The goal for an @export directive in GraphQL is to export the value of a field (or set of fields) into a variable we can use somewhere else in the query.

Its most evident use case is to combine two queries into one, which eliminates the need for the second query to wait for the first to execute, thus improving performance. There is a proposal to add it to the GraphQL spec through issue [RFC] Dynamic variable declaration.
How would this directive be employed? Let’s suppose we want to search all posts that mention the name of the logged-in user. Normally, we would need two queries to accomplish this.
We first retrieve the user’s name:
query GetLoggedInUserName {
me {
name
}
}
And then, having executed the first query, we can pass the retrieved user’s name as variable $search to perform the search in a second query:
query GetPostsContainingString($search: String = "") {
posts(search: $search) {
id
title
}
}
The @export directive would allow us to export the value from a field and inject this value into a second field through a dynamic variable, whose name is defined under argument as, thus combining the two queries into one:
query GetPostsContainingLoggedInUserName($search: String = "") {
me {
name @export(as: "search")
}
posts(search: $search) {
id
title
}
}
Since being created, this issue has not been upgraded from the strawman stage because it is not simple to implement. In particular, graphql-js (the reference implementation of GraphQL in JavaScript) resolves fields in parallel through promises, so it doesn’t know in advance which field will be resolved before which other field.
This is a blocking problem for @export, because the field exporting the value must be executed before the field reading the value. As a consequence, this directive can only be implemented in GraphQL servers that allow us to control the flow in which fields are resolved, or which support query batching.
Gato GraphQL is a GraphQL server in PHP which, luckily for this case, doesn’t use promises or resolve fields in parallel; it resolves them sequentially, using a deterministic order that the developer can manipulate in the query itself. So, it can support the implementation of the @export directive.
Because this directive could eventually become part of the spec, this specific solution must strive to be as generic as possible, using only features already present in the GraphQL spec, as to provide a model for other GraphQL servers to follow, and as to not deviate too much from an eventual official solution so it can be adapted with minimal rewriting.
In this article I’ll explain how this particular solution for @export works and how it was designed.
As we saw in the query above, @export must handle exporting a single value from a single field: the user’s name.
Fields returning lists should also be exportable. For instance, in the query below, the exported value is the list of names from the logged-in user’s friends (hence, the type of the $search variable went from String to [String]):
query GetPostsContainingLoggedInUserName($search: [String] = []) {
me {
friends {
name @export(as: "search")
}
}
posts(searchAny: $search) {
id
title
}
}
Please notice that argument "as" is also used to define the dynamic variable’s name to export lists, even though the original proposal suggests two different arguments: "as" for a single value, and "into" for lists. However, I believe that "as" is suitable for both cases and makes matters simple, so I stuck to it.
Even though it is not requested in the original proposal, in some circumstances we may also need to export several properties from the same object. Then, @export should allow us to export these properties to the same variable, as a dictionary of values.
For instance, the query could export both the name and surname fields from the user and have a searchByAnyProperty input that receives a dictionary (for which the input type changed to Map):
query GetPostsContainingLoggedInUserName($search: Map = {}) {
me {
name @export(as: "search")
surname @export(as: "search")
}
posts(searchByAnyProperty: $search) {
id
title
}
}
And then, similar to upgrading from a single value to a list of values, we can upgrade from a single dictionary to a list of dictionaries.
For instance, we could export fields name and surname from the list of the logged-in user’s friends (for which the input type changed to [Map]):
query GetPostsContainingLoggedInUserName($search: [Map] = []) {
me {
friends {
name @export(as: "search")
surname @export(as: "search")
}
}
posts(searchAnyByAnyProperty: $search) {
id
title
}
}
In summary, @export must be able to handle these four cases:
The queries below have replaced the field me with user(id: 1) since, otherwise, non-logged-in users couldn’t run it. Later on, we’ll review why the variable name starts with _, why the query uses a field called self, and why the input has a default value even though it is never used.
The implementation for @export, handling all four cases detailed above, is this one. Let’s see how it behaves.
The query below extracts the user’s name into variable $_authorName and then performs a search of all posts containing this string:
query GetPostsAuthorNames($_authorName: String = "") {
user(id: 1) {
name @export(as: "_authorName")
}
self {
posts(searchfor: $_authorName) {
id
title
}
}
}
When running the query, it produces this response:
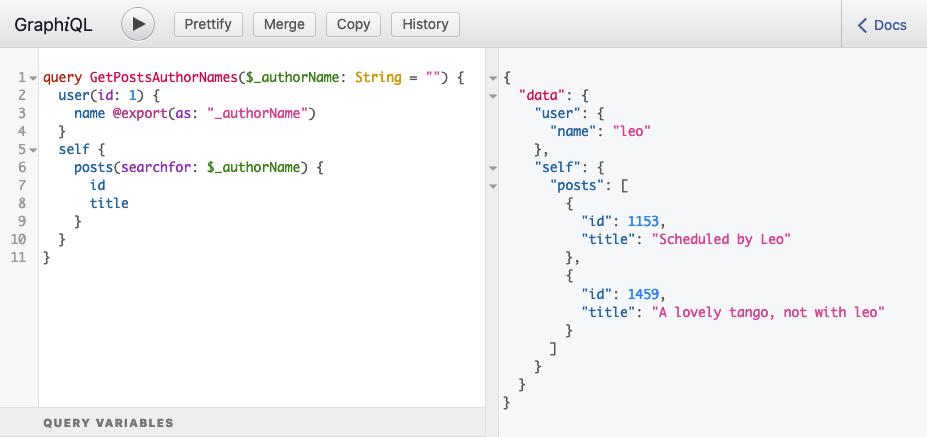
It works: obtaining the user’s name "leo", and searching for all posts containing the keyword "leo", was performed within the same query.
This query comprises the four cases that @export must handle:
query GetSomeData(
$_firstPostTitle: String = "",
$_postTitles: [String] = [],
$_firstPostData: Mixed = {},
$_postData: [Mixed] = []
) {
post(id: 1) {
title @export(as:"_firstPostTitle")
title @export(as:"_firstPostData")
date @export(as:"_firstPostData")
}
posts(limit: 2) {
title @export(as:"_postTitles")
title @export(as:"_postData")
date @export(as:"_postData")
}
self {
_firstPostTitle: echoVar(variable: $_firstPostTitle)
_postTitles: echoVar(variable: $_postTitles)
_firstPostData: echoVar(variable: $_firstPostData)
_postData: echoVar(variable: $_postData)
}
}
Here’s how it works:
Case 1 – @export a single value:
post(id: 1) {
title @export(as: "_firstPostTitle")
}
Case 2 – @export a list of values:
posts(limit: 2) {
title @export(as: "_postTitles")
}
Case 3 – @export a dictionary of field/value, containing two properties (title and date) from the same object:
post(id: 1) {
title @export(as: "_firstPostData")
date @export(as: "_firstPostData")
}
Case 4 – @export a list of dictionaries of field/value:
posts(limit: 2) {
title @export(as: "_postData")
date @export(as: "_postData")
}
The query uses the field echoVar to visualize the content of the dynamic variables. When running the query, it produces this response:
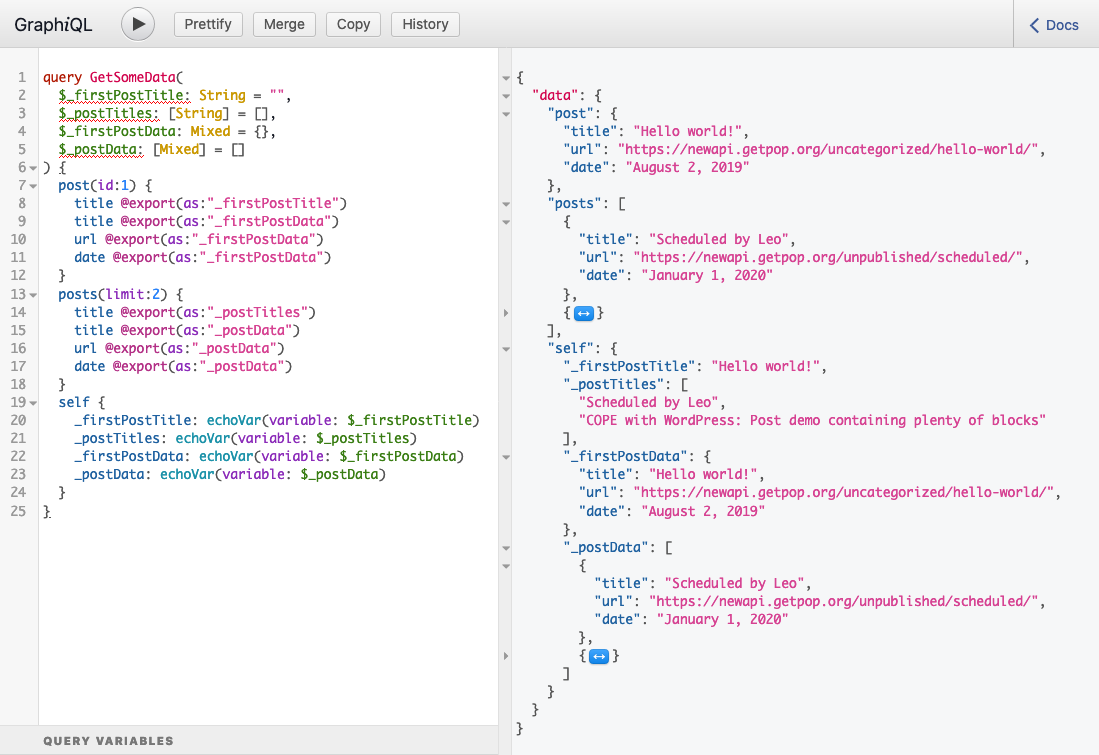
Once again, it works, as the response contains the results handling all four cases:
Case 1 – @export a single value:
{
"data": {
"self": {
"_firstPostTitle": "Hello world!"
}
}
}
Case 2 – @export a list of values:
{
"data": {
"self": {
"_postTitles": [
"Scheduled by Leo",
"COPE with WordPress: Post demo containing plenty of blocks"
]
}
}
}
Case 3 – @export a dictionary of field/value, containing two properties (title and date) from the same object:
{
"data": {
"self": {
"_firstPostData": {
"title": "Hello world!",
"date": "August 2, 2019"
}
}
}
}
Case 4 – @export a list of dictionaries of field/value:
{
"data": {
"self": {
"_postData": [
{
"title": "Scheduled by Leo",
"date": "January 1, 2020"
},
{
"title": "COPE with WordPress: Post demo containing plenty of blocks",
"date": "August 8, 2019"
}
]
}
}
}
Nothing is perfect. In order for @export to work, the query must be coded with the following three peculiarities:
"_"self may be required to control the order in which fields are resolvedI’ll explain why these are mandatory and how they work, one by one.
"_"As we mentioned earlier on, the @export directive is not part of the GraphQL spec, so there are no considerations on the language itself for its implementation. Therefore, the GraphQL server implementers must find their own way to satisfy their requirements without deviating too much from the GraphQL syntax, with the expectation that it could one day become part of the official solution.
For this solution, I decided that @export will export the value into a normal variable, accessible as $variable. Please notice that this is a design decision that may vary across implementers — for instance, Apollo’s @export directive is accessed under entry exportVariables (as doing {exportVariables.id}), not under entry args as its inputs.
As a consequence, Apollo’s solution doesn’t require us to declare the exported variables in the operation name, but my implementation does.
This design decision is challenging to implement because static variables and dynamic variables behave differently: while the value for a static variable can be determined when parsing the query, the value for a dynamic variable must be determined on runtime, right when reading the value of the variable. Then, the GraphQL engine must be able to tell which way to treat a variable, whether the static or the dynamic way.
Given the constraints, and in order to avoid introducing new, unsupported syntax into the query (such as having $staticVariables and %dynamicVariables%), the solution I found is to have the dynamic variable name start with "_", such as $_dynamicVariable. Then, if the name of the variable starts with "_", the GraphQL engine treats it as dynamic and doesn’t resolve it when parsing the query; otherwise, it is treated as a static variable.
This solution is undoubtedly a hack, but it works well. If eventually there is an official solution for the @export directive, and it provides guidelines on how to distinguish between dynamic and static variables, then my solution must be adapted.
self may be required to control the order in which fields are resolvedThe @export directive would not work if reading the variable takes place before exporting the value into the variable. Hence, the engine needs to provide a way to control the field execution order. This is the issue that graphql-js cannot easily solve, with the consequence that @export cannot be officially supported by the GraphQL spec.
As mentioned earlier, Gato GraphQL does provide a way to manipulate the field execution order through the query itself. Let’s see how it works.
N.B.: I have described in detail how the GraphQL engine resolves fields and loads their data in the articles “Designing a GraphQL server for optimal performance” and “Simplifying the GraphQL data model“.
The engine loads data in iterations for each type, resolving all fields from the first type it encounters in the query, then resolving all fields from the second type it encounters in the query, and so on until there are no more types to process.
For instance, the following query involving objects of type Director, Film and Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}
Is resolved by the GraphQL engine in this order:

If after processed, a type is referenced again in the query to retrieve non-loaded data (e.g., from additional objects or additional fields from previously loaded objects), then the type is added again at the end of the iteration list.
For instance, let’s say we also query the Actor‘s preferredDirector field (which returns an object of type Director), like this:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}
The GraphQL engine would then process the query in this order:

Let’s see how this plays out for executing @export. For our first attempt, we create the query as we normally would, without considering the execution order of the fields:
query GetPostsAuthorNames($_authorName: String = "") {
user(id: 1) {
name @export(as: "_authorName")
}
posts(searchfor: $_authorName) {
id
title
}
}
When running the query, it produces this response:
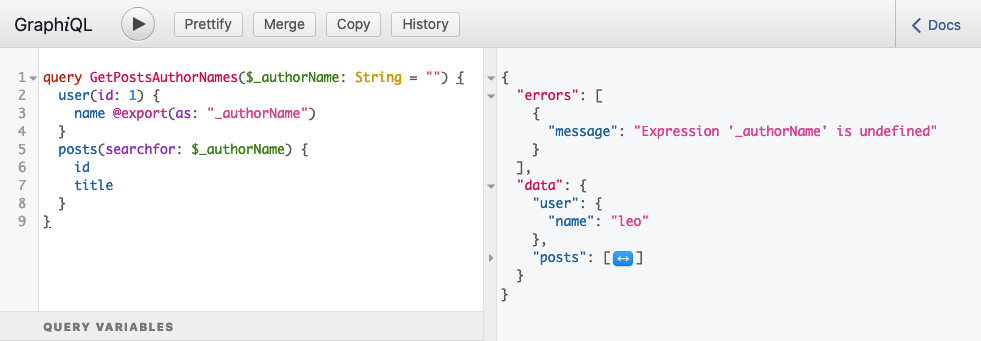
Which contains the following error:
{
"errors": [
{
"message": "Expression '_authorName' is undefined",
}
]
}
This error means that by the time the variable $_authorName was read, it had not yet been set — it was undefined.
Let’s see why this happens. First, we analyze what types appear in the query, added as comments below (type ID is a custom scalar):
# Type: Root
query GetPostsAuthorNames($_authorName: String = "") {
# Type: User
user(id: 1) {
# Type: String
name @export(as: "_authorName")
}
# Type: Post
posts(searchfor: $_authorName) {
# Type: ID
id
# Type: String
title
}
}
To process the types and load their data, the data-loading engine adds the query type Root into a FIFO (First-In, First-Out) list, thus making [Root] the initial list passed to the algorithm. Then it iterates over the types sequentially, like this:
|
#
|
Operation
|
List
|
|
0
|
Prepare FIFO list
|
[Root] |
|
1a
|
Pop the first type of the list (
Root) |
[] |
|
1b
|
Process all fields queried from the Root type:
→
user(id: 1) →
posts(searchfor: $_authorName)Add their types (
User and Post) to the list |
[User, Post] |
|
2a
|
Pop the first type of the list (
User) |
[Post] |
|
2b
|
Process the field queried from the
User type: →
name @export(as: "_authorName")Because it is a scalar type (
String), there is no need to add it to the list |
[Post] |
|
3a
|
Pop the first type of the list (
Post) |
[] |
|
3b
|
Process all fields queried from the
Post type: →
id →
titleBecause these are scalar types (ID and String), there is no need to add them to the list
|
[] |
|
4
|
List is empty, iteration ends
|
Here we can see the problem: @export is executed on step 2b, but it was read on step 1b.
It is here that we need to control the field execution flow. The solution I have implemented is to delay when the exported variable is read, achieved by artificially querying for field self from type Root.
The self field, as its name indicates, returns the same object; applied to the Root object, it returns the same Root object. You may wonder: “If I already have the root object, then why would I need to retrieve it again?”
Because then the GraphQL engine’s algorithm will need to add this new reference to Root at the end of the FIFO list, and we can deliberately distribute the queried fields before or after every one of these iterations.
This is a hack, but it allows us to effectively control the order in which fields are resolved.
That’s why the field posts(searchfor: $_authorName) is placed inside a self field in the query above, and running the query produces the expected response:
query GetPostsAuthorNames($_authorName: String = "") {
user(id: 1) {
name @export(as: "_authorName")
}
self {
posts(searchfor: $_authorName) {
id
title
}
}
}
Let’s explore the order in which types are processed for this query to understand why it works well:
|
#
|
Operation
|
List
|
|
0
|
Prepare FIFO list
|
[Root] |
|
1a
|
Pop the first type of the list (
Root) |
[] |
|
1b
|
Process all fields queried from the Root type:
→
user(id: 1) →
selfAdd their types (
User and Root) to the list |
[User, Root] |
|
2a
|
Pop the first type of the list (
User) |
[Root] |
|
2b
|
Process the field queried from the User type:
→
name @export(as: "_authorName")Because it is a scalar type (
String), there is no need to add it to the list |
[Root] |
|
3a
|
Pop the first type of the list (Root)
|
[] |
|
3b
|
Process the field queried from the Root type:
→
posts(searchfor: $_authorName)Add its type (
Post) to the list |
[Post] |
|
4a
|
Pop the first type of the list (
Post) |
[] |
|
4b
|
Process all fields queried from the Post type:
→
id →
titleBecause these are scalar types (
ID and String), there is no need to add them to the list |
[] |
|
5
|
List is empty, iteration ends
|
Now, we can see that the problem has been resolved: @export is executed on step 2b, and it is read on step 3b.
The GraphQL parser still treats a dynamic variable as a variable, hence it validates that it has been defined, and that it has a value on parsing time, or it throws an error "The variable has not been set".
To avoid this error (which halts execution of the query), we must always define the variable in the operation name, and provide a default value for that argument, even if this value won’t be used.
@skip and @include dynamicI believe that, in some areas, GraphQL currently falls short of its real potential. That is the case concerning the @skip and @include directives, as in this query:
query GetPostTitleAndMaybeExcerpt(
$showExcerpt: Bool!
) {
post(id: 1) {
id
title
excerpt @include(if: $showExcerpt)
}
}
These directives receive the condition to evaluate through the argument "if", which can only be the actual Boolean value (true or false) or a variable with the Boolean value ($showExcerpt). As behaviors go, this is pretty static.
What about executing the "if" condition based on some property from the object itself? For instance, we may want to show the excerpt field based on whether the Post object has comments.
Well, the @export directive makes this possible. For this query:
query ShowExcerptIfPostHasComments(
$id: ID!,
$_hasComments: Boolean = false
) {
post(id: $id) {
hasComments @export(as: "_hasComments")
}
self {
post(id: $id) {
title
excerpt @include(if: $_hasComments)
}
}
}
The response would or would not include the field excerpt, depending on whether the queried post had comments.
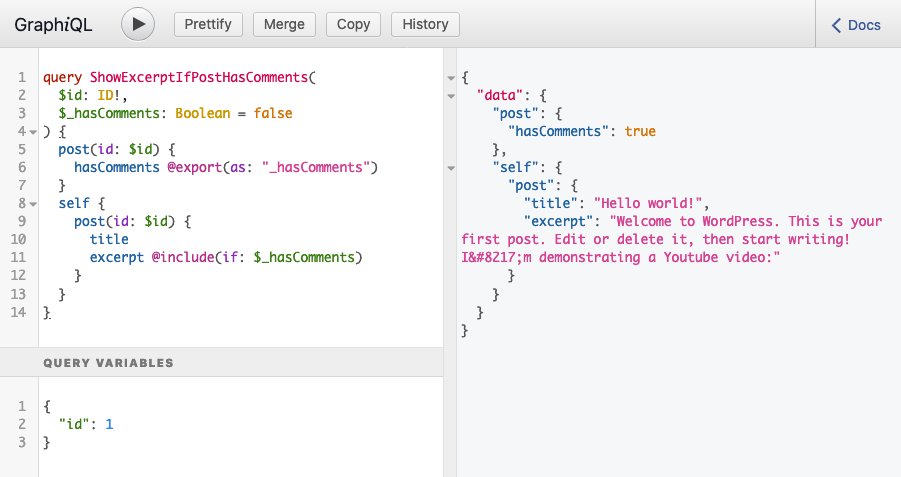
Let’s check it out. Running the query for post with ID 1 produces this response:
Running the query for post with ID 1499 produces this response:
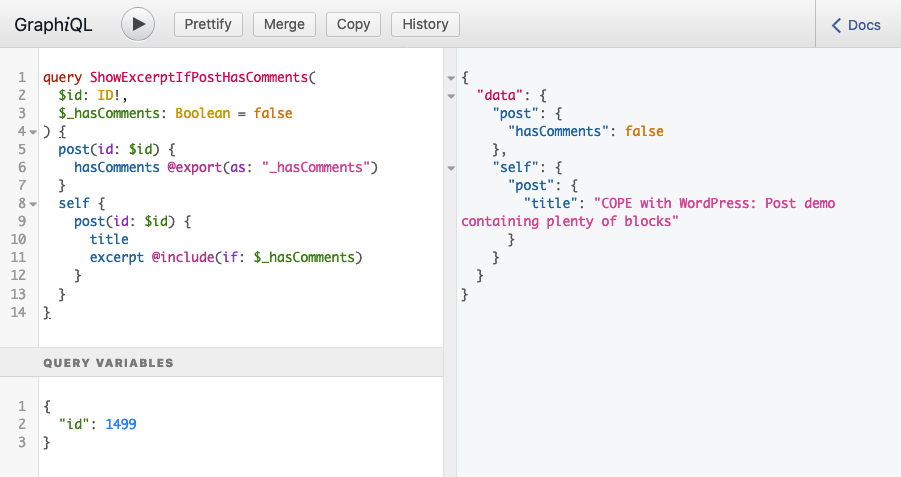
As we can see, @include became dynamic: the same query produces different results based on some property from the queried object itself, and not from an external variable.
This feature works only when the exported variable — in this case, $_hasComments — concerns a single value, but not for lists. This is because the algorithm evaluates the if condition for all objects in the list in the same iteration, overriding each other; then, when this result is checked to perform the @skip/@include validation in some later iteration from the algorithm, only the value from the last object in the list will be available.
In my article GraphQL directives are underrated, I expressed that offering good support for custom directives is possibly the most important feature to pay attention to in a GraphQL server.
The @export directive provides a case in point. Because this directive can improve the performance of our APIs, the community has requested it be added to the GraphQL spec, but support for it is stalled due to technical difficulties. Until an official solution is found, however, we can attempt to code this functionality through a custom directive — so long as the GraphQL server allows us to.
In this article, we explored the implementation of @export done for Gato GraphQL, including the design decisions taken to make the solution as generic as possible, what issues were found along the way, and what compromises (or hacks) were needed to resolve them.
This article is part of an ongoing series on conceptualizing, designing, and implementing a GraphQL server. The previous articles from the series are:
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

