
query {
directors(first: 10) {
name
films(first: 10) {
title
}
}
}
}
Pay attention to the two fields to retrieve from each director — name and films — and how they are currently different.
The name field is of scalar type. It is immediately resolvable since we can expect the object of type Director to contain a property of type string called name, containing the director’s name. Thus, once we have the Director object, there is no need to execute an extra query to resolve this property.
The films field, though, is a list of object type. It is normally not immediately resolvable since it references a list of objects of type Film, which must still be retrieved from the database through one or more extra queries. Thus, the developer would need to implement the deferred mechanism for it.
Now let’s consider the different behavior and have field films be resolved as a list of IDs (instead of a list of objects). Because we can expect the Director object to contain a property called filmIDs containing the IDs of all its films of type array of string (assuming that the ID is represented as a string), then this field can also be resolved immediately, with no need to implement the deferred mechanism.
Finally, in addition to the ID, the resolver must give an extra piece of information: the type of the expected object. In our example, it could be [(Film, 2), (Film, 5), (Film, 9)]. This information is internal, though, passed over to the engine, and need not be output in the response to the query.
An implication of this new approach is that a field of object type will be resolved in two different ways: if it contains a nested query it will be represented as an object (or list of objects) and, if not, as an ID (or list of IDs).
For instance, check the difference in the response from the following queries (to see it in action by yourself, execute the queries against this endpoint):
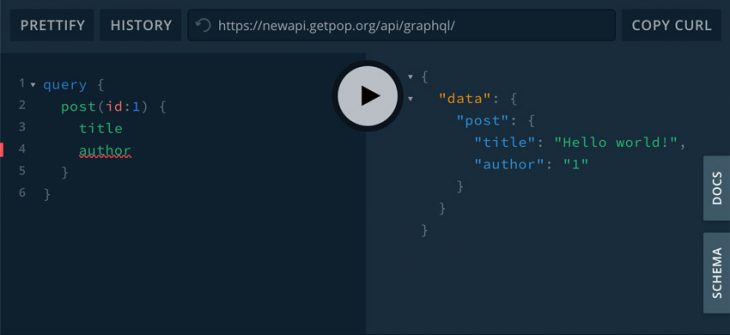
authorfield with nested query:
{
query {
post(id: 1) {
title
author {
name
}
}
}
}
authorfield without nested query:
{
query {
post(id: 1) {
title
author
}
}
}
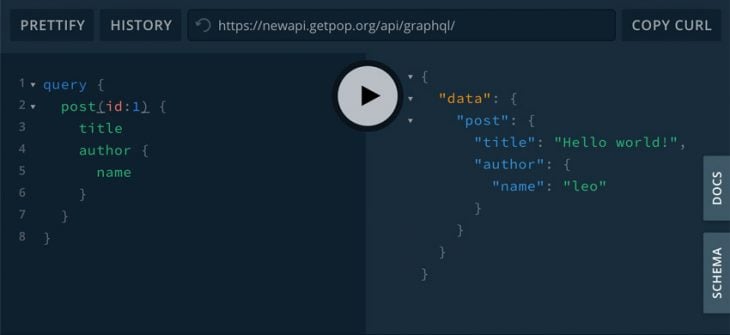
As you can see, the response to field author is, in the first case, the object {"name": "leo"}, and in the second case, it is the string "1".
This inconsistency may, in practical terms, never arise since a field of object type is always expected to provide a nested query (or it would produce an empty object, which makes no sense). Indeed, GraphiQL does not allow us to query for an object without its nested query; it always adds some predefined default fields (for this reason, I had to use the GraphQL Playground to demonstrate the example above).
However, if this behavior must be removed — for instance, to have the returned type always be coherent with the schema — then we can add a very simple solution.
Instead of resolving the field as an ID, we resolve it as an array with the ID stored under property "id" (or whatever the name of that property on the corresponding type), and have the data loading engine retrieve the ID from within the array. Then, querying for an object without its nested query will return {id: ...}, which will be compatible with the definition in the schema for that type.
Let’s see how this adapted strategy looks in (PHP) code, as implemented in GraphQL by PoP. The code below demonstrates the different resolvers; the code for the data loading engine won’t be demonstrated since it’s not simple and it exceeds the scope of this article.
As mentioned earlier on, we will need to split the resolvers into two different entities, FieldResolvers and TypeDataLoaders. In addition, we will be dealing with TypeResolvers. Let’s see these entities one by one.
For the purpose of clarity, all code below has been edited. There will be links pointing to the original code in the repo, where the unedited source code can be found.
FieldResolversFieldResolvers receive an object of a specific type and resolve its fields. For relationships, it must also indicate the type of the object it resolves to. Their contract is defined through this interface:
interface FieldResolverInterface
{
public function resolveValue($object, string $field, array $args = []);
public function resolveFieldTypeResolverClass(string $field, array $args = []): ?string;
}
Its implementation looks like this:
class PostFieldResolver implements FieldResolverInterface
{
public function resolveValue($object, string $field, array $args = [])
{
$post = $object;
switch ($field) {
case 'title':
return $post->title;
case 'author':
return $post->authorID; // This is an ID, not an object!
}
return null;
}
public function resolveFieldTypeResolverClass(string $field, array $args = []): ?string
{
switch ($field) {
case 'author':
return UserTypeResolver::class;
}
return null;
}
}
Please notice how, by removing the logic dealing with promises/deferred objects, the code resolving field author has become very simple and concise.
TypeResolversTypeResolvers are objects that deal a specific type. They know the type’s name and which TypeDataLoader loads objects of its type, among others.
The GraphQL server’s data loading engine, when resolving fields, will be given IDs from a certain TypeResolver class. Then, when retrieving the objects for those IDs, the data loading engine will ask the TypeResolver which TypeDataLoader object to use to load those objects.
Their contract is defined like this:
interface TypeResolverInterface
{
public function getTypeName(): string;
public function getTypeDataLoaderClass(): string;
}
In our example, class UserTypeResolver defines that type User must have its data loaded through class UserTypeDataLoader:
class UserTypeResolver implements TypeResolverInterface
{
public function getTypeName(): string
{
return 'User';
}
public function getTypeDataLoaderClass(): string
{
return UserTypeDataLoader::class;
}
}
TypeDataLoadersTypeDataLoaders receive a list of IDs of a specific type and return the corresponding objects of that type. This behavior is defined through this contract:
interface TypeDataLoaderInterface
{
public function getObjects(array $ids): array;
}
Retrieving users is done like this (in this case, running the GraphQL server on top of WordPress):
class UserTypeDataLoader implements TypeDataLoaderInterface
{
public function getObjects(array $ids): array
{
return get_users([
'include' => $ids,
]);
}
}
This is pretty much it.
I will not analyze the big O notation of the solution to understand how the number of queries grows as the number of nodes in the graph grows, since this is difficult to do and requires analyzing how the data loading engine works (which I haven’t done yet, and plan to do in an upcoming article).
Instead, I will simply provide a query of great complexity, involving a graph 10 levels deep (posts => author => posts => tags => posts => comments => author => posts => comments => author), which could not be resolved if the N+1 problem were taking place. The query is this:
query {
posts(limit:10) {
excerpt
title
url
author {
name
url
posts(limit:10) {
title
tags(limit:10) {
slug
url
posts(limit:10) {
title
comments(limit:10) {
content
date
author {
name
posts(limit:10) {
title
url
comments(limit:10) {
content
date
author {
name
username
url
}
}
}
}
}
}
}
}
}
}
}
To execute this query and play with it, go to this GraphiQL client and press on the “Run” button. You can then scroll down on the results to see how big the response is, and how many entities it involves, and how many levels it retrieved.
The N+1 problem is GraphQL’s archenemy, something to avoid at all costs. It makes GraphQL inefficient by executing queries independently of each other when they could, instead, be combined into a single query, becoming increasingly slow as the depth of the graph increases.
There is a solution to this problem, provided by DataLoader and the libraries for the various GraphQL servers in different languages that it influenced. However, there is a disadvantage with all these libraries: they exist. This entails that there are two alternative paths for the developer:
It would be much better if the deferred mechanism for solving the N+1 problem was already embedded into the core of the GraphQL server, executed by default (indeed, there is no alternative but to use it), and in such a way that the developer need not even be aware of its existence.
This improvement can be achieved with a simple reorganization of the GraphQL server’s architecture: have a FieldResolver resolve relationships as IDs, not as objects, and then have the data loading engine retrieve the corresponding objects for these IDs just before executing the relationship’s nested query by invoking a TypeDataLoader object.
As a welcome side effect, the code implementing the new approach is more concise: splitting the resolvers into the two different entities FieldResolvers and TypeDataLoaders adds separation of concerns, making each piece of code more atomic and legible, and the logic in the resolvers becomes more simple.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Not sure if low-code is right for your next project? This guide breaks down when to use it, when to avoid it, and how to make the right call.

Compare Firebase Studio, Lovable, and Replit for AI-powered app building. Find the best tool for your project needs.

Discover how to use Gemini CLI, Google’s new open-source AI agent that brings Gemini directly to your terminal.

This article explores several proven patterns for writing safer, cleaner, and more readable code in React and TypeScript.
