There are two approaches to creating a GraphQL server: the SDL-first approach, and the code-first approach, which each have benefits and drawbacks. And there are two types of directives: schema-type directives (such as @deprecated), which are declared on the schema via the SDL; and query-type directives (such as @include and @skip), which are added to the query in the client.

One of the drawbacks of the code-first approach is that, because it doesn’t have an SDL, it can’t naturally support schema-type directives. A code-first server could provide the alternative to declare schema-type directives via code instead of the SDL. However, the maintainers of graphql-js (which is the reference implementation for GraphQL) have decided to not support registering directives via code.
As a consequence, code-first servers depending on graphql-js may be unable to offer features that depend on these directives unless they find some workaround. For instance, Nexus can’t be integrated with Apollo Federation, which requires you to define a @key directive on the schema.
But other GraphQL servers do not need to emulate graphql-js in this respect and may offer support to declare schema-type directives via code. After all, the GraphQL spec does not concern itself with how directives are to be implemented.
In this article, I’ll describe the strategy I’ve implemented for Gato GraphQL (the code-first GraphQL server written in PHP that I authored) to provide support for schema-type directives via code.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
@deprecated is a schema-type directive, so it must be applied on the schema. However, what would happen if we pretend for a moment that it is a query-type directive and add @deprecated on some field directly in the query?
For instance, when executing this query:
query {
posts {
id
title
content @deprecated(reason: "Use newContent instead")
}
}
Well, it would work, too! Because, after all, a directive is just some functionality to execute on the field; declaring that functionality via the schema, or directly in the query, does not make the functionality behave any different.
The thing is that, even though it works, it doesn’t make any sense; you can’t force your clients to add @deprecated to their queries. This is functionality decided by the application on the server side, not on the client.
However, the takeaway is that the functionality itself still works. Hence, whether the directive is added to the schema or to the query doesn’t matter from a functional point of view. Moreover, every directive will eventually end up being present in the query since that’s where it is executed.
Thus, if we don’t have an SDL, we can still embed the directive into the query on runtime.
In the article Treating GraphQL directives as middleware, I described the directive pipeline, an architecture that enables the server’s engine to resolve, validate, and execute the query. In order to make the engine as simple as possible, every action concerning the resolution of the query takes place within the pipeline through directives.
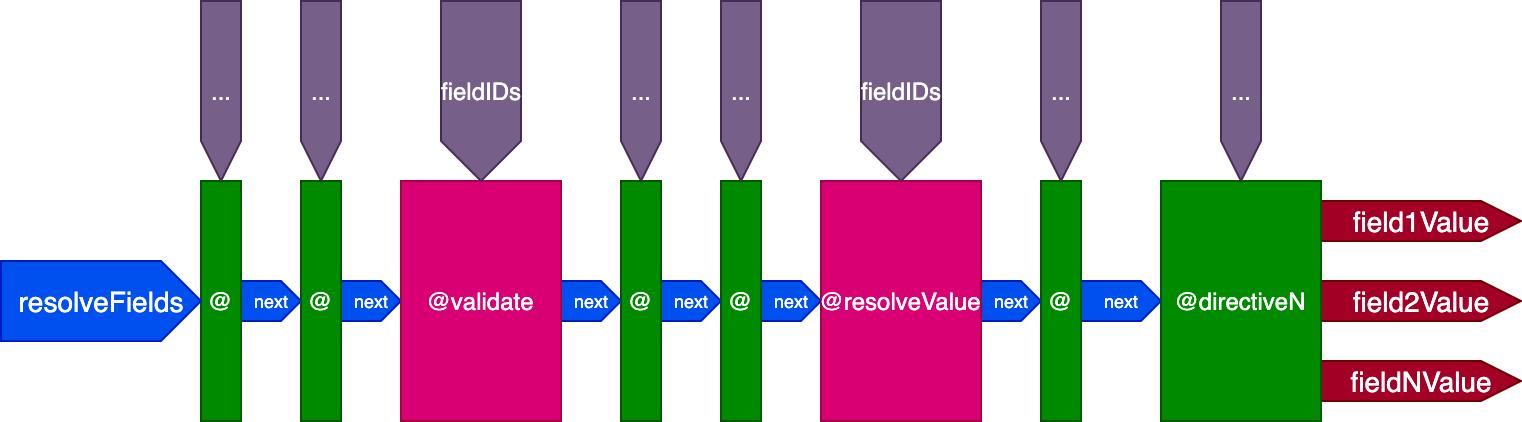
Calling the resolver to validate and resolve a field, and merge its output into the response, is accomplished through a couple of special directives: @validate and @resolveValueAndMerge. These directives are of a special type; they are not added by the application (on either the query or the schema) but by the engine itself. These two directives are implicit, and they are always added on every field of every query.
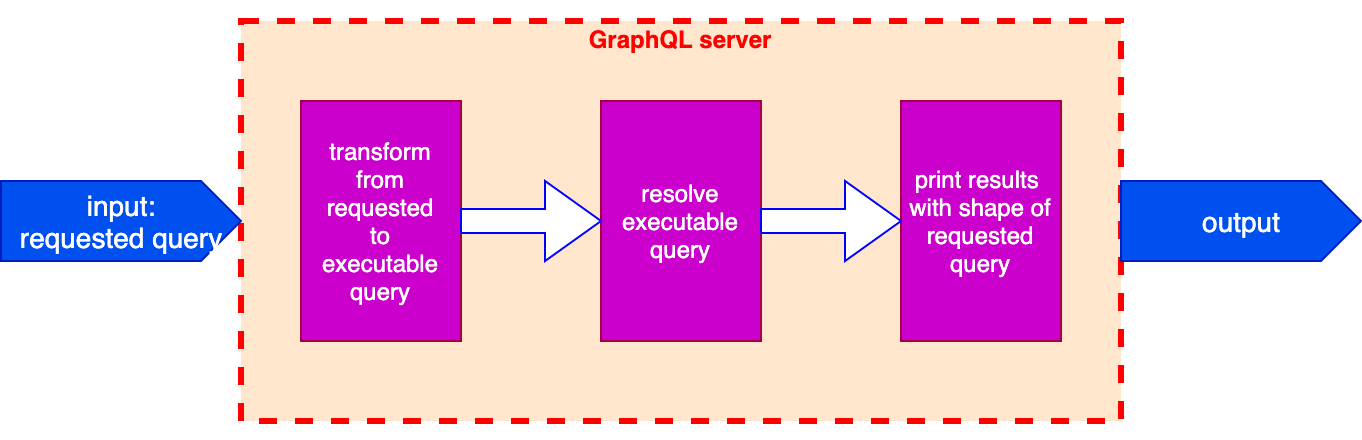
From this strategy, we can see that when executing a query on the GraphQL server, there are actually two queries involved:
The executable query, which is the one that’s ultimately resolved by the server, is produced from applying transformations on the requested query, among them the inclusion of the directives @validate and @resolveValueAndMerge for every field.
For instance, if the requested query is this one:
{
posts {
url
title @uppercase
content @include(if: $addContent)
}
}
The executable query will be this one:
{
posts @validate @resolveValueAndMerge {
url @validate @resolveValueAndMerge
title @validate @resolveValueAndMerge @uppercase
content @validate @include(if: $addContent) @resolveValueAndMerge
}
}
Indeed, we can transform the query to add any directive, not only the special-type ones. This way, even though there is no SDL, we can still insert a @deprecated directive in the field on runtime.
As a side note, decoupling the query into requested and executable instances has other potential uses. For instance, it could provide a solution for the flat chain syntax issue to resolve a shortcut programs.shortName into an array of the strings (["name1", "name2", ...]) instead of an array of objects ([{shortName: "name1"}, {shortName: "name2"}, ...]) through these steps:
programs.shortName from the requested query into the corresponding connection programs { shortName } in the executable query@copyConnectionDataUpwards@flatten directiveprograms.shortNameNext, we must produce a mechanism to tell the server when and how to add the directives onto the query. The mechanism I’ve developed is based on the concept of IFTTT (if this, then that), and I’ve called it IFTTT through directives.
In general, IFTTT are rules that trigger actions whenever a specified event happens. In our situation, the pairs of event/action are:
How do we add directives to the schema via IFTTT? Say, for instance, we want to create a custom directive @authorize(role: String!) to validate the that user executing field myPosts has the expected role author, or show an error otherwise.
If we could work with the SDL, we would create the schema like this:
directive @authorize(role: String!) on FIELD_DEFINITION
type User {
myPosts: [Post] @authorize(role: "author")
}
The IFTTT rule defines the same intent that the SDL above is declaring: whenever requesting field myPosts, execute directive @authorize(role: "author") on it.
Being coded in PHP, this rule for GraphQL by PoP looks something like this:
$iftttManager = IFTTTManagerFacade::getInstance();
$iftttManager->addEntriesForFields(
'authorize'
[
[RootTypeResolver::class, 'myPosts', ['role' => 'author']],
]
);
Now, whenever field myPosts is found on the query, the engine will automatically attach @authorize(role: 'author') to that field on the executable query.
IFTTT rules can also be triggered when encountering a directive, not just a field. For instance, rule “whenever directive @translate is found on the query, execute directive @cache(time: 3600) on that field” is coded like this:
$iftttManager = IFTTTManagerFacade::getInstance();
$iftttManager->addEntriesForDirectives(
'translate'
[
['cache', ['time' => 3600]],
]
);
Adding IFTTT directives to the query is a recursive process: it will trigger a new event to be processed by IFTTT rules, potentially attaching other directives to the query, and so on.
For instance, rule “Whenever directive @cache is found, execute directive @log” would log an entry about the execution of the field, and then trigger a new event concerning this newly added directive.
An interesting side effect of using the IFTTT approach to execute functionality through directives is that instead of hardcoding a directive into the schema, which is suitable for executing predetermined actions, we can now add directives through configuration, which is suitable for making the API more flexible.
We could conveniently invoke actions from plug-and-play third parties, for example, or grant our users (not just our developers!) the chance to modify the behavior of the service.
For instance, for the GraphQL by PoP-powered GraphQL API for WordPress I have built an interface for users to configure what access control rules are applied on the schema:
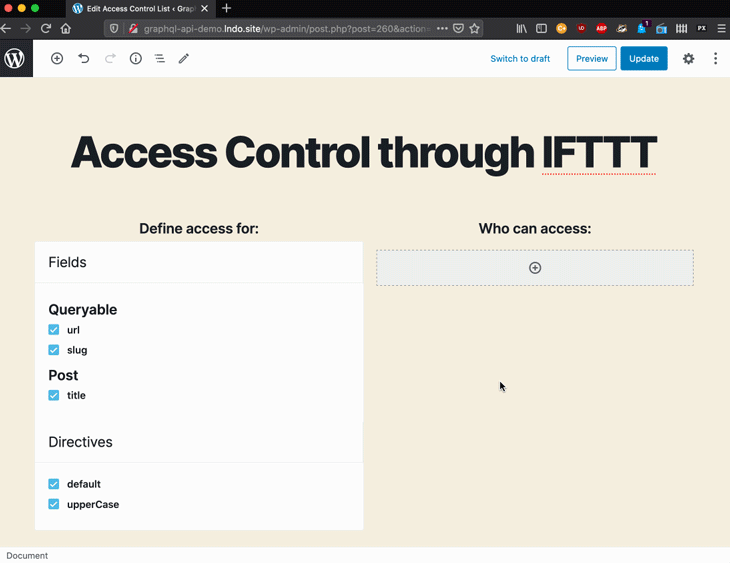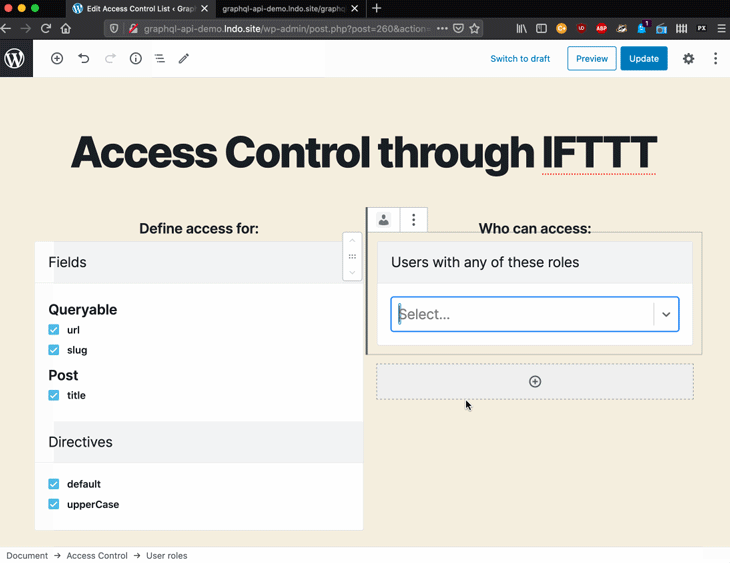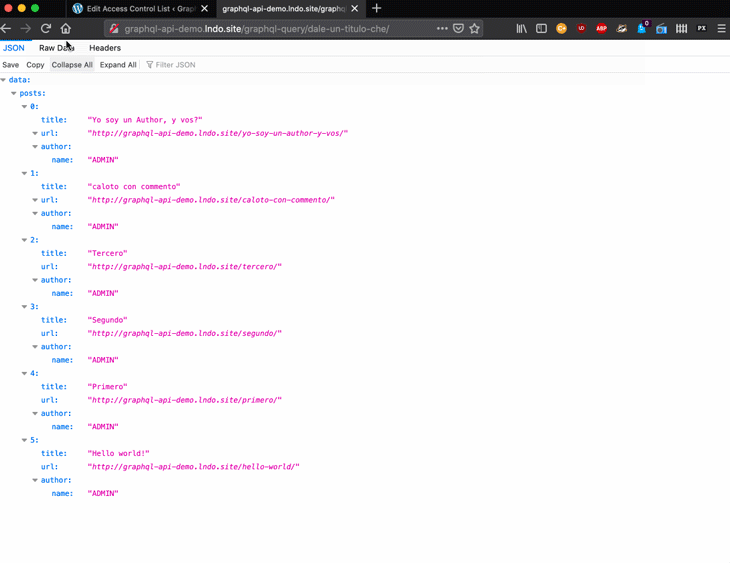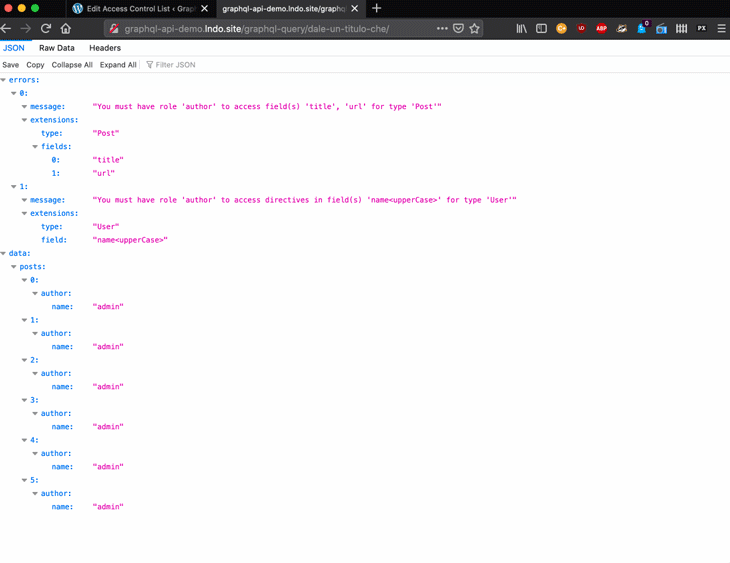
The engine is executing a chain of directives on the field, but it doesn’t know in advance which directives to execute. These are defined by the user through the interface and are consequently stored as IFTTT rules.
Some possible directives from third parties to be plugged into the service through configuration could be:
createPost, send a notification to the user via email/SlackforgotPassword, send SMS for 2FA, if enabledaddComment on a static Jamstack site, execute a webhook to regenerate the siteuploadImage, invoke a cloud service to compress the imageimageSrc through a CDNAs we’ve seen, we can add directives to our query on runtime through coded IFTTT rules, in this way bypassing the SDL. But this alone is not enough to build a versatile schema.
For instance, say that our site is in English, and we need to translate it to French. We can then create rule “Whenever requesting fields Post.title and Post.content, attach directive @translate(from: "en", to: "fr") to the field.”
Now, whenever requesting this query:
{
posts {
id
title
content
}
}
The server will execute this query:
{
posts {
id
title @translate(from: "en", to: "fr")
content @translate(from: "en", to: "fr")
}
}
So far, so good. But then, what happens if we want to retrieve the data without any processing, back in English? Now we can’t do it anymore because fields Post.title and Post.content will always have the directive @translate attached to them.
The solution is to create field aliases, but on the server side (the concept of field aliases on GraphQL is executed on the client, not on the server). Then, we can create the following field aliases:
Post.title => Post.frenchTitlePost.content => Post.frenchContentA field and its aliases are all available in the schema and are resolved exactly the same way by the resolver, hence both Post.title and Post.frenchTitle will be resolved as "Hello world!". But then, we can define the IFTTT rule on the aliased fields only so that only the aliased fields are translated to French:
$directiveArgs = ['from' => 'en', 'to' => 'fr'];
$iftttManager = IFTTTManagerFacade::getInstance();
$iftttManager->addEntriesForFields(
'translate'
[
[PostTypeResolver::class, 'frenchTitle', $directiveArgs],
[PostTypeResolver::class, 'frenchContent', $directiveArgs],
]
);
Now, this query:
{
posts {
id
title
frenchTitle
content
frenchContent
}
}
Will be executed by the server like this:
{
posts {
id
title
frenchTitle @translate(from: "en", to: "fr")
content
frenchContent @translate(from: "en", to: "fr")
}
}
In the same way, we can create directive aliases.
This section is a side note, to show how aliases on the server-side can have other great uses too.
In the article Versioning fields in GraphQL, I described how we can provide field- or directive-based versioning for our schema (as contrasted with evolving the schema), where we pass a field (or directive) argument versionConstraint to indicate which version of the field to use.
Field aliases can be a convenient mechanism to expose all versions of the fields in the schema; we could “tag” an alias to a specific version of a field, like this:
Post.v1Title => Post.title(versionConstraint: 1.2.5)Another use is to avoid having to namespace custom directives, a practice recommended by the spec:
When defining a directive, it is recommended to prefix the directive’s name to make its scope of usage clear and to prevent a collision with directives which may be specified by future versions of this document (which will not include
_in their name). For example, a custom directive used by Facebook’s GraphQL service should be named@fb_authinstead of@auth.
The issue with this practice is that it makes the schema ugly, where @fb_auth is not as elegant as the simple @auth. Even worse, it is not 100 percent reliable in avoiding conflicts since companies may use the same namespace to identify themselves. For instance, a library offering directive @fb_auth may be produced not just by Facebook, but also by Google’s Firebase.
An alternative solution offered by aliases is to generate an aliased version of the directive only when the conflict actually arises.
For instance, if we are using directive @auth provided by Facebook, and we later on also need to use directive @auth provided by Firebase, only then would we create aliases for them, such as @fb_auth and @g_fb_auth.
It is true that the possibility of breaking changes with this strategy, in theory, goes up: if we call the directive @auth and then the GraphQL spec mandates that @auth is a spec-required directive (such as @include and @skip), then namespacing our directive will not be enough; we must also change the queries to use the new, namespaced name.
But what are the chances of this situation actually happening? Given the favor no change guideline to modify the spec, and the reticence to introduce official directives (other than a potential few exceptions, such as @stream, @defer, and maybe @export), the chances of coming across a naming conflict are pretty much nil.
With directive aliases, our schema can be elegant and legible by default, and namespacing is introduced only in the slight chance it is ever needed, and not always.
By now, you might have concluded that I love directives. If that’s the case, you are right. In my opinion, directives are among the most powerful features of GraphQL, and I believe that providing good access to them should be one of the top priorities of any GraphQL server.
In this article, I have described how code-first servers (which have no SDL) can manage to provide support for schema-type directives. The idea is simple: instead of defining them on the schema, attach them to the query, on runtime, through IFTTT rules. This is certainly not the only way to do it, but that’s how I have implemented it for my GraphQL server, and it works pretty well.
This article is part of an ongoing series on conceptualizing, designing, and implementing a GraphQL server. The previous articles from the series are:
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to build a full React Native auth system using Better Auth and Expo — with email/password login, Google OAuth, session persistence, and protected routes.

Compare the top AI development tools and models of June 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Learn how Bloom filters reduce database lookups for username availability checks while preserving correctness at scale.

Learn how to test Nuxt apps with Vitest, @nuxt/test-utils, runtime mocks, server route mocks, and Playwright e2e tests.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

