If you’ve ever had a feature slip because “the data wasn’t ready,” this article is for you. As PMs, we’re great at wrangling dependencies when they look like APIs, SDKs, or design systems. But we often treat data like infrastructure, until it delays a launch, derails an experiment, or erodes trust in a KPI.

I want to encourage you to shift towards treating data as inventory, not infrastructure. That means managing data like a real product that your team depends on, tracking things like its quality, freshness, lead time, cost, and ownership to keep it organized, reliable, and accountable. When you do, you start asking the right questions, making clearer promises, and shipping on time more often.
That all sounds nice, doesn’t it? But what does it mean in practical terms to “treat data as inventory, not infrastructure?”
I found myself asking that question while working on a project that started to miss its marks because of data reliability issues. The answer changed the way I approach data product management for the better.
This article is a playbook you can drop into your product rituals next week, written for PMs who want fewer surprises and more predictable delivery. Let’s get started.
A little while back, the product team that I managed was building a retention dashboard to guide pricing and lifecycle triggers. The linchpin was a customer identity dataset, which seemed straightforward: daily freshness, stable schema, easy joins. In reality, the identity resolution job lagged 24-60 hours under peak load.
Issues started cropping up over time. A column rename slipped into production without a heads-up. The dashboard missed its window. Worse, a feature that reused those same identifiers slipped too. Engineering looked “done,” but our information supply wasn’t.
This is the hidden failure mode of modern product development. Data reliability issues hide inside sprint commitments and only reveal themselves at the end. And when they do, the fix isn’t a better dashboard — it’s proper inventory management.
If your feature depends on data, you own that dependency just like you would an external API. You need a contract (schema plus SLA), an escalation path, and a shared understanding of quality and lead time. Otherwise, you’re making date promises with invisible risk baked in.
A data product is a packaged dataset built for reuse, with clear purpose, quality expectations, and accountability. It needs to be treated like a product: planned, maintained, and relied on.
Think of a data product as a reusable source of truth with explicit commitments: schema stability, freshness, access patterns, and lineage. It’s durable, lives on a roadmap, accrues technical debt, and has owners and consumers.
It’s not “the pipeline” (that’s the conveyor belt) and it’s not “the dashboard” (that’s a view). A data product is the shelf-stable inventory other teams rely on.
The following table outlines how this differs from other data artifacts:
| Asset type | Purpose | Contract surface | Stability | Consumers | Success measure |
| Data product (identity table, feature store, partner feed) | Reusable information | Schema, freshness SLA, access pattern, lineage | Versioned & predictable | Multiple teams / services | Reliable reuse; decision throughput |
| Pipeline | Move / transform data | Run books, job timing | Variable | Upstream / downstream jobs | On-time runs |
| Dashboard / report | Human interpretation | Metric definitions, filters | Medium | Analysts, execs | Accurate, timely insight |
| Ad-hoc view | One-off exploration | Minimal | Low | Individuals | Short-lived utility |
When you treat data like a product, it follows a clear lifecycle: creation → evolution → deprecation → retirement. Without that structure, datasets accumulate without ownership, grow stale, and quietly break things downstream.
In practice, this means managing data the way you manage APIs. Treat breaking changes with care:
You’re not just producing tables, you’re maintaining products that others rely on. So don’t measure value by volume. Measure it by:
That’s how data becomes leverage, not liability.
Inventory has real costs and value. So does data. When you talk about data in those terms, it’s easier to explain and justify decisions.
Your team might want real-time personalization. Streaming supports sub-minute freshness, but it’s expensive to build and run. Micro-batching every 15 minutes is cheaper, but less fresh. That’s a tradeoff: freshness versus cost.
Framed this way, it becomes a business decision.
Streaming gives sub-minute freshness but costs more to serve and operate. Micro-batching buys intra-hour freshness at a reasonable cost. Daily batches are cheap and fine for stable decisions.
For each major data product, ask: What is the unit cost of additional freshness, and who funds it? If personalization needs 15-minute freshness to move a KPI, that’s an investment story, not a hope.
Lead time is the distance between upstream change and downstream usability. Volatility is how spiky demand or source stability is. Long lead time plus high volatility equals fragile roadmaps.
Options include buffering (feature flags, rollout windows), decoupling (caches, contracts that absorb change), or shortening lead time (automate backfills, kill manual approvals, tighten batch windows).
Returns tell you how your supply chain performs. Track null/duplicate rates on key fields, schema drift incidents per quarter, and SLA breaches per 1,000 runs. Not to punish, to prioritize.
Fix the biggest offenders first; quality improvements compound across every downstream consumer.
Use this one to five scale to assess each data product. One means weak or unreliable (e.g., stale, high-defect, hard to use). Five means strong, trustworthy, and ready for reuse. The goal isn’t perfect scores, it’s visibility. Scores help you spot weak links, prioritize fixes, and make clearer trade-offs:
This isn’t about perfect scores. It’s about honest scores that drive better commitments and more thoughtful trade-offs.
Now, before we get into contracts, let’s define what I mean by the roles.
Producers are the teams or systems that create, transform, or own datasets, often data engineering, platform teams, or upstream services.
Consumers are the teams that rely on that data to build features, power dashboards, run experiments, or make decisions, typically product teams, analysts, ML engineers, or downstream services.
A contract is the shared agreement between them, what data is available, how fresh it is, what it means, and what happens when it changes. Just like APIs, these expectations need to be explicit, versioned, and maintained. Otherwise, features break silently and decisions get made on shaky ground.
Run data like you run your external API.
Publish the schema with semantics (not just types), a freshness SLA (“P95 ≤ 30 min; P99 ≤ 60 min”), lineage to critical upstreams, access patterns (batch, streaming, API), and a dead-simple escalation path (on-call hours, Slack channel).
If a consumer can’t answer “What fields can I trust and who do I ping?” in five minutes, the contract isn’t done.
Breaking change? Don’t “hot-edit” a popular table. Ship v2, announce a deprecation date for v1, include sample queries and a field mapping in the migration guide, and backstop the migration with tests or fixtures.
You’ll turn five surprise incidents into one planned upgrade.
You don’t need a committee. You need three artifacts:
Why does this reduce coordination cost? When contracts are visible and versioned, 80 percent of coordination moves from meetings to docs.
Consumers self-serve, PMs reduce buffers, and delivery stops being a guessing game.
Not every dataset needs the same guarantees, or the same investment. Classifying data by business criticality helps you decide where to focus effort.
This includes how important the data is, how often it’s used, and how long it needs to stay reliable. It sets the stage for the right level of ownership, funding, and process.
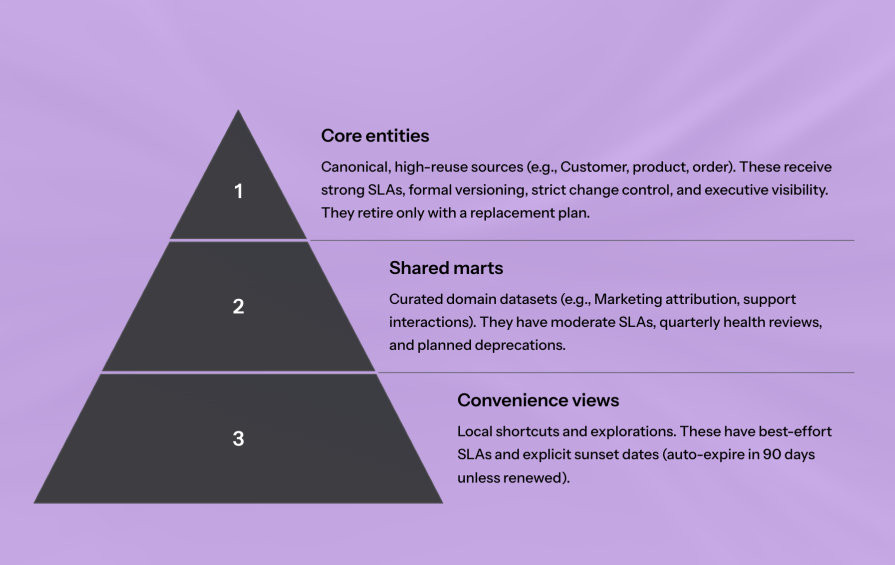
| Category | Purpose | Examples | Management |
| Core entities | Canonical, high-reuse sources | Customer, product, order, Identity Graph | Strong SLAs, versioning, strict change control, exec visibility. Retire only with a replacement |
| Shared marts | Curated domain-level datasets | Attribution mart, support interactions | Moderate SLAs, quarterly reviews, planned deprecations |
| Convenience views | Local shortcuts, ad hoc queries | Team-specific joins, temporary views | Best-effort SLAs, auto-expire in 90 days unless renewed |
Core entities often sit with a central platform/data team; marts and convenience views can live with domain teams. If many teams benefit, finance centrally; if one team benefits, they pay. Tie reliability investments to KPI impact, not vague “data quality.”
Run a predictable cadence:
Use the scorecard (from the inventory section) to make decisions:
Treating data as inventory aligns PMs, data engineers, and analysts around a shared responsibility: making and keeping promises. When you do this, freshness becomes a priced, owned choice, not a hope, contracts replace assumptions, versioning replaces surprises, and features stop living at the mercy of invisible breaks.
Ultimately, you’ll drive more predictable delivery with clearer dates and fewer “we’re blocked on data” updates. A roadmap that behaves like a promise.
As a final note, you can use this quick PM checklist to put this in motion this week:
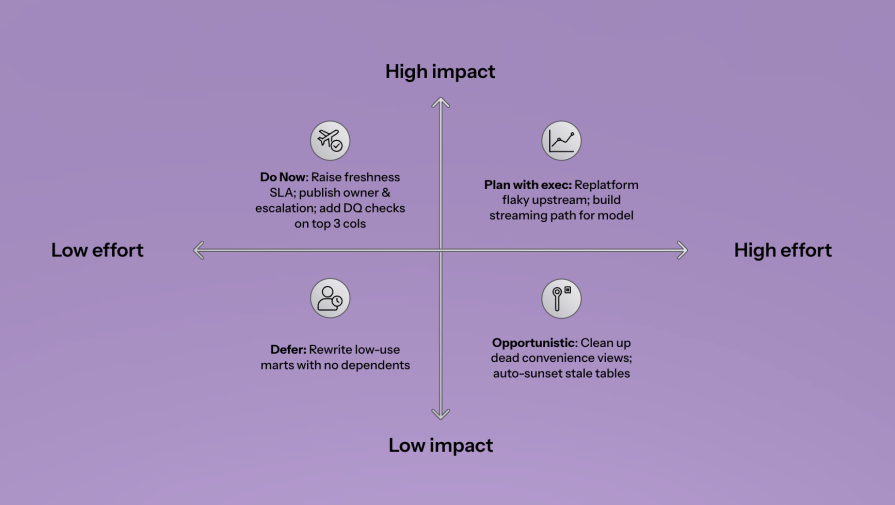
Adopt this, and you’ll manage data like the inventory that fuels your product line — counted, owned, priced, and ready when you need it.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

A practical framework for product leaders to prioritize better, reduce noise, and focus teams on what matters most.

Explore how urban planning helps product managers think in systems, strengthen foundations, and build products that scale well.
Learn how product managers can move from output tracking to outcome-driven product management with metrics tied to user impact.

Learn how to spot PMF erosion early, diagnose the cause, and help your product recover before decline turns into panic.


