Research, as we know, is the backbone of any design team. The better the research outcomes are, the better the product will become. Unfortunately, though, design departments are not always allotted generous funding and time to carry out elaborate research studies.

How do we get the most out of our research to create UX designs people love?
The answer lies in the study design — specifically, understanding the differences between within-subjects and between-subjects designs. These two research methods can shape your findings in drastically different ways. And which one should you choose for your next UX study?
That’s what this article is about — within vs. between-subjects. I’ll break down the differences between within-subjects and between-subjects research designs in UX, explain when each method is most useful, and provide guidance on choosing the right approach for your study. Understanding these research techniques will help you gather valuable insights for creating better user experiences.
Being informed on effective research study design can equip even resource-constrained design teams to be extremely effective at developing lovable product experiences. And the ability to deliver results with less, you’d know, is both impressive and desirable for lean teams.
The largest factor in research data collection is the participant pool.
The most common way of engaging participants is typically asking low-effort questions to as many relevant participants as possible. This, for instance, can be experienced when we complete an action on an application and it asks us for a simple rating of our experience.
But to gain more informed insight into why something is working or not working, we need to engage our users in a more detailed interview or experiment. In such cases, we either have to offer some incentive so they feel motivated to participate or rely on a large pool that it distills down to a few who are willing to do it for free. And we have to keep in mind their willingness to provide genuine answers.
In-person UX user interviews or even video-conferenced interviews are generally better to ensure that users are providing genuine feedback and conduct it in a manner where the respondent does not feel obliged to provide positive feedback.
Since a lot of time and resources go into our research study — we have to ensure we design it in a manner that allows for the most useful data collection.
The participant pool we have decided on is precious, and how we conduct the study is crucial. One of the biggest considerations in presenting our design variations to our participant pool is either within-subjects or between-subjects:
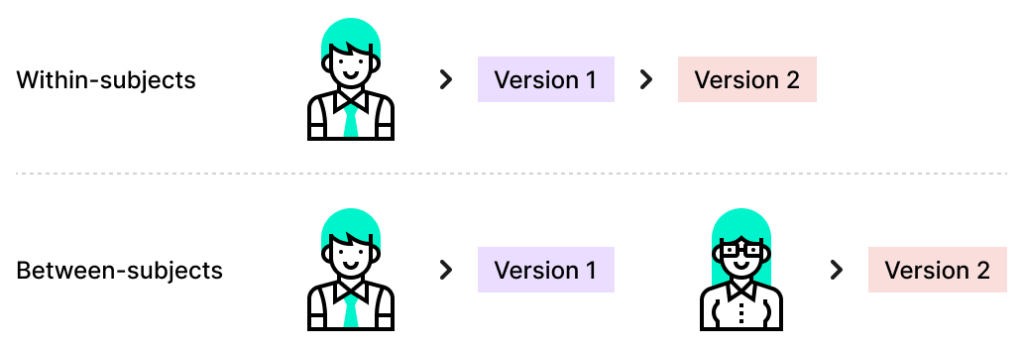
A within-subjects study means that the same participants experience multiple conditions or variations of a design. In UX research, this could involve showing users different versions of a landing page or testing multiple navigation structures within a single session.
Since each participant interacts with all variations, the main advantage is that individual differences (such as prior experience, personal preferences, or cognitive abilities) don’t skew the results. This can lead to more statistically powerful findings because you’re comparing a person’s responses against their own baseline rather than against another group.
I’ll discuss a quick example.
Imagine you’re testing two different checkout flows for an ecommerce site. In a within-subjects study, each participant would go through both flows — one after the other — and provide feedback on each. This lets you directly compare their experiences, helping identify which flow feels more intuitive or efficient.
However, this method introduces potential carryover effects — where exposure to the first variation influences how participants interact with the second. If a user gets frustrated with the first checkout flow, they may be biased in their perception of the second, even if it’s better designed.
To counteract this, researchers use counterbalancing, meaning half the participants start with version A, and the other half start with version B. This minimizes order effects and ensures that insights reflect actual user preferences rather than the influence of sequence.
In a between-subjects study, participants are divided into separate groups, with each group experiencing only one version of the design. This prevents learning effects or bias caused by repeated exposure but requires a larger sample size to achieve meaningful results.
I’ll take an example.
Let’s revisit the checkout flow study. Instead of asking the same users to test both flows, a between-subjects study would randomly assign participants to one of the two versions. Group A would only experience the first checkout flow, while Group B would only experience the second.
Because participants are only exposed to one variation, this method more closely simulates real-world usage. However, individual differences among participants (such as tech-savviness or shopping habits) can introduce variability in responses, making it harder to isolate the impact of design changes.
Both approaches have their place in UX research. Your choice will depend on factors such as the research question, available resources, and potential biases.
| USE A WITHIN-SUBJECTS DESIGN IF | AVOID A WITHIN-SUBJECTS DESIGN IF |
| ✅ You want to compare multiple variations using a small participant pool | ❌ The study involves tasks where learning effects would significantly influence performance (e.g., onboarding experiences, educational platforms) |
| ✅ The task is simple, and order effects can be controlled (e.g., testing different button placements) | ❌ The interaction involves mental or physical fatigue, which could affect how participants engage with later variations |
| ✅ Individual differences could significantly impact the results, and you want to control for them | |
| ✅ You need higher statistical power with fewer participants |
| USE A BETWEEN-SUBJECTS DESIGN IF | AVOID A BETWEEN-SUBJECTS DESIGN IF |
| ✅ You need a realistic user experience where participants interact with just one version, as they would in the real world | ❌You’re allotted limited resources — between-subjects studies require larger sample sizes, increasing costs and time needed to gather significant insights |
| ✅ The differences between variations are large (e.g., testing two entirely different UI layouts) | |
| ✅ There’s a risk of carryover effects where experiencing one variation influences how users interact with the next | |
| ✅ You have the resources to recruit more participants |
When running A/B tests at scale, especially in live environments, user cohorts play a crucial role in ensuring reliable results.
A between-subjects design is the foundation of most large-scale A/B tests, where users are randomly assigned to different variations:

By analyzing performance across different user cohorts, teams can detect hidden patterns that a standard A/B test might overlook. For instance, while a new checkout design may improve conversion rates overall, it might negatively impact power users accustomed to the old flow.
While between-subjects designs are easier to execute because they don’t require randomizing task order, within-subjects studies are more complex. The challenge comes with balancing the order of variations.
A technique called Latin Square can help ensure every possible order is equally balanced within your participant pool:
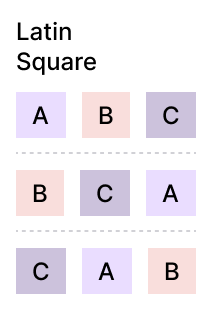
But, as the number of design variations grows, this becomes more challenging.
For instance, if you’re testing 4 variations (A, B, C, D), you’ll need a 4×4 matrix. The number of unique combinations grows quickly as more variations are added, and with each additional variation, the need for more participants increases to maintain balance across all combinations.
T-tests and ANOVA (Analysis of Variance) are statistical methods used to analyze the results of within-subjects and between-subjects UX studies. They help determine whether observed differences in user behavior, preferences, or performance are statistically significant rather than due to random chance.
A t-test is often used in A/B testing to compare two groups, such as the control group (A) and the treatment group (B). It tells you whether the observed difference in outcomes between these groups is statistically significant or if it occurred by random chance.
Since within-subjects studies involve the same participants experiencing multiple conditions (e.g., testing two different UI layouts), a paired t-test is used to compare the data. This test accounts for individual differences because each participant serves as their own baseline.
Say you’re to test two button placements on the same group of users and record task completion times. A paired t-test determines whether the difference in completion times is significant.
In a between-subjects study, different participants experience different conditions. A two-sample (independent) t-test is used to compare the means of these two groups.
If Group A tests one version of a signup form and Group B tests another, an independent t-test determines if one form significantly improves completion rates over the other.
If you’re testing more than two variations (e.g., A/B/C testing), ANOVA (Analysis of Variance) is the tool you’ll want to use. ANOVA helps you compare the means of three or more groups to see if at least one differs significantly from the others.
Used when the same participants experience three or more conditions. It analyzes whether the differences between multiple variations are statistically significant while accounting for individual differences.
Say you’re testing three onboarding flows (A, B, and C) with the same participants. A repeated-measures ANOVA determines if one flow significantly outperforms the others.
Used when comparing three or more independent groups, where each group experiences only one version of the design.
If you’re testing three different home page layouts on three separate groups of users, a one-way ANOVA tells you if at least one layout performs significantly differently.
While both t-tests and ANOVA are essential for analyzing A/B test results, the choice between the two depends on the number of variations you’re testing. If you have two, go with a t-test. If you have more than two, ANOVA is your best option.
Here’s what you should take away:
| STATISTICAL TEST | DESIGN TYPE | WHEN TO USE |
| Paired T-test | Within-subjects | Comparing two conditions for the same participants |
| Independent T-test | Between-subjects | Comparing two groups with different participants |
| Repeated measures ANOVA | Within-subjects | Comparing three or more conditions for the same participants |
| One-way ANOVA | Between-subjects | Comparing three or more groups with different participants |
Choosing the right research design has made a huge difference in my UX work. Within-subjects studies save time and require fewer participants, but I’ve learned the hard way that carryover effects can skew results. On the flip side, between-subjects designs feel more natural but demand larger samples.
For analysis, I rely on paired t-tests when comparing the same users across conditions and independent t-tests for group differences. When testing multiple variations, ANOVA has been a lifesaver.
Getting these choices right has helped me turn raw data into real UX impact.

LogRocket's Galileo AI watches sessions and understands user feedback for you, automating the most time-intensive parts of your job and giving you more time to focus on great design.
See how design choices, interactions, and issues affect your users — get a demo of LogRocket today.

Explore the core principles of GUI design and learn how consistency, simplicity, feedback, accessibility, and user testing contribute to better digital experiences.

After five years in UX, I revisited the Daily UI challenge to reconnect with hands-on design. Along the way, I learned that great interfaces come from thoughtful briefs, sound judgment, and user feedback, not just better AI tools.

Learn what makes a great login screen through real-world examples and UX best practices for creating secure, accessible, and low-friction authentication flows.

Skeuomorphism helped define early digital interfaces by mimicking real-world objects to make technology more intuitive. Learn how it compares with flat design and neumorphism, why it declined, and where it still has a place in modern UX.


