Editor’s note: This article was last updated on 19 September 2023 to offer a different rendering method and to add information about global structured data with Docusaurus.

If you have a website, it’s important to make sure that it is discoverable. In this guide, we’ll show you how to add structured data to your site, which helps search engines such as Google understand your content and get it in front of more viewers. We’ll illustrate how this works by building a simple React app that incorporates structured data.
Jump ahead:
Google, DuckDuckGo, and other search engines are proficient at understanding the content of websites. However, scraping HTML is not a particularly reliable way to categorize content. HTML is all about presentation, and it can be structured in a variety of ways.
To make it easier for search engines to digest the contents of your site, you can embed a standardized format known as structured data within a page. This standardized format allows you to explicitly declare the type of contents the page contains.
There are hundreds of types of structured data available. You can read about all of them in depth at Schema.org, which is maintained by representatives of the search engine community.
Just like there are many different types of structured data, there is a wide range of formats you can use to provide it, including JSON-LD, Microdata, and RDFa. Google explicitly prefers JSON-LD, so that’s what we’ll focus on in this tutorial.
JSON-LD is effectively a rendering of a piece of JSON inside a script tag with the custom type of application/ld+json. For example:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Chocolate Brownie",
"author": {
"@type": "Person",
"name": "John Reilly"
},
"datePublished": "2014-09-01",
"description": "The most amazing chocolate brownie recipe",
"prepTime": "PT60M"
}
</script>
While structured data is helpful for search engines in general, it can also impact the way your content is rendered inside search results. For instance, let’s search for “best brownie recipe” in Google and see what shows up:
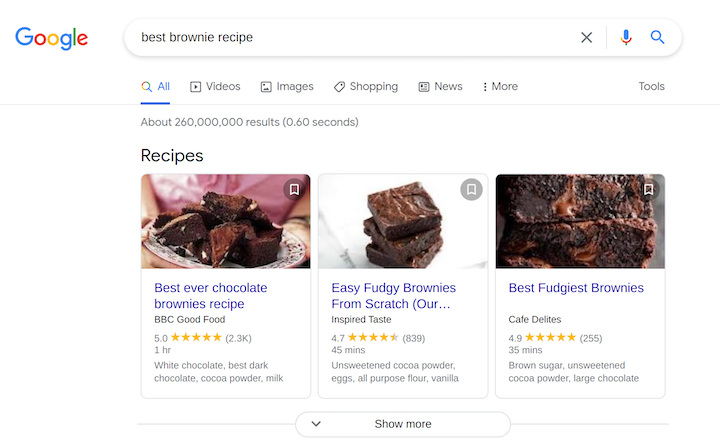
When you look at the image above, you’ll notice that at the top of the list (before the main search results), there’s a carousel that shows various brownie recipe links with dedicated pictures, titles, and descriptions. The carousel has been created by reading structured data from the websites in question.
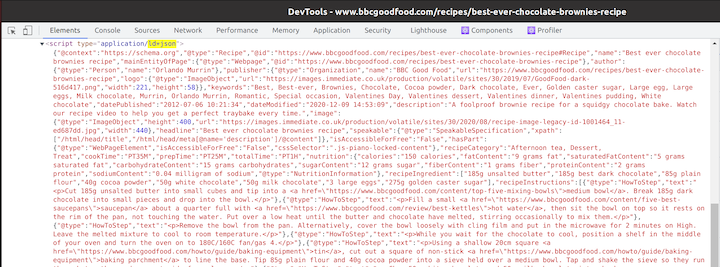
If we click on the first link, we’re taken to the recipe in question. Looking at the HTML of that page, we find a number of JSON-LD sections:
If we grab the contents of one JSON-LD section and paste it into the dev tools console, it becomes much easier to read:
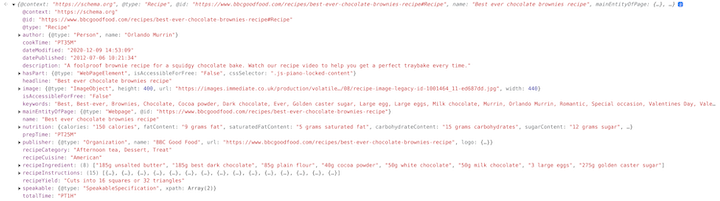
If we look at the @type property, we can see it’s a "Recipe". This means it’s an example of the Recipe schema. And if we look further at the headline property, it reads "Best ever chocolate brownies recipe". That matches up with the headline displayed in the search results.
Now we have a sense of what search engines are using to categorize the page and understand exactly what is powering the carousel in the Google search results.
This carousel is called a rich result, which is a search result that the engine singles out for special treatment when it is displayed. Google provides a Rich Results Test tool that allows you to validate whether your site provides structured data eligible to be featured in rich results. We’ll explore this in detail later.
To see how structured data works in practice, let’s create a React app and add structured data to it.
In the console, execute the following command:
npx create-react-app my-app
We now have a simple React app that consists of a single page. Let’s replace the contents of the existing App.js file with the following:
//@ts-check
import "./App.css";
function App() {
// https://schema.org/Article
const articleStructuredData = {
"@context": "https://schema.org",
"@type": "Article",
headline: "Structured data for you",
description: "This is an article that demonstrates structured data.",
image: "https://upload.wikimedia.org/wikipedia/commons/4/40/JSON-LD.svg",
datePublished: new Date("2021-09-04T09:25:01.340Z").toISOString(),
author: {
"@type": "Person",
name: "John Reilly",
url: "https://twitter.com/johnny_reilly",
},
};
return (
<div className="App">
<script
type="application/ld+json"
dangerouslySetInnerHTML={{
__html: JSON.stringify(articleStructuredData),
}}
/>
<h1>{articleStructuredData.headline}</h1>
<h3>
by{" "}
<a href={articleStructuredData.author.url}>
{articleStructuredData.author.name}
</a>{" "}
on {articleStructuredData.datePublished}
</h3>
<img
style={{ width: "5em" }}
alt="https://json-ld.org/ - Website content released under a Creative Commons CC0 Public Domain Dedication except where an alternate is specified., CC0, via Wikimedia Commons"
src={articleStructuredData.image}
/>
<p>{articleStructuredData.description}</p>
<p>Take a look at the source of this page and find the JSON-LD!</p>
</div>
);
}
export default App;
If we look at the code above, we can see we’re creating a JavaScript object literal named articleStructuredData that contains the data of an article. articleStructuredData is then used to do two things:
<script type="application/ld+json">, which is populated by calling JSON.stringify(articleStructuredData)You might be wondering why we’re using dangerouslySetInnerHTML, and whether we can’t just do this:
<script type="application/ld+json">
{JSON.stringify(articleStructuredData)}
</script>
The difference comes down to the way React escapes quotation characters by default. If you used the approach above, you would still end up with structured data, but it wouldn’t be compatible with all readers, as not all of them can parse escaped quotation marks.
What’s more, while Google can process structured data using the above approach, its parsing is unreliable and results in regular issues. To cut a long story short: we advise you to use dangerouslySetInnerHTML for more dependable results.
When we run our site locally with npm start, we see a simple article site that looks like this:

Now let’s see if it supports structured data in the way we hope.
There are two ways to test your structured data using the Rich Results Test tool: by providing a URL or code. In our case, we don’t have a public-facing URL, so we’re going to use the HTML that React is rendering.
In dev tools, we’ll use the Copy outerHTML feature to grab the HTML, and then we’ll paste it into Rich Results:
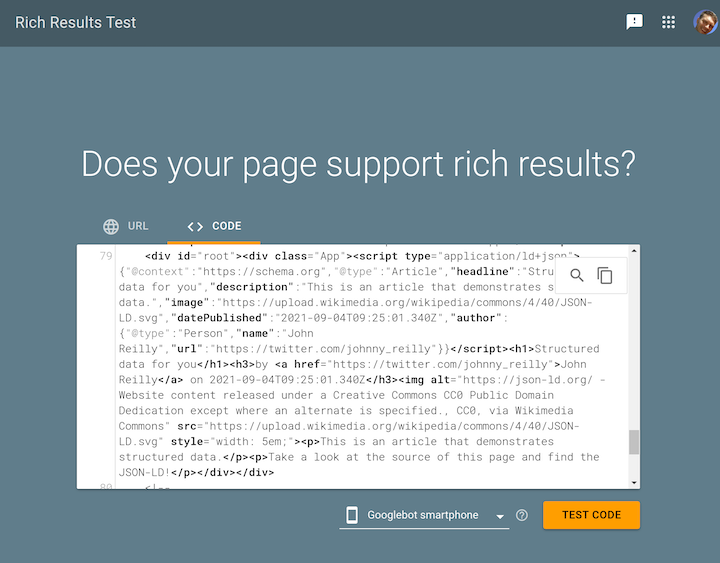
Hit the TEST CODE button and you should see results that look like this:
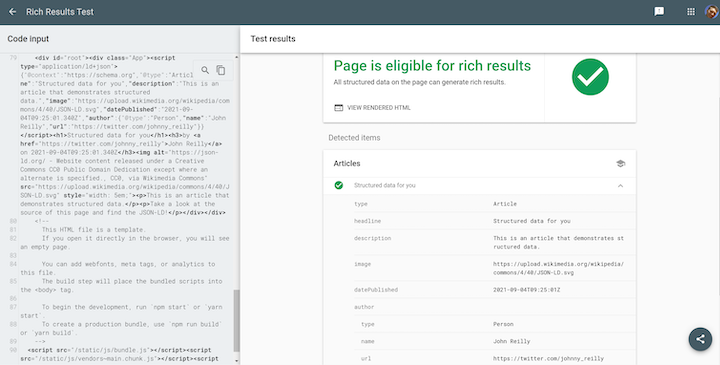
We’ve successfully built a website that renders structured data. More than that, we’re doing it in a way that we know Google will recognize and can use to render rich results in search, which will drive traffic to our website.
If you have structured data that you’d like to render on every screen of your site, and you’re using Docusaurus (a React-based document/blog engine), there’s another option open to you that may be useful.
Docusaurus has a headTags API that I’ve contributed to. It is a general-purpose API and can be used to perform tasks like rendering preload tags for fonts, rendering general meta tags, as well as potentially rendering structured data that is common to all pages of your Docusaurus site.
Below is an example excerpt from my blog site that renders a graph of structured data including the Website, SearchAction, and Person types.
Note that there is nothing Docusaurus-specific about these structured data types; they are example types that can be used to enrich a website. A full gallery of different structured data types can be found on the Schema site. Google also documents how they support structured data:
/** @type {import('@docusaurus/types').Config} */
const config = {
// ...
headTags: [
// ...
// Structured data in the form of JSON-LD
{
tagName: 'script',
attributes: {
type: 'application/ld+json',
},
innerHTML: JSON.stringify({
'@context': 'https://schema.org',
'@graph': [
{
'@id': 'https://johnnyreilly.com',
'@type': 'WebSite',
url,
name: title,
description,
copyrightHolder: {
'@id': 'https://johnnyreilly.com/about',
},
publisher: {
'@id': 'https://johnnyreilly.com/about',
},
potentialAction: {
'@type': 'SearchAction',
target: {
'@type': 'EntryPoint',
urlTemplate: 'https://johnnyreilly.com/search?q={search_term_string}',
},
'query-input': 'required name=search_term_string',
},
inLanguage: 'en-UK',
},
{
'@id': 'https://johnnyreilly.com/about',
'@type': 'Person',
name: 'John Reilly',
alternateName: 'Johnny Reilly',
image: {
'@type': 'ImageObject',
inLanguage: 'en-UK',
'@id': 'https://johnnyreilly.com/about#image',
url: 'https://johnnyreilly.com/img/profile.jpg',
contentUrl: 'https://johnnyreilly.com/img/profile.jpg',
width: 200,
height: 200,
caption: 'John Reilly',
},
description:
'John is an Open Source Software Engineer working on TypeScript, Azure, React, Node.js, .NET and more. As well as writing code, John is a speaker at meetups, one of the founders of the TS Congress conference, and the author of the history of Definitely Typed, which he worked on in the early days of TypeScript.',
url: 'https://johnnyreilly.com',
address: {
'@type': 'PostalAddress',
streetAddress: 'Twickenham',
addressLocality: 'London',
addressCountry: 'United Kingdom',
},
email: '[email protected]',
birthPlace: 'Bristol',
sameAs: [
'https://github.com/johnnyreilly',
'https://fosstodon.org/@johnny_reilly',
'https://twitter.com/johnny_reilly',
'https://dev.to/johnnyreilly',
'https://stackoverflow.com/users/761388/john-reilly',
'https://blog.logrocket.com/author/johnreilly/',
'https://polywork.com/johnnyreilly',
'https://uk.linkedin.com/in/johnnyreilly',
],
},
],
}),
},
],
// ...
};
If you’re running a Docusaurus site, you might find this approach useful.
As a bonus, the eagle-eyed among you will note that this also plugs Google into Docusaurus’ Algolia-based search mechanism with the SearchAction structured data. If Google reads your structured data, this can mean that they have the opportunity to render a dedicated search box embedded in your search results.
In this tutorial, we demonstrated what it looks like to enhance a website by integrating structured data using React. You should be able to apply the same techniques to your sites to facilitate more efficient interactions with users and search engines.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how to build smooth staggered animations in CSS using modern features like sibling-index(), complete with practical examples, fallbacks, and accessibility tips.

Compare the top AI development tools and models of July 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Learn how to detect unused and ghost dependencies in JavaScript projects using Knip, a project-level linter that keeps your dependency graph accurate.

Learn how Storybook MCP enables AI agents to understand your component library, generate accurate UI, and validate code using documentation, stories, and automated tests.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

