This article is part of an ongoing series on conceptualizing, designing, and implementing a GraphQL server. The first article in this series is “Designing a GraphQL server for optimal performance.”
Simplicity and performance are possibly the two most important features of our application. These two must be balanced; either optimizing for performance at the expense of simplicity, or for simplicity at the expense of performance, would render our application useless.
No developer would want to use software that is extremely fast but so complex that you need to be a genius to use it, or very simple to use but too slow. Hence, designing for simplicity cannot be an afterthought; it must be engineered into the software right from the beginning.
In my previous article, “Designing a GraphQL server for optimal performance,” I showed how a GraphQL server can completely avoid the N+1 problem by having the resolvers return the ID of the objects (instead of the objects themselves) when dealing with relationships. Doing so made the code for the resolvers become very simple because it doesn’t need to implement the “deferred” mechanism anymore, which is instead embedded within the server itself, hidden from view.
For example, take the following (PHP) code for a resolver. Field author, which is a field of type User that must be resolved through one or more additional queries to the database, should be more difficult to resolve than field title, which is a scalar field that can be immediately resolved.
Yet the only difference is two lines of code in function resolveFieldTypeResolverClass, which itself just returns a classname (to indicate the type of object that author must resolve to):
class PostFieldResolver implements FieldResolverInterface
{
public function resolveValue($object, string $field, array $args = [])
{
$post = $object;
switch ($field) {
case 'title':
return $post->title;
case 'author':
return $post->authorID; // This is an ID, not an object!
}
return null;
}
public function resolveFieldTypeResolverClass(string $field, array $args = []): ?string
{
switch ($field) {
case 'author':
return UserTypeResolver::class;
}
return null;
}
}
This step is half of the solution to load data in a very simple manner. It transfers the responsibility of implementing the complex code in the resolvers away from the developer and into the server’s data loading engine, to hopefully be coded only once and used forever. However, doing this alone doesn’t make the overall application become simpler, it just moves its complexity around.
So now let’s delve into the second half of the solution: making the code in the server’s data loading engine as simple as it can ever be. For this, we need to understand graphs, the data model over which GraphQL stands.
Or is it?
On its page titled Thinking in Graphs, the GraphQL project states (emphasis mine):
Graphs are powerful tools for modeling many real-world phenomena because they resemble our natural mental models and verbal descriptions of the underlying process. With GraphQL, you model your business domain as a graph by defining a schema; within your schema, you define different types of nodes and how they connect/relate to one another. On the client, this creates a pattern similar to Object-Oriented Programming: types that reference other types. On the server, since GraphQL only defines the interface, you have the freedom to use it with any backend (new or legacy!).
The takeaway from this definition is the following: even though the response has the shape of a graph, this doesn’t mean that data is actually represented as a graph when dealing with it on the server side. The graph is only a mental model, not an actual implementation.
This realization is shared by others:
GraphQL itself has the name “graph” in it, even though GraphQL isn’t actually a graph query language!
– Caleb Meredith (ex-Apollo GraphQL)
[GraphQL is] neither a query language, nor particularly graph-oriented. … If your data is a graph, it’s on you to expose that structure. But your requests are, if anything, trees.
– Alan Johnson (ex-Artsy)
This is good news because dealing with graphs is not trivial, and we can then attempt to use a simpler data structure.
What comes to mind first is a tree, which is simpler than a graph (a tree is actually a subset of a graph). Indeed, as mentioned in the quote above, the shape of the GraphQL request is a tree. However, using a tree structure to represent and process the data in the server is not trivial either and may require hacks to support modeling recursions.
Is there anything simpler?
What I found to be a most suitable structure for storing and manipulating object data in the server side is… components!
Using components to represent our data structure on the server side is optimal for simplicity because it allows us to consolidate the different models for our data into a single structure. Instead of having a flow like this:
build query to feed components (client) => process data as graph/tree (server) => feed data to components (client)
…our flow will be like this:
components (client) => components (server) => components (client)
This is achievable because the GraphQL request can be thought of as having a “component hierarchy” data structure, in which every object type represents a component and every relationship field from an object type to another object type represents a component wrapping another component.
Huh? Can you explain that in English, please?
Let me make my previous explanation clearer using an example. Let’s say that we want to build the following “Featured director” widget:
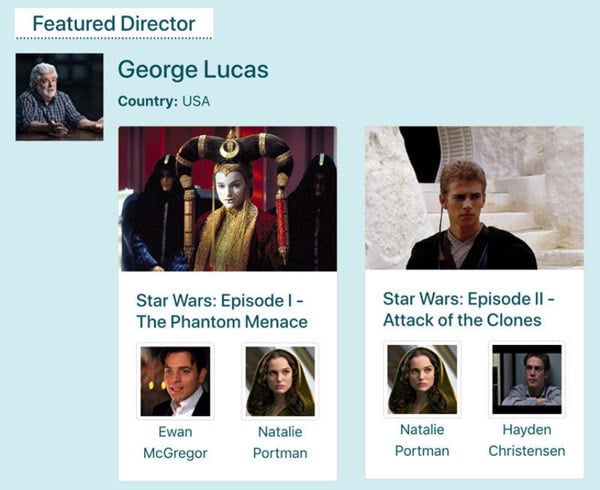
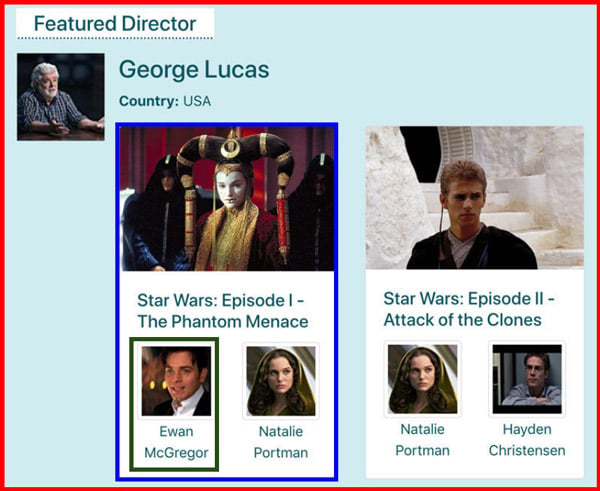
Using Vue or React (or any other component-based library), we would first identify the components. In this case, we would have an outer component <FeaturedDirector> (in red), which wraps a component <Film> (in blue), which itself wraps a component <Actor> (in green):
The pseudo-code will look like this:
<!-- Component: <FeaturedDirector> -->
<div>
Country: {country}
{foreach films as film}
<Film film={film} />
{/foreach}
</div>
<!-- Component: <Film> -->
<div>
Title: {title}
Pic: {thumbnail}
{foreach actors as actor}
<Actor actor={actor} />
{/foreach}
</div>
<!-- Component: <Actor> -->
<div>
Name: {name}
Photo: {avatar}
</div>
Then we identify what data is needed for each component. For <FeaturedDirector>, we need the name, avatar, and country. For <Film>, we need thumbnail and title. And for <Actor>, we need name and avatar:
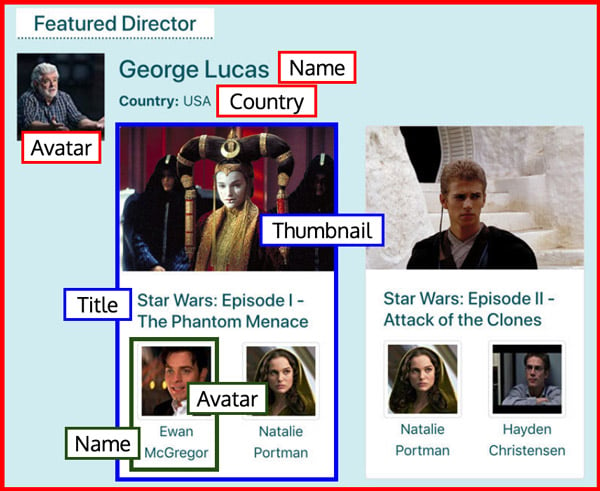
And we build our GraphQL query to fetch the required data:
query {
featuredDirector {
name
country
avatar
films {
title
thumbnail
actors {
name
avatar
}
}
}
}
As you can see, there is a direct relationship between the component hierarchy above and this GraphQL query.
Let’s now move to the server side to process the request. Instead of dealing with the query as a tree, we continue using the same component hierarchy to represent the information.
In order to process the data, we must flatten the components into types (<FeaturedDirector> => Director; <Film> => Film; <Actor> => Actor), order them as they appeared in the component hierarchy (Director, then Film, then Actor), and deal with them in “iterations,” retrieving the object data for each type on its own iteration, like this:

The server’s data loading engine must implement the following (pseudo-)algorithm to load the data:
Preparation:
[type => list of IDs])DirectorLoop until there are no more entries on the queue:
Director and [2]), and remove this entry off the queueTypeDataLoader object (explained in my previous article), execute a single query against the database to retrieve all objects for that type with those IDsDirector has relational field films of type Film), then collect all the IDs from these fields from all the objects retrieved in the current iteration (eg: all IDs in field films from all objects of type Director), and place these IDs on the queue under the corresponding type (eg: IDs [3, 8] under type Film).By the end of the iterations, we will have loaded all the object data for all types, like this:
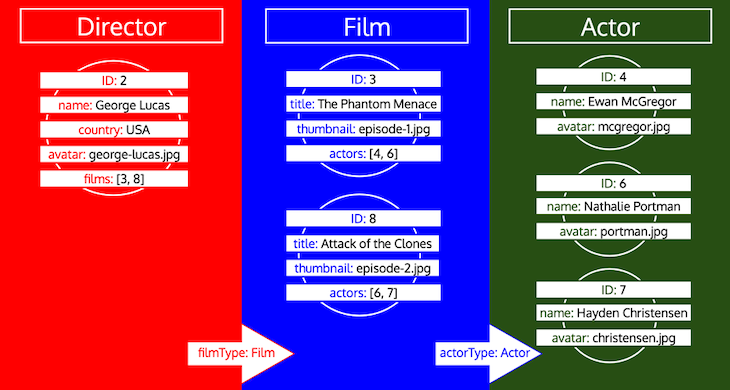
Notice how all IDs for a type are collected until the type is processed in the queue. If, for instance, we add a relational field preferredActors to type Director, these IDs would be added to the queue under type Actor, and it would be processed together with the IDs from field actors from type Film:
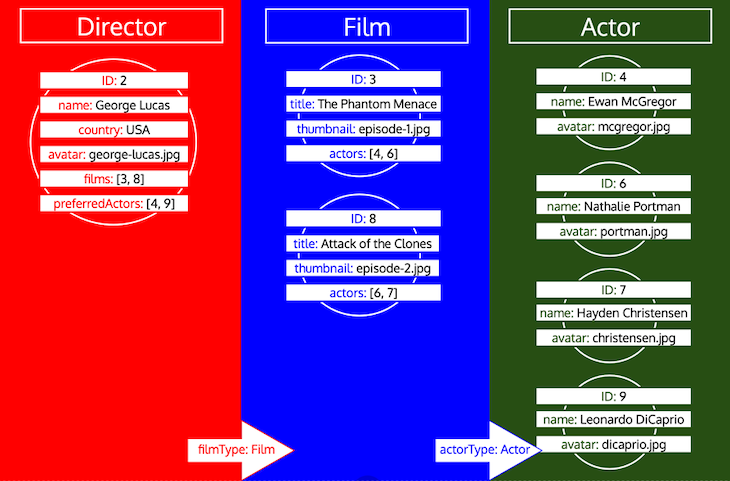
However, if a type has been processed and then we need to load more data from that type, then it’s a new iteration on that type. For instance, adding a relational field preferredDirector to the Author type will force the type Director to be added to the queue once again:
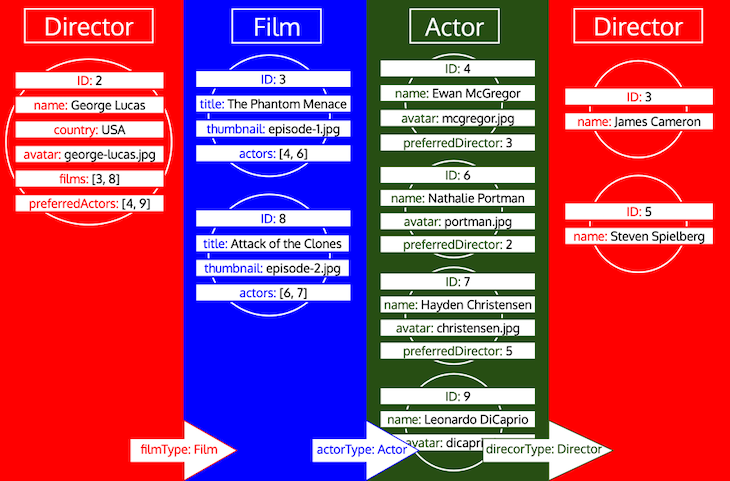
Also note that here we can use the caching mechanism as implemented in dataloader: on the second iteration for type Director, the object with ID 2 is not retrieved again since it was already retrieved on the first iteration. Thus, it can be taken from the cache.
Now that we have fetched all the object data, we need to shape it into the expected response, mirroring the GraphQL query. However, as you can see, the data does not have the required tree structure. Instead, relational fields contain the IDs to the nested object, emulating how data is represented in a relational database.
Hence, following this comparison, the data retrieved for each type can be represented as a table, like this:
Table for type Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Table for type Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Table for type Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Having all the data organized as tables, and knowing how every type relates to each other (i.e., Director references Film through field films; Film references Actor through field actors), the GraphQL server can easily convert the data into the expected tree shape:
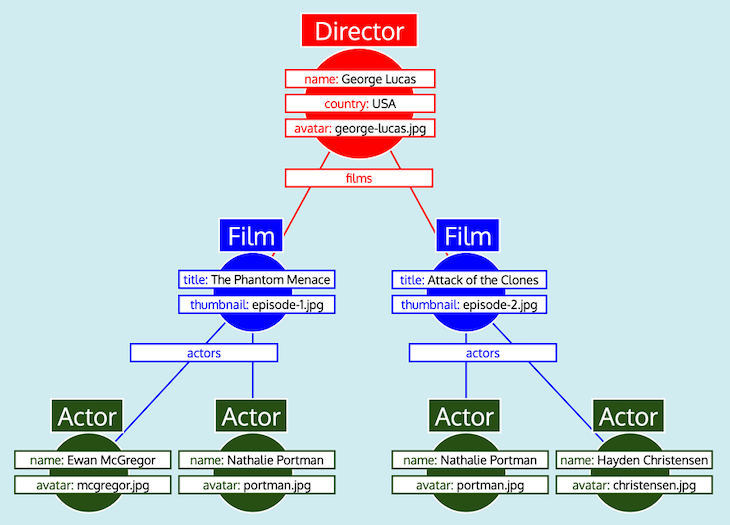
Finally, the GraphQL server outputs the tree, which has the shape of the expected response:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}
Let’s analyze the big O notation of the data loading algorithm to understand how the number of queries executed against the database grows with the number of inputs to make sure this solution is performant.
The GraphQL server’s data loading engine loads data in iterations corresponding to each type. By the time it starts an iteration, it will already have the list of all the IDs for all the objects to fetch, hence it can execute one single query to fetch all the data for the corresponding objects.
It then follows that the number of queries to the database will grow linearly with the number of types involved in the query. In other words, the time complexity is O(n), where n is the number of types in the query (however, if a type is iterated more than once, then it must be added more than once to n).
This solution is very performant, much better than the exponential complexity expected from dealing with graphs or logarithmic complexity expected from dealing with trees.
The solution outlined in this article is used by the GraphQL server in PHP that I’ve implemented, Gato GraphQL. The code for its data loading engine can be found here. Since this piece of code is very long, and I have already explained how the algorithm works, there’s no need to reproduce it here.

In my previous article, I started describing how we can build a GraphQL server that is performant, and in this article I completed it by describing how it can be made simple by using components to represent the data model in the server instead of using graphs or trees.
As a consequence, implementing resolvers is very performant (linear complexity time based on the number of types), and very easy to do (the “deferred” mechanism is not implemented by the developer anymore).
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now


