DevOps seeks to deliver both consistency in the pace of value delivery (development) and in system uptime (operations). These are vital to the success of a product and it can become painfully obvious when the two are out of sync.

Because of this, organizations have attempted to close the gap between the development and operations teams to avoid any holes that would be detrimental to the product.
In this article, you will learn what site reliability engineering is, SRE principles and best practices, and the relationship between SRE and standard DevOps.
Site reliability engineering (SRE) is a software management approach that seeks to bridge the gap between development and operations teams. SRE combines software engineering with operations principles to ensure that systems are scalable, reliable, and performing at a high level.
SRE teams lean on software, as opposed to individuals, to manage systems and automate operational processes. This helps to transition tasks that have traditionally been performed by operations teams over to automated software systems. By doing so, you can improve efficiency and reduce the potential for human error.
As we know it today, SRE started in 2003 at Google. Up until then, there was a rigid divide between the responsibilities of software engineers and system administrators — what we now refer to as the development and operations domains, respectively.
At the time, companies relied mostly on physical infrastructure. System administrators (sysadmins) were responsible for deploying code to servers and keeping infrastructure components in good working order.
Due to growth in the number of applications and traffic passing through the infrastructure, there was an increase in the number of operations staff needed to keep everything running. Meanwhile, developers still needed to push new features to production, and because of the conflict inherent in these competing development and operations business objectives, the seeds of the DevOps movement were planted.
To solve this, Google decided to let technical staff experiment with different ways of working. It began to treat traditional operational (sysadmin) concerns as software problems. As they built out their capabilities via experimentation, the early SRE teams at Google found more and more ways to solve complex software problems.
Eventually, those principles and practices, and even the SRE job function itself, have found their way to other organizations.
By now, many organizations have experimented with SRE principles and practices. While it’s certainly true that SRE looks can vary considerably from one organization to another, there are certain patterns that are common.
When it comes to SRE principles, it’s not a simple matter of looking in a single place for a set of standards. Still, there are some common themes that emerge related to SRE principles, such as the following:
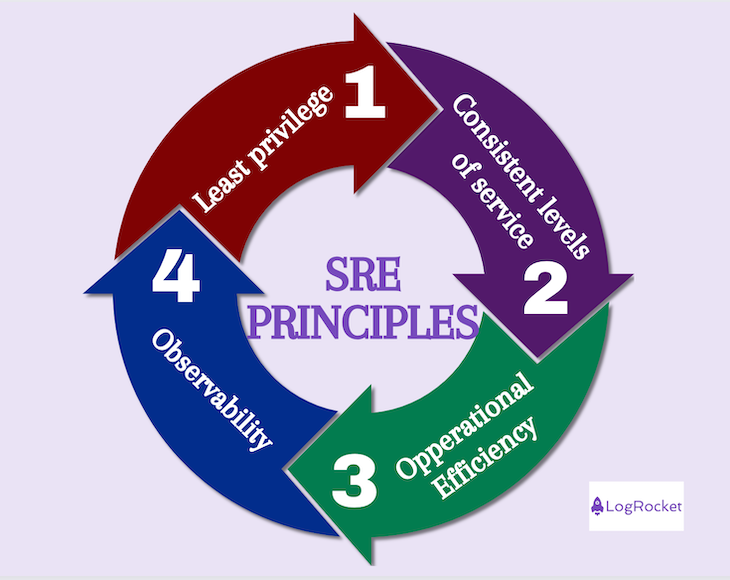
In product management, systems and services must be secure. One way to ensure that you protect your customers is through the concept of least privilege. In this concept, you only grant the minimum amount of access necessary to use your systems and networks. Related principles include:
Metrics and measures are also a key component of SRE, and three areas in particular stand out with respect to service levels:
Service level indicators (SLIs) help you gauge whether your product delivers consistent service. Some of the most common SLIs are latency (how long it takes to get a response back from a system request), error rate (the fractional number of all requests that return an incorrect response) system throughput (the pace at which requests and responses reach their intended target), and availability (how much of the time the system or service is actually usable).
In SRE, we use service level objectives (SLOs) to specify an ideal value or range of values for how well a service or system should perform.
If you consider latency, for instance, there might be an SLO that specifies what the average latency should be for a particular operation, such as how long it should take to return a search result. The relationship between SLIs and SLOs is similar to the relationship between key performance indicators (KPIs) and key results (KRs), where in the former case, you articulate what you seek to achieve, and in the latter, you specify a measure or metric that tells you whether you have been successful.
Service level agreements (SLAs) tell you if you have met your SLOs. When SLAs exist with external parties, they tend to be contractual, where failing to achieve what’s stipulated in the SLA might result in a rebate or a penalty that the third party incurs. Internal SLAs can take various forms, and often inform staffing for on-call rotations.
In SRE circles, the term operational efficiency has to do with “reducing toil,” where “toil” is work that may have one or more of the following attributes:
When a system or service is observable, it means you can make inferences about its internal state, based on what you discern from external outputs. Monitoring is an enabler of observability, where monitoring gives you capabilities to observe how a system or service performs over time.
Three standard components of a monitoring solution include metrics, logs, and traces, where:
An observable system or service is one where you can leverage the data and insights that monitoring produces to gain a holistic understanding of the overall health of the larger solution. By doing so, monitoring provides the instrumentation that enables effective decision-making across your portfolio of systems and services.
Similar to how there are too many SRE principles to cover, there are even more SRE practices. Below is a representative sample:

Alerting practices are closely related to the observability principle. SRE faces the challenge that:
It’s important when configuring alerting at scale to prevent alerts for single-machine failures. Instead of focusing on single components, focus on what the aggregation of signals tells you once outliers have been pruned away. You need to tune your monitoring systems and the accompanying alerts based on SLOs, while also retaining the ability to inspect specific components where there is a need to do so.
In the SRE domain, there’s a need to respond to situations that may require attention, and in some cases, immediate remediation. When setting up on-call rotations, you need to consider areas such as the following:
There’s a big difference between managed and unmanaged incidents. While it’s not possible to plan for every scenario in advance, there are many proactive steps you can take, such as:
When load balancing, you should carefully consider each of following steps based on your organization’s specific needs and context:
By now, it’s a well established practice that continuous learning and improvement are vital to long-term success. Within an SRE context, incident post-mortems (which are conceptually similar to retrospectives) often have the following characteristics:
At the start of this article, we introduced SRE by referencing ideas that are central to DevOps. It’s easy to get confused when it comes to what constitutes DevOps versus what constitutes SRE, so let’s take a look at the similarities and differences.
As with any set of principles and practices, it’s necessary for each organization to run small experiments and see what works best for their context. You can learn a great deal from the application of SRE principles (such as least privilege, consistent levels of service, operational efficiency, and observability) and practices (alerting, on-call, incident response, load balancing, and continuous learning culture).
To dive deeper into the topics we’ve touched on here, feel free to browse the set of SRE books that Google has made available for free online reading.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.
Learn how product managers can use human-in-the-loop AI to manage decision risk, set oversight, and keep ownership and accountability human.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.


