Before becoming a product manager, I worked as a project manager. Sometimes I miss those teams. They were definitely…intense.

One of my fondest memories was taking over an existing team with a history of issues. Productivity was slow, deadlines were never met, and the overall happiness level was low.
Luckily, the individuals on the team were truly incredible players. Together, we managed to completely overhaul the project in less than two months. We reduced cycle time by ~66 percent and work in progress by ~50 percent and improved our velocity and predictability tremendously.
And it all came down to a single metric.
It all started when I took over quite a large project in the software house I was working at. We were building a platform that would allow the client to easily integrate and modernize newly acquired marketplaces all around the world.
Due to the nature of the initiative, it was a classic “one big-bang release” type of initiative that couldn’t be delivered iteratively. The project was infamous for missing deadlines — when I took over, the release date was already pushed a few times, and the team was still a few months behind schedule.
At first glance, it was easy to spot numerous inefficiencies, but one metric really stood out: the cycle time.
The median cycle time of one product backlog item was roughly three weeks. It literally took three weeks between picking up a ticket in Jira to marking it as “done.”
This caused a series of other problems. To name a few:
I realized that although the cycle time itself wouldn’t magically solve all of our problems, it was the most impactful improvement we could make at that moment to work more effectively. So we decided to make cycle time reduction our top improvement focus.
The first step was to analyze why the cycle time was so high. Being used to cycle time ranging from two to five days, three weeks seemed really off and must have resulted from a series of problems, not just one.
To identify what the problems were, I approached it from two angles:
The first step was to break down cycle time into smaller, more manageable metrics.
We leveraged a repository-level data analysis tool to get a clearer picture:
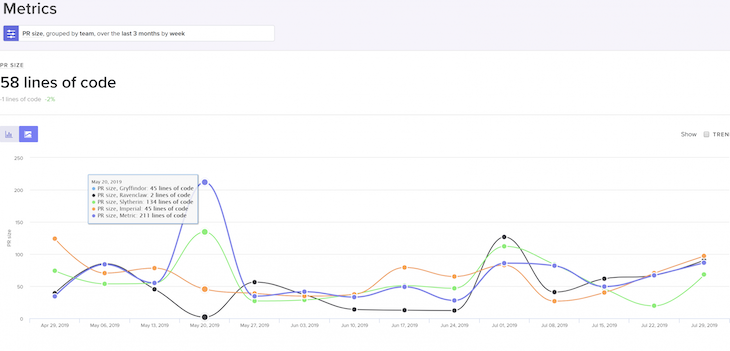
By looking at individual submetrics that constituted our cycle time, I noticed two major outliers:
That was a strong signal that the code review process is one of the main bottlenecks in our process.
Another interesting insight was looking at everyone’s contributions to the repository. It turned out that junior developers were spending three times as much time on code review as senior developers. That was odd.
After getting a deeper understanding of the problem, I followed up with individual interviews with each team member.
There were a few recurring patterns:
Both exercises painted a somewhat clear list of issues. I narrowed them down to:
With the hardest part done, it was time to jump into solutions.
For the following weeks, we used the list of issues on every retrospective to ideate potential solutions.
Let me share what worked best:
Initially, we invested a lot of time discussing what a “good” ticket looks like, what “small and atomic” work items mean, and so on. It brought only minor improvements. So we decided to make it simple.
We introduced a rule that only tickets estimated at five story points can make it to the sprint plan, and anything above that must be split into smaller work items. Smaller tickets meant faster development time, quicker code review and QA time, and, most importantly, less room for ambiguity and unclear requirements.
Occasionally we agreed to bring 13 or even 21 story point tickets to sprints. These were exceptions when the team agreed that splitting these would be pointless.
We used a similar approach to limit the number of tickets one developer can work on.
Although we tried to find root causes for blockers and bottlenecks and figure out systematic solutions for them, we found ourselves identifying too many one-off edge cases to pull it off. So we just made a rule that one developer can own three work items simultaneously, tops. This included tickets that were“in development, in code review, and in QA.
If, for some reason, three work items were not done yet — let’s say, for example, one was blocked, one was in code review, one was in testing — the developer was responsible for escalating and doing whatever they could to unblock the work. Sometimes this meant helping out the QA with testing, pushing team members to complete code reviews, or escalating to other teams to handle the dependency.
Obviously, we had some exceptions, but at a high level, it really motivated people to switch from the mindset of, “I’m blocked, let me pick something else” to “I have to unblock myself.”
There was a cultural problem among the team: no one liked doing code reviews. Well, maybe apart from the most junior members.
We tried several tactics to streamline the process, but the one that worked best was establishing dedicated slots for code review.
Every day, we had an hour-long slot in the calendar when every developer was expected to either:
Not only was the slot a good reminder to do so, but the fact that the whole team was engaged in the process simultaneously made resolving comments and clarifying doubts much more efficient.
That was one of the most impactful improvements we introduced.
No one understood why we required three approvals to merge a pull request. So we just changed the rule and required only two approvals. It made the code review faster and freed up the team’s capacity.
We didn’t experience any adverse consequences of doing so. We even considered lowering it to one.
I made clear the expectation to our senior developers that code review is the most important part of their job.
I also asked junior developers to refrain from code reviews for some time. Although they were initially disappointed (it was a nice ego-boosting activity to give feedback on someone else’s code), they didn’t hold a grudge for long.
That setup was simply more efficient.
An interesting hack was adding an automated alert on Slack that generated a message every time a pull request was open for over three working days. Whenever it fired, we knew something was wrong, and we should scramble to close it.
It was also a good indicator of how our process is improving. We started with this alert going on numerous times in the first week to maybe once a week once we improved our processes.
You can’t always compensate for the lack of resources with processes. After solving our code review bottlenecks, we started having QA bottlenecks.
I wish I had a cool story about how we left-shifted our process and built a perfect quality assurance process, but because we had challenges to address and the client wasn’t willing to make the extra investment, we simply onboarded additional QA to ensure we didn’t trade one bottleneck for another.
There are a few things that we tried that didn’t yield the expected results.
Take it with a grain of salt, though. The fact that it didn’t work for us doesn’t mean they won’t work in your case.
As always, everything is context-dependent.
We tried a daily Slack reminder that asked users to look at pull requests and focus on code review. It worked nicely initially but quickly became an annoying distraction that no one cared about.
We integrated GitLab with our Slack to send a notification whenever a pull request opens. The story was similar to daily reminders: people rarely had the time to hop to code review immediately after the notification was fired, and then they simply forgot about the topic.
We tried adhering to a strict definition of ready to address ambiguity, but it was more annoying than helpful.
Most of the doubts and questions appeared while working on the actual implementation, and it was hard to predict them during the planning and refinement phase. Simply working on smaller tickets solved most of the problems anyway.
It’s difficult to clearly state which of our improvements moved the needle to which extent.
We had numerous issues to handle and strict deadlines to rush, so we experimented with multiple things at once and used a gut-feeling approach to evaluate what was working and what was not.
What I can share is the global change after roughly six weeks of improvements.
Our cycle time went down by roughly 66 percent, and along with it, our work-in-progress items went down by roughly 50 percent.
Thanks to this change, we noticed that:
Although we focused solely on cycle time, the improvements it yielded spanned across various areas of our process.
I learned a few key lessons during this story that I have kept close to my heart ever since:
So many factors influence the cycle time, ranging from technicalities to the whole team culture, making cycle time a great metric to assess the holistic health of the development process.
Teams with high cycle time usually have serious issues to address, and low cycle time is a commonly shared characteristic of high-performing teams.
During this whole process, we continued our work. We didn’t go with any extremes, such as “a cleanup sprint” or completely changing how we work overnight.
Small improvements introduced on a weekly cadence were enough to completely change our way of working in the long run.
There’s a limit to what you can learn from analyzing Jira or any other project management data. Repository-level analysis gives you much more details on the health of your development process and even on individual people’s performance.
The best part is you don’t need deep programming knowledge to understand it. You just need to understand a handful of micro-level metrics.
What surprised me the most was the level of insight I got from individual interviews. The truth is, people usually know where the problem is. It all comes down to taking action.
Although I had some sleepless nights during this project, the learnings I got from it were worth it. I hope you learned something from it too, and if you have extra questions, shoot them in the comment or reach out to me directly.

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.
Learn how product managers can use human-in-the-loop AI to manage decision risk, set oversight, and keep ownership and accountability human.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.


