Proper file type identification is often required in many lines of work today. Web browsers must decide how to render files based on their file format, security scanners must inspect uploaded content, and data processing pipelines extract value from diverse datasets. In all these cases, reliable file type detection is essential.

Nonetheless, existing approaches such as examining file extensions or using static definitions of “magic” byte signatures are highly restrictive. They don’t consider factors like file obfuscation and malicious files, complex multi-part formats, compressed or encoded data, and more.
Here is where Magika, a new AI-powered solution developed by Google, comes in. Magika offers extremely accurate file type identification. Using recent deep learning developments, Magika takes a different approach and addresses the limitations of traditional file type detection methods.
Determining a file’s actual type just by looking at its extension — i.e., .pdf, .docx, etc. — is one of the most unreliable methods out there! It’s very simple to modify extensions, but unfortunately, most (if not all) applications trust them blindly. This allows bad actors to easily bypass extension-based validations.
A more reliable method is to check for “magic” byte signatures or headers, but this approach is still flawed. It’s limited by the hard-coded rules regarding what a valid signature is, and it can’t go beyond generalized definitions.
Furthermore, it’s possible to bypass byte signature detections by specific obfuscation approaches, such as cramming random data before the real payload. This fairly common trick can enable malware to slip past security measures.
Safely and accurately identifying the type of file is essential for many applications, such as web browsers, antivirus software, and mail filters. If there were a flaw in the file type detection method, a clever hacker would be able to take advantage of it, so hard rules are not the general solution.
Enter Magika.
Magika is a file identification tool built by Google using deep learning models trained on a set of more than 25 million files over 100 different file types. It’s different from your standard file identification system, which works primarily based on the file extension. Magika reads the whole content and structure of the file to determine what kind of file it is.
At the heart of Magika is a custom neural network model built, trained, and optimized for one purpose: detecting file types. This super-accurate model has actually been distilled down to only 1MB of data using quantization and pruning.
Magika’s small footprint allows it to run efficiently, even on low-end devices using the CPU. Although its bundle size is small, Magika has impressive accuracy — Google reports that on a variety of file formats, the tool attains over 99 percent precision and recall.
One interesting and useful feature is that Magika can also determine textual file types, such as source codes, markup languages, or configuration files. These files generally provide less clear headers or signatures and are very hard to detect with traditional tools.
Under the hood, Magika uses deep learning models that are specifically built, trained, and fine-tuned to identify file types.
The core model architecture for Magika was implemented using Keras, a popular open source deep learning framework that enables Google researchers to experiment quickly with new models.
To train this kind of deep-learning model, you would need a dataset large enough to capture the wide variance in file types. Google put together a special training dataset consisting of 25 million files covering over 100 file types and formats, ranging from binary images and executable files to text files.
The quality and representativeness of the training data were important for Magika’s models to learn correctly from the complex patterns and structures shown by each file type. Such a diverse dataset would typically be impossible to get at scale and time-consuming to put together manually.
To perform fast inference at runtime, Magika uses the cross-platform Open Neural Network Exchange (ONNX) runtime. ONNX provides a method to optimize, accelerate, and deploy models built using any of the popular frameworks consistently, even across different hardware platforms or instruction set architectures.
This enables Magika to detect different file types in a few milliseconds, similar to other non-AI tools, which use byte signature scanning techniques. Magika, however, achieves this level of performance by taking advantage of more profound and intelligent deep learning models with substantially higher accuracy.
Magika’s small 1MB optimized model size is crucial to ensuring that it can run efficiently on low-end devices containing basic CPUs, and doesn’t require powerful GPUs or specialized AI accelerators.
As we’ve discussed, detecting the file type a user uploads is common in modern web applications. Language detection is necessary for code editors to set the correct language mode and use proper syntax highlighting for a file based on its content.
Let’s build a simple file upload component with Next.js to demonstrate how to integrate Magika into a React application for such use cases. You can check the full project code on GitHub and follow along as we build our project.
First, we’ll go over the setup steps using create-next-app and installing the required dependencies. Start by creating a new Next.js app:
> npx create-next-app@latest magika-react-demo > cd magika-react-demo
This will create a new Next.js app named magika-react-demo and navigate into the project directory. Next, install dependencies:
> npm install @monaco-editor/react magika
Here, we’re installing @monaco-editor/react, which is the Monaco Editor for React, along with the magika library for file type detection.
With these steps completed, you should have a new Next.js app with the required dependencies, including the Magika library. You can now integrate Magika with your React components and leverage its file-type detection capabilities within your application.
The following Next.js page component — src/app/page.js — manages the file upload process and renders the code editor:
// src/app/page.js
"use client";
import { useState } from "react";
import Editor from "@monaco-editor/react";
export default function Home() {
const [currentLanguage, setCurrentLanguage] = useState("");
const [fileContent, setFileContent] = useState("");
const handleFileUpload = async (event) => {
// ...
};
return (
<main className="App">
<div>
<p>Current Language: {currentLanguage || "plain text"}</p>
<p>
<input type="file" onChange={handleFileUpload} />
</p>
</div>
<Editor
height="500px"
language={currentLanguage}
value={fileContent}
theme="vs-dark"
/>
</main>
);
}
We start by importing the necessary dependencies:
useState Hook from React for managing component stateEditor component from the @monaco-editor/react library, which provides an interface of the Monaco Editor with ReactInside the Home component, we initialize two state variables using the useState Hook:
currentLanguage: This will store the detected language of the uploaded file, which will be used to set the language mode in the Monaco EditorfileContent: This will store the contents of the uploaded file, which will be displayed in the Monaco EditorIn the component, we display the current language (or “plain text” if no language is detected yet) and render a file input field that calls the handleFileUpload function when a file is selected:
const handleFileUpload = async (event) => {
const file = event.target.files[0];
if (!file) return;
const formData = new FormData();
formData.append("file", file);
setFileContent("Loading...");
const response = await fetch("/api/upload", {
method: "POST",
body: formData,
});
const data = await response.json();
setFileContent(data.content);
if (data.language) setCurrentLanguage(data.language);
};
Whenever a file is selected in the file input, the handleFileUpload first gets the selected file from the event.target.files array. Next, we create a new FormData object and append the selected file to it. This is required because we’ll be sending the file to the server via a fetch request.
We then send a POST request to the /api/upload route on our server, passing the FormData object containing the file as the request body.
Once we have the response data, we update the fileContent state with the actual file contents received from the server. Additionally, if the server response includes a detected language, we update the currentLanguage state with that value.
At this point, your UI should look as shown below:
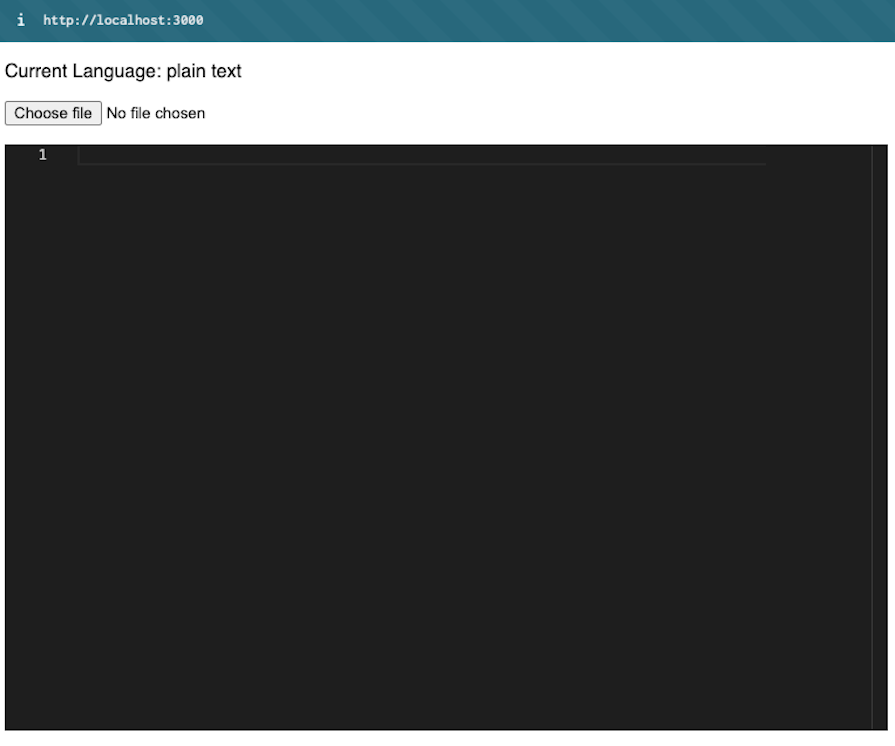
The API route — /api/upload — handles the file upload, uses Magika to detect the file type, and returns the content along with the predicted language:
// src/app/api/upload/route.js
import { NextResponse } from "next/server";
import { Magika } from "magika";
export async function POST(request) {
const formData = await request.formData();
const file = formData.get("file");
if (!file) {
return NextResponse.json({ error: "No file uploaded" }, { status: 400 });
}
const fileContent = await file.text();
const fileBytes = new Uint8Array(await file.arrayBuffer());
const magika = new Magika();
await magika.load();
const prediction = await magika.identifyBytes(fileBytes);
return NextResponse.json({
content: fileContent,
language: prediction?.label,
});
}
First, we extract the uploaded file from the request’s FormData. We then convert the file into a Uint8Array of bytes, as required by Magika’s identifyBytes method.
Next, we instantiate the Magika class, load the detection model, and pass the file’s byte array to identifyBytes method. It returns an object containing the detected file type’s label (e.g., python, javascript, etc.).
In the end, we return the file’s content and the predicted language label to the client. The detected language is then used to dynamically set the Monaco Editor’s language mode, providing proper syntax highlighting and language services based on the uploaded file’s contents.
You can check in the following screenshot how the Java file is rendered by the editor with proper syntax highlighting:
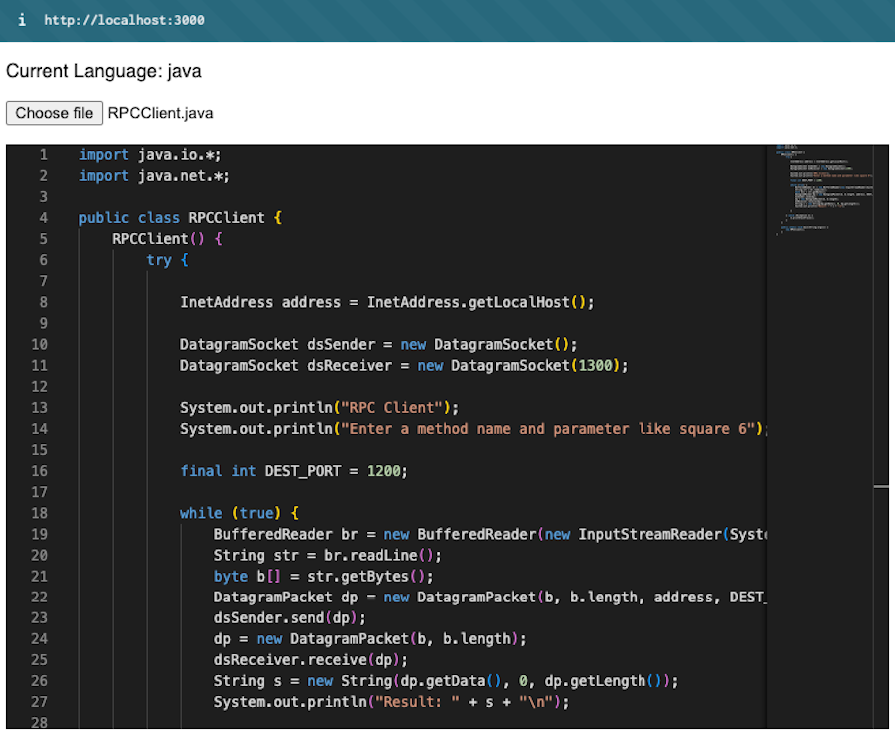
While Magika broke into the file type detection space with the new AI-powered approach, some libraries are already out there solving this exact same problem using more conventional techniques. A couple well-known examples are file-type and mime-types.
file-type is a lightweight library for checking file types based on the header. It’s designed to run in Node.js and browser environments and provides a simple way of detecting file types from Buffers, files on disk, streams, and Blobs.
The file-type library can determine a file’s file type by looking for known “magic number” byte signatures in its header. It can detect various binary file formats, such as images, audio, video, archives, and more. However, it’s mostly oriented to binary formats and doesn’t generalize well to text-based formats such as source code files.
The magic number method used by the file-type library is flexible but has some disadvantages. Its fixed rules constrain it and can be evaded using malformed or obfuscated files. Its accuracy will always be inherently limited when compared to Magika’s AI model, which is trained to understand the correct file structure and content.
The mime-types library maps file extensions to associated MIME types, and it is often used in web servers and HTTP tools. It keeps a list of extensions — like .html or .png — and the MIME content types they correspond to.
However, mime-types uses only extension mappings. It can only accurately detect a file’s actual type if the extension is correct, obfuscated, or missing. This makes it very easy for bad actors to bypass.
Both the file-type and mime-types libraries take traditional rules-based approaches using byte signatures and extension mappings. They’re simple and effective for common usage but lack the “smart” features provided by Magika’s API.
On the other hand, Magika is based on state-of-the-art deep learning models trained on a large dataset to understand the structure and semantics of files in depth. It’s able to accurately identify file types instantly, even obfuscated, malformed, or compound files that routinely defeat rule-based methods.
Furthermore, you can’t afford mistakes in certain crucial use cases, such as security scanning or data processing. File type libraries built on simple rules won’t be able to compete with the AI-driven architecture that Magika offers.
Sure, Magika does come with its share of limitations and tradeoffs. For example, the quality of training data determines its effectiveness. This is still quite optimized for AI inference, but there’s more overhead compared to basic signature checks.
However, in cases requiring strong and sophisticated file type detection capabilities, the use of more advanced AI/ML technology in this area — such as Magika’s — is very effective.
Google is already using Magika at a large scale. The technology has made security difficult to breach and helps route files accurately for features like Gmail, Google Drive, and Safe Browsing.
Accurately detecting file types allows Magika to ensure that the correct security scanners and content policy checks are used for each file, drastically increasing overall safety and threat detection capabilities.
Google reports that Magika has improved file type identification by an average of 50 percent over its previous rule-based system. This higher accuracy enables Google to scan 11 percent more files using specialized AI document scanners designed to identify malicious content while reducing the number of unidentified files to just 3 percent.
Magika’s intelligent file type detection can also be leveraged beyond security use cases. Here are a few:
As you can see, there are many ways to integrate Google Magika into your applications to enhance existing features or enable new ones.
To demonstrate Magika’s functionalities in a web application context, we created a small demo using Next.js and React that combines the library with an editor. You can find the full demo code on GitHub.
This demo shows how we can start by detecting the file type at runtime of user uploads and switch the syntax highlighting language mode in the Monaco code editor accordingly, with a full range of syntax highlighting support.
Magika’s high-accuracy, optimized architecture allows it to run efficiently on low-powered CPUs, making it easy to incorporate into a wide range of use cases. Some example use cases include security scanning, web applications, cloud services, data processing pipelines, and developer tools.
Google’s open source, AI-powered Magika solution provides developers with more opportunities to create innovative systems that leverage intelligent file type identification.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

