Users don’t care where your code runs. They just want to click a link and get to the content without any drama. To them, there’s no “server” or “client.” There are just buttons, tables, cards, and posts that behave the way they expect.

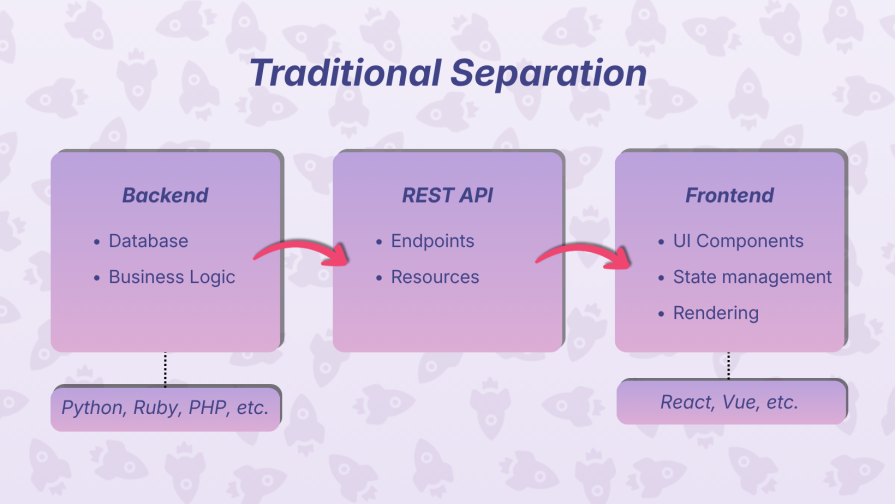
Developers see a very different map. We split the world into frontends and backends. The frontend owns React, JavaScript, CSS, and state. The backend handles Python, Ruby, databases, and business logic. And in between sits the API layer – the translator keeping both sides in sync.
In this article, we’ll dig into why that old separation is starting to feel like the wrong organizing principle, and why composition – not reactivity – is shaping the next wave of UI architecture.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
It wasn’t always two separate worlds. Early on, everything lived on the server. PHP would render your HTML, ship it to the browser, and call it a day. It wasn’t glamorous, but it was straightforward – a single, monolithic flow.
Then JavaScript matured. Single-page apps took over, and React introduced component-driven thinking. Suddenly, we could build rich, interactive interfaces, but most of the work shifted to the client. Pages would load, then fire off requests for the data they needed, raising a new question: where should data actually live?
Backend teams usually push for generic endpoints that can serve any client. Frontend teams want data shaped specifically for the UI. Both sides have good reasons, but they often pull in opposite directions.
As Dan Abramov puts it, REST tends to drift depending on who’s steering the ship. If backend leads, endpoints start mirroring database models. If frontend leads, endpoints bend toward UI needs instead.
Consider the Facebook Like button. Behind the scenes, you probably have a post table and a likes table. Each like is just a row with a user ID, post ID, and timestamp. But what you see in the UI – “Liked by you and 14 others”, is a lot more involved.
To show that single line of text, the system has to:
None of this is raw database data. It’s all view-model data – shaped specifically for the UI.
If the backend team owns the API, they’ll return generic tables or model-shaped responses. Reusable, predictable, but now the frontend has to stitch everything together with multiple requests and extra logic.
If the frontend team owns it, the API will lean toward UI-shaped fields. Easier for the UI today, but fragile – a minor redesign or a new screen can force changes across the API surface.
Either way, one side ends up compromising.
The idea behind BFF is straightforward: add a layer between your REST API and the UI that shapes data for each screen. Instead of the frontend pulling from a handful of generic endpoints and assembling everything itself, the BFF prepares exactly what that screen needs and sends it up in one shot.
So instead of something like:
GET /api/post/123 GET /api/post/123/likes GET /api/users/456
You have:
GET /screens/post-details/123
This endpoint returns everything that the specific screen needs. If the design changes, you update it without affecting others. If the screen gets deleted, the endpoint is also deleted.
Each screen gets its data shaped exactly how it wants. But what if multiple screens need similar data? Do you duplicate logic or have an endpoint per screen? What if you structure by components?
Imagine a PostDetails screen that shows a blog post and a Like button. In a BFF setup, that screen’s endpoint would fetch everything – post content, likes, avatars, and return one neatly packaged JSON response.
But what if the Like button could ask for its own data independently of PostDetails? React Server Components make that possible. The post component can fetch its data from the database, and the Like button can fetch its own like-related data in parallel.
Each component brings along the data it needs, and the client ends up with a fully resolved component tree. That’s composition at the architectural level – every piece self-contained, every piece responsible for its own data. Dan Abramov calls these “impossible components” from a purely client-side point of view.
If you want more of Dan’s thinking around this shift, he breaks it down in his PodRocket episode.
To make the contrast clearer, here’s how both approaches stack up:
| Feature | Backend for frontend (BFF) | React server components (RSC) |
|---|---|---|
| Organization | Screens/Routes – One endpoint per screen. | Components – Each component fetches its own data. |
| Strategy | Single endpoint for all the screen data. | Data is called only where it’s needed (inside the component). |
| Reusability | Shared logic is manually extracted, or code is duplicated across similar screens. | Components bring their own logic. Reusability is natural. |
| Maintenance | When design changes occur, the endpoint is restructured or updated. | Only affected UI components are updated. New endpoints are not required. |
The killer feature of React Server Components isn’t performance – it’s that you can colocate data fetching with the component that needs it, just like props or styles.
Colocation means the data-fetching logic lives right next to the component. Just as you wouldn’t separate a component’s styles into a completely different file system, you shouldn’t separate its data requirements.
Here’s what this looks like:
async function Post({ postId }) {
const post = await getPost(postId); // Data fetching right here
return (
<article>
<h1>{post.title}</h1>
<LikeButton postId={postId} /> {/* Handles its own data */}
</article>
);
}
When a component needs new data, you add it right there. When the component gets deleted, its data-fetching logic goes with it. No hunting through route loaders or Redux actions. Everything is in one place, easy to find and change.
This makes applications easier to reason about. You can see at a glance what data a component needs. The connection is direct, typed, and traceable.
Reactive frameworks focus on what happens when data changes – automatic dependency tracking, efficient updates, fine-grained reactivity.
React Server Components ask a different question: where should the data come from in the first place?
They’re not meant to replace reactivity. Client-side state, reactive updates, optimistic UI – all of that still matters. Server Components simply take over the initial data flow and handle it compositionally across the server–client boundary. The reactive pieces stay on the client, where updates and interactions happen. The two concerns fit together; they’re not trying to solve the same problem.
Traditional reactive systems assume the data is already on the client or fetched separately. RSC starts from a different premise: some components naturally depend on server data, so it builds the architecture around that truth.
As Dan Abramov puts it, the key idea is composition – full-stack components that encapsulate everything they need.
Stop thinking in terms of “this is backend work” and “this is frontend work.” Instead, think: this is a component that happens to need some server data and some client interactivity.
Users don’t see layers. They see a post with a Like button sitting on it. So why not structure your code the same way? That’s what it means to build from the user’s point of view – organize your code around meaningful UI units (posts, buttons, comments) rather than around the server/client divide.
Composition earns its place as the organizing principle because it solves three problems at once:
Reusability – When a component owns its own data fetching, you can drop it anywhere without rewiring half the app
Colocation – The data logic sits right next to the component that needs it – just like props, just like styles. Easy to find, easy to change
Mental clarity – You start thinking of your app as a set of nested, full-stack components. Each one handles its own concerns, and they fit together naturally
And this isn’t a theory. Instagram, Reddit, Uber, Airbnb – they’ve all been using server-driven UI patterns for years. Shipping component trees as JSON is a proven model at massive scale.
The future isn’t about pretending the server and client are the same machine. They’re not. There’s a real gap between them – different execution times, network delays, and the cost of moving data back and forth.
What we can do is build abstractions that make that gap easier to work with. As Dan Abramov explains, React Server Components surface the network boundary as part of the module system itself. You’re not hiding the split; you’re turning it into something compositional.
If you’re starting from scratch, lean into composition from day one. Think vertically – by UI component – instead of horizontally by tech layer. Build components that are self-contained, and use strong typing to connect server and client code without guesswork.
If you already rely on REST APIs, you don’t need to toss anything out. Add a BFF layer that shapes those responses into the view models your UI actually needs. Match its routing to your frontend, and if possible, bring it into JavaScript or TypeScript so you get type safety end-to-end. From there, you can gradually shift the structure toward component-level composition instead of screen-level endpoints.
The bigger shift is in mindset. The user’s mental model – not the backend/frontend divide – is the better way to organize your code. Users see features, not layers.
And reactivity still matters. It’s what keeps the UI responsive when data changes. Client-side state, fine-grained updates, optimistic interactions – none of that disappears.
What reactivity doesn’t solve is the shape of your initial data flow. That’s where composition comes in. It lets you structure data the same way you structure UI: as nested, reusable pieces that work together. The client handles the reactive updates; the composition spans both sides.
The shift toward composition isn’t about throwing out reactivity or rewriting your stack. It’s about building UIs the way users experience them – as coherent pieces, not layers. When components handle their own data and logic, the whole system becomes easier to evolve. That’s the direction modern UI architecture is heading, and the teams that embrace it will move faster and with more clarity.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 25th issue.

Discover a practical framework for redesigning your senior developer hiring process to screen for real diagnostic skill.

I tested the Speculation Rules API in a real project to see if it actually improves navigation speed. Here’s what worked, what didn’t, and where it’s worth using.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

