It all starts like this: a head of engineering posts on LinkedIn. He says that he’s banning React from his next product because brilliant engineers keep burning days trying to fix a three-second dropdown freeze and optimize re-renders.
The post goes viral.
Hundreds of developers nod along. And somewhere in the reactions, the real problem goes completely unexamined. The app didn’t fail. The hiring process did:
This isn’t a defense of React. It’s also not an attack on the engineer who wrote that post; their frustration is completely valid. But when a developer with “a decade of experience” can’t diagnose a performance regression in days, the question isn’t “is React broken?” The question is: “What did your interview actually test?”
Over the past decade, I’ve climbed from intern to senior software engineer across companies ranging from early-stage startups to established product teams, including as a Senior Software Engineer at Gigmile for the last three years.
Along the way, I’ve sat on both sides of the hiring table, conducted well over twenty technical interviews, helped define hiring bars at two organizations, and inherited codebases from engineers whose CVs didn’t reflect what the role actually required.
I’ve also been the engineer who got hired on the strength of a process that never tested what the job would actually demand.
What all of that taught me is that the gap in this LinkedIn post isn’t unusual or surprising. I’ve watched versions of it play out dozens of times, at companies of various sizes, with engineers who were genuinely smart but underprepared for the same specific reasons.
By the end of this article, you’ll know what genuinely senior frontend skills look like, how to redesign your hiring process to screen for them, and if the gap is already on your team, what you can do about it. We’ll also cover the practical diagnostic toolkit a capable engineer should know, with strategies you can use in your next interview or team training session.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
“Ten years of React experience” and “ten years of operating React products at scale” are not the same thing. Your interview needs to tell them apart because this is where the problem begins.
If your hiring bar tests framework familiarity instead of diagnostic skill and architectural judgement, you’ll end up dissapointed: with expensive engineers who know React’s API but freeze when the app does.
Let’s be precise about what happened in the example shared on LinkedIn. A UI froze for three seconds when opening a dropdown. A form felt sluggish while typing. These aren’t exotic bugs. They’re among the most commonly documented React performance problems, the kind with named patterns, established tools, and decades of public write-ups. They are not corner cases.
A developer who has worked on real-world, production-scale frontend products will recognize both within a few minutes of profiling. The React Profiler will show unnecessary re-renders on every keystroke. The Chrome DevTools Performance panel will flag the long tasks blocking the main thread. The fix (whether it’s memoizing a component, colocating state, or virtualizing a list) is usually a targeted, low-risk change.
This is not a “React is fundamentally broken” issue. This is a “the person debugging it hadn’t practiced this class of problem before” issue. Those are very different situations with very different solutions.
“Ten years of React experience” is not a meaningful signal on its own. It tells you how long someone has been writing React. It doesn’t tell you whether they’ve ever been responsible for what happens after the code ships.
The gap that shows up in scenarios like the LinkedIn post is usually one of these:
None of these is a character flaw. They’re experience gaps that a different set of responsibilities would have closed. The problem is that a typical interview doesn’t check for any of them.
Think about what most senior frontend interviews test:
useEffect and other Hooks and dependencies problems?What they rarely test are the things that actually matter in practice:
The engineer in the LinkedIn post must have passed the first list. They almost certainly hadn’t been tested on the second. That’s the hiring process failing, not the candidate.
Here is how the interview exercises should have been designed:
Scenario: Opening a dropdown renders a list of 2,000 items with no virtualization. The main thread blocks for several seconds after the dropdown opens. On a throttled CPU, the interaction is nearly unusable.
Your task:
Expected diagnosis: An unvirtualized list renders all 2,000 items regardless of what’s visible in the viewport. The paint and layout time on dropdown open is blocking the main thread.
Expected fix: Virtualization using react-window or @tanstack/react-virtual. After the fix, only the visible rows are rendered, and the dropdown opens instantly.
I’d recommend a live coding lab so you can watch whether the candidate opens the profiler before opening the code editor. A candidate who goes straight to the code is skipping the diagnostic step. The fix here is not hard. What you’re evaluating is the process.
This exercise should take 30–60 minutes.
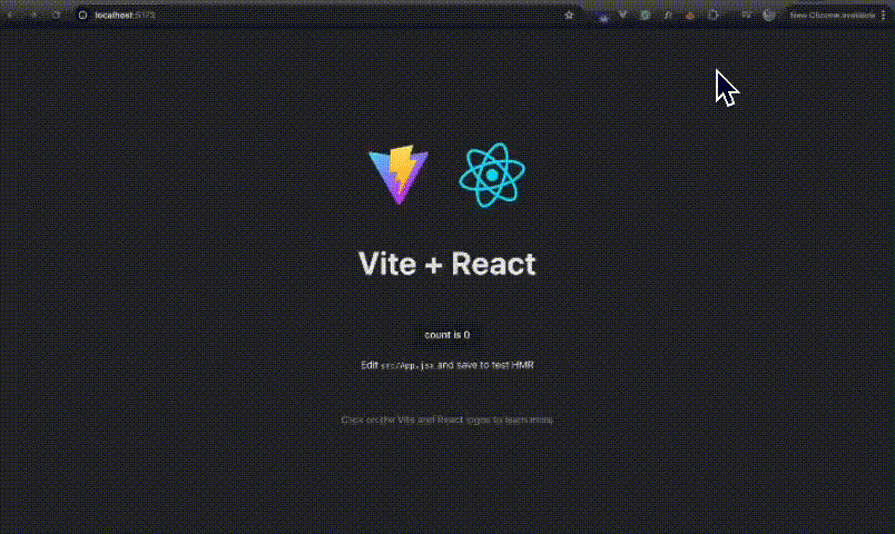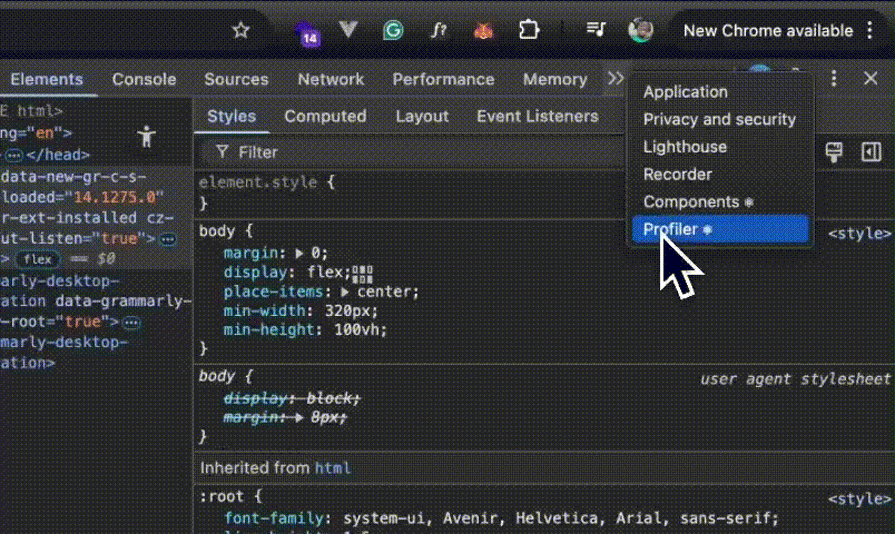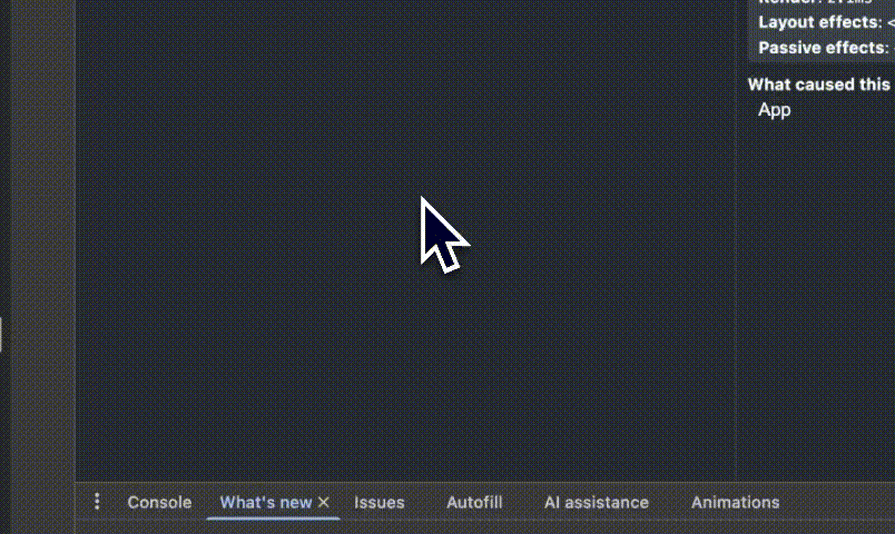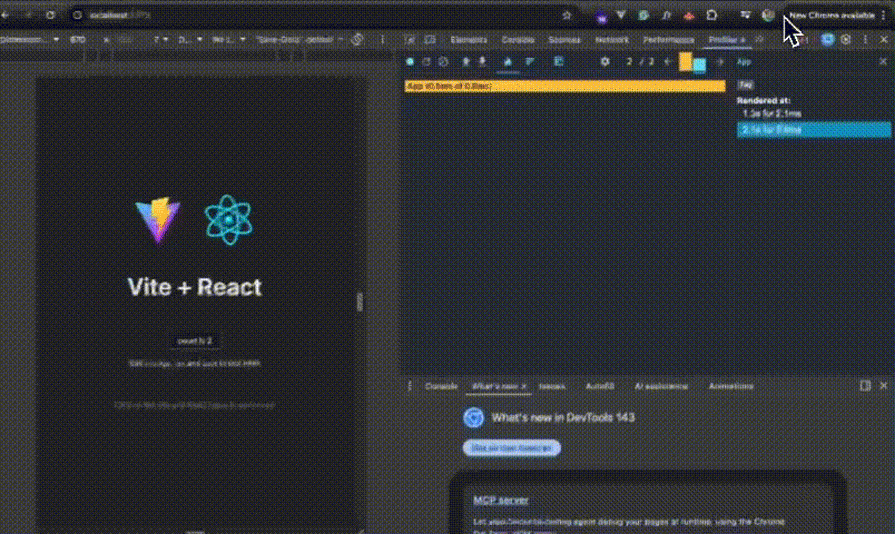
This work in both directions as interview exercises during a pair debugging session, and as team development exercises for building diagnostic instincts:
Profiling experience is easy to fake in an interview if you don’t test it directly. “I’ve optimized performance” is not the same as “I can show you how I diagnosed and fixed this regression.”
To improve your chance of getting a great hire, identify which of the four common skill gaps your last senior hire had and tailor your interviews around those.
Forget years of experience for a moment. Here’s what you actually need from a senior frontend engineer working on a real product:
The pattern I’ve seen consistently across the engineers I’ve worked with is this: the ones who thrive don’t wait for a performance issue to be handed to them. They notice the conditions that produce performance issues before the symptom appears.
In the pair debugging sessions at Gigmile, this is usually visible within the first five minutes of the session. A strong candidate opened the profiler. A struggling one opened the code editor. The ones who struggled weren’t less intelligent; they just hadn’t built the habit of measuring before acting, and no previous role had required them to.
Let’s be concrete. Given a three-second dropdown freeze and a form that feels like walking through snow, here’s what a capable senior dev should have done:
Open the app, trigger the slow interaction in isolation, and confirm it’s consistent. Note the conditions: data size, device throttling, dev vs. production build.
Open React Profiler. Record the dropdown open. Identify which components were rendered, how many times, and how long each render took. Open Chrome DevTools Performance panel. Identify long tasks and where time is being spent: scripting, rendering, and painting.
The flamegraph will usually point clearly to the culprit. Hundreds of list items re-rendering on a dropdown open? That’s a virtualization or memoization problem. The entire form subtree re-rendering on every keystroke? That’s a state architecture problem: something is too high, too broad, or insufficiently scoped.
Not a rewrite, a targeted change. If the list is unbounded, reach for react-window. If the form is re-rendering too broadly, collocate the state to the relevant field or scope the store subscription. One change, well-understood.
Re-profile the same interaction. Does the render count drop? Does the long task disappear?
Attach a before/after profiler screenshot to the PR. Write one sentence explaining what changed and why. Your future self and your colleagues will thank you.
This workflow sounds like it would slow you down. In practice, the developers who follow it consistently close performance issues faster than those who don’t, because they don’t spend time implementing fixes that don’t work.
A capable engineer with a good process should be able to move from symptom to validated fix in a day for a problem this well-scoped.
Most hiring processes don’t get redesigned until something goes wrong.
At Gigmile, we redesigned ours because we brought in a senior frontend engineer who interviewed well: articulate, strong on React fundamentals, good answers to our architecture questions.
And then he spent his first month avoiding the profiler. Every performance issue that landed on his plate got resolved by guessing and re-rendering, not by measuring. When we looked back at our interview notes, there was nothing in them that would have caught it. We had tested what he knew. We hadn’t tested what he did when something broke. What follows is what we changed.
Most senior frontend JDs look like this:
“5+ years of React experience. Strong knowledge of state management. Familiarity with performance optimisation. Experience with TypeScript, testing frameworks, and CI/CD pipelines.”
That description will attract every React developer who has been writing React for five years, regardless of whether they’ve ever diagnosed a performance regression, owned a metric, or thought about a state design at scale. You’ve described the tool, not the job.
Here’s what a sharper version looks like:
“You’ll own the performance and reliability of a complex, data-heavy frontend product. You can profile an app, read a flamegraph, and isolate a re-render problem from first principles. You’ve worked on a product where scale and long-term maintainability were real constraints, and you’ve made architectural decisions and lived with their consequences. You don’t just know the framework. You know what happens when it gets expensive.”
This does two things: it filters out candidates who read it and think “that doesn’t sound like me,” and it signals to genuinely strong candidates that the bar here is real. Both are valuable.
A well-constructed senior frontend interview should have three distinct stages, each testing something different. You don’t need all three for every hire, but you do need to deliberately test measurement skills, problem-solving process, and architectural thinking. Most processes currently test none of these.
This is your first filter. The goal is not to spend 45 minutes going through the CV chronologically. You’re trying to find out if this person has operated in the context you need.
Ask:
Listen for: specificity, measurement, ownership language. A strong answer names a metric, describes a concrete diagnostic approach, and explains a trade-off. A weak answer is vague (“we optimized things”), describes a team effort without a personal contribution, or refers to performance work done by someone else.
During my own interview for a senior role at a tech agency in the Netherlands, the first substantive question was exactly this format: not “tell me about your experience with performance,” but “walk me through a specific regression you owned.”
The specificity requirement is what makes it effective. It’s easy to claim familiarity with profiling tools. It’s much harder to fabricate a coherent narrative about a regression you diagnosed, fixed, and validated if you’ve never actually done it.
This is the most important stage, and the one most interview processes don’t have.
Give the candidate a running application with a real performance regression: a frozen dropdown opening a large list, or a form that re-renders on every keystroke due to a broad state subscription.
Let them drive from the start. Don’t explain the bug. Ask them to treat it like a production issue: find it, fix it, and show you the improvement.
You are not grading the fix. You are grading the process.
Present a simplified version of your actual product’s state architecture (or a plausible approximation) and ask the candidate to stress-test it.
Example setup: “We have a single top-level React context that holds user state, product data, and UI state. It has about forty consumers across the component tree. The product is about to double in complexity. Where do you expect this to break down, and what would you prioritize addressing first?”
A strong answer will:
A weak answer will:
Here’s the harder scenario: you read the LinkedIn post, recognized your own team, and now you’re wondering what to do. You’ve already made the hire. The engineer is smart and they care. But they just haven’t developed these specific skills yet.
The skills gap described in this article (no production profiling experience, no ownership of a perf metric, no architectural scars) is almost entirely an exposure gap. Someone who hasn’t had those experiences hasn’t had the chance to develop those instincts. That’s different from someone who can’t develop them.
Before concluding the hire was wrong, check: have you actually given this person the environment they’d need to develop these skills? Have you assigned them ownership of a real metric? Have they paired with anyone on a performance investigation? Have they been in a position where a regression they shipped had a visible impact?
If the answer is no, the gap may close faster than you expect if you create the right conditions.
The most effective way to develop these skills is not a course or a reading list. It’s deliberate exposure to the situations that build them.
Find a performance issue that’s on someone’s backlog and assign it jointly, ideally with an engineer who has strong diagnostic instincts. Have them drive the profiling, narrate what they’re seeing, and propose the fix. The first time you do this, it will be slow, and they’ll need guidance. The second time, less so. By the third or fourth, the process becomes instinctive.
Pick one: INP, frame rate for a critical interaction, TTI on the main page. Make them responsible for tracking it, reporting on it, and being the person who gets paged when it crosses a threshold. Accountability is a faster teacher than almost anything else.
Set aside time explicitly for practicing with React Profiler and Chrome DevTools on existing code, not to fix anything, just to read what the tools say. A developer who hasn’t used these tools under real conditions won’t get much from reading the documentation. They need reps.
The individual growth track matters, but so does the environment around it. If the team culture doesn’t reinforce these practices, individual development will be an uphill battle:
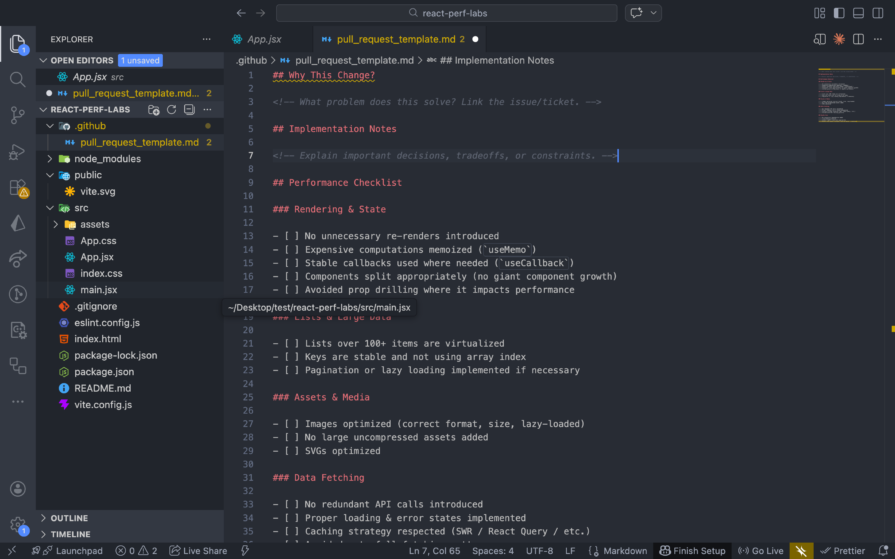
Not a lengthy audit, just a short checklist. Does this change introduce any new unnecessary re-renders? Is any new state being placed higher than it needs to be? Is there any expensive computation running without memoization? A prompt in the PR template is enough to create the habit:
Pick two or three metrics (INP, frame rate, bundle size for a critical route) and automate alerts when they regress in CI. The team doesn’t need to chase every number obsessively. They just need to know when something has moved in the wrong direction.
When something ships that makes the UI measurably worse, debrief on it publicly and without blame. What was the symptom? What caused it? What would have caught it earlier? These sessions build intuition faster than any other mechanism, because they’re grounded in real code that real people wrote.
Returning to the LinkedIn post for a moment: the head of engineering wasn’t wrong to be frustrated. Watching a brilliant engineer spend so much time and still be unable to resolve a performance regression is genuinely painful. They’re burning time, the product is suffering, and there’s no clear end in sight. That frustration is valid.
But the conclusion, “React is the problem, React is banned,” is a wrong diagnosis. I’ve watched teams go down that road, switching frameworks, adding layers of abstraction, rewriting. All while the actual problem, a hiring bar that didn’t test for diagnostic skill, stayed completely intact. The new stack reproduces the same outcome with different error messages. You don’t fix the gap by changing the tool. You fix it by changing what you test for before you make the hire.
A sufficiently skilled senior frontend engineer should be able to diagnose most React performance problems within days, not weeks. I know this because I’ve worked alongside engineers who do exactly that, and I’ve hired engineers who couldn’t. The difference wasn’t intelligence or work ethic. It was whether their previous roles had ever required them to measure before acting. That’s an addressable gap, but only once you’ve built a process that catches it.

I tested the Speculation Rules API in a real project to see if it actually improves navigation speed. Here’s what worked, what didn’t, and where it’s worth using.

How AGENTS.md and agent skills improve coding agents, reduce mistakes, and make AI IDE workflows more reliable and project-aware.

Build a simple, framework-free Node.js app, and then deploy it to three different services that offer a free tier, Render, Railway, and Fly.io.

Understand best practices for structuring Node.js projects, such as separating roles using folder structures and practicing modular code.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

