The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
GraphQL was created by Facebook in 2012 and was open sourced in 2015 to solve the problems that were apparent with traditional REST API, which involve having to make a request to a lot of different endpoints to get data back.
GraphQL is essentially a query language for APIs, as well as a runtime for fulfilling queries with your existing data.
It provides a complete description of the data in your API through schemas. It gives the client the power to ask for exactly the data they need, how they need it, and nothing more.
The internals of a GraphQL server are essentially made up of 3 types that constitute the resolver. It can either be a query, mutation, or a subscription that performs certain operations on our database layer and produce a response that is tailored according to the request.
Here is a diagram that demonstrates what I’ve described: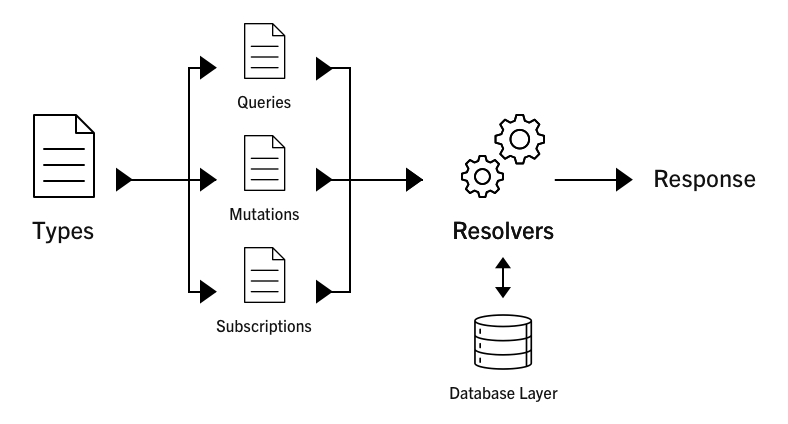
This new and exciting technology solves a unique problem, but it also comes with its own security and performance costs.
We will be exploring a few and identifying ways to handle them.
One of the fascinating things about GraphQL is that there is no danger of overfetching — i.e., you can’t just ask the database to send all records.
This differs from traditional REST API, where you can run SELECT * FROM Users. In GraphQL, you would have to explicitly ask for the different fields you require.
{
books {
title
author
}
}
Here we are asking for the title and the author field from the book query. These are scalar type (meaning they are primarily of INT, FLOAT, STRING, BOOLEAN, and ID), so the book query type could also be defined to return object types.
Object types are usually a collections of fields that are scalar types or other object types.
You may or may not want to have introspection queries enabled if you are building a public API that will be used by different people. In this case, it’s okay to have it enabled as they will be making requests to your endpoint.
It’s important that they know how to query the endpoint and the kind of results that they expect back.
However, if your endpoint is for private consumption only, it makes sense to have introspection disabled in the production environment as we want attackers to have as little information as possible on our endpoint.
Authorization is the business logic of determining who has access to a certain resource. For example, only users with subscriptions should be able to view premium content.
This kind of behavior should be enforced in the business logic rather than in the GraphQL layer because GraphQL doesn’t come with a builtin authorization module. However, there are best practices that we can employ and libraries that we can use to ensure that it works the way to should and that it is a smooth process.
The first thing to do is find the endpoint and the attached?debug=1. This ensures that errors are verbose and gives the user (in this case the attacker) more context as to how to better tailor their attack.
Introspection queries are enabled by default. When the endpoint is known, an introspection query is sent to it to which in turns come back with information concerning all the possible ways the endpoint can be queried.
This includes all available queries, mutations, and subscriptions, which we can then run tests on for loopholes.
NB: The result introspection queries can be very large.
Because the result can be very large, parsing it manually can be very time-consuming and tedious process. We can use a tool called the GraphQL voyager where we can paste the result of the introspection query so as to make sense of the schema design in an attempt to exploit it.
This is not as straightforward, but it is doable since we can perform a calculated guess repeatedly until we arrive at what we can exploit.
First we can check subdomains: try to locate any publicly available staging/dev urls.
This could be the staging.domain.com.graphql or dev.domain.com/graphql, etc.
You can then check burp proxy, which captures the request lifecycle of all available requests in burp.
Burp Intruder/ Repeater runs the request again and again using field stuffing.
Now, you can guess the schema by trying out random fields from a word list.
Adjust the fields based on suggestion and GraphQL will adjust correct fields if you are close.

From the above error returned, we already know a few mutations that are available to us.
Depending on the way authentication logic was implemented, it can be bypassed by taking a nested query and running it as a root query.
This will bypass the authentication logic if there is a flaw in its implementation to gives us access to information that we aren’t cleared for.
Consider the following example:
{
user {
id
name
email
friends {
id
name
email
}
}
}
#this might work
{
friends {
id
name
email
}
}
Max Stoiber went into great details of how a GraphQL server can be exploited when there is a circular relationship between the schemas.
Consider the following schema definitions where messages and threads are intertwined:
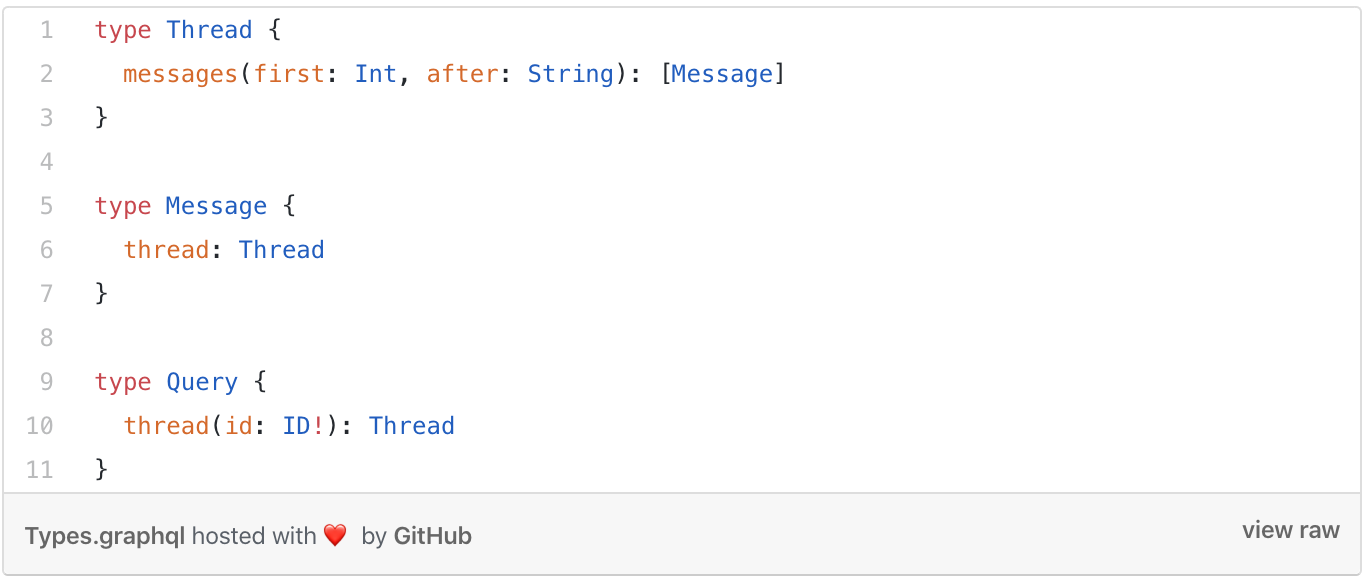
As you can see from the above, when we query for a message we can ask for a thread and then another message.
Hence a malicious user can take advantage of this and run an expensive query like this:
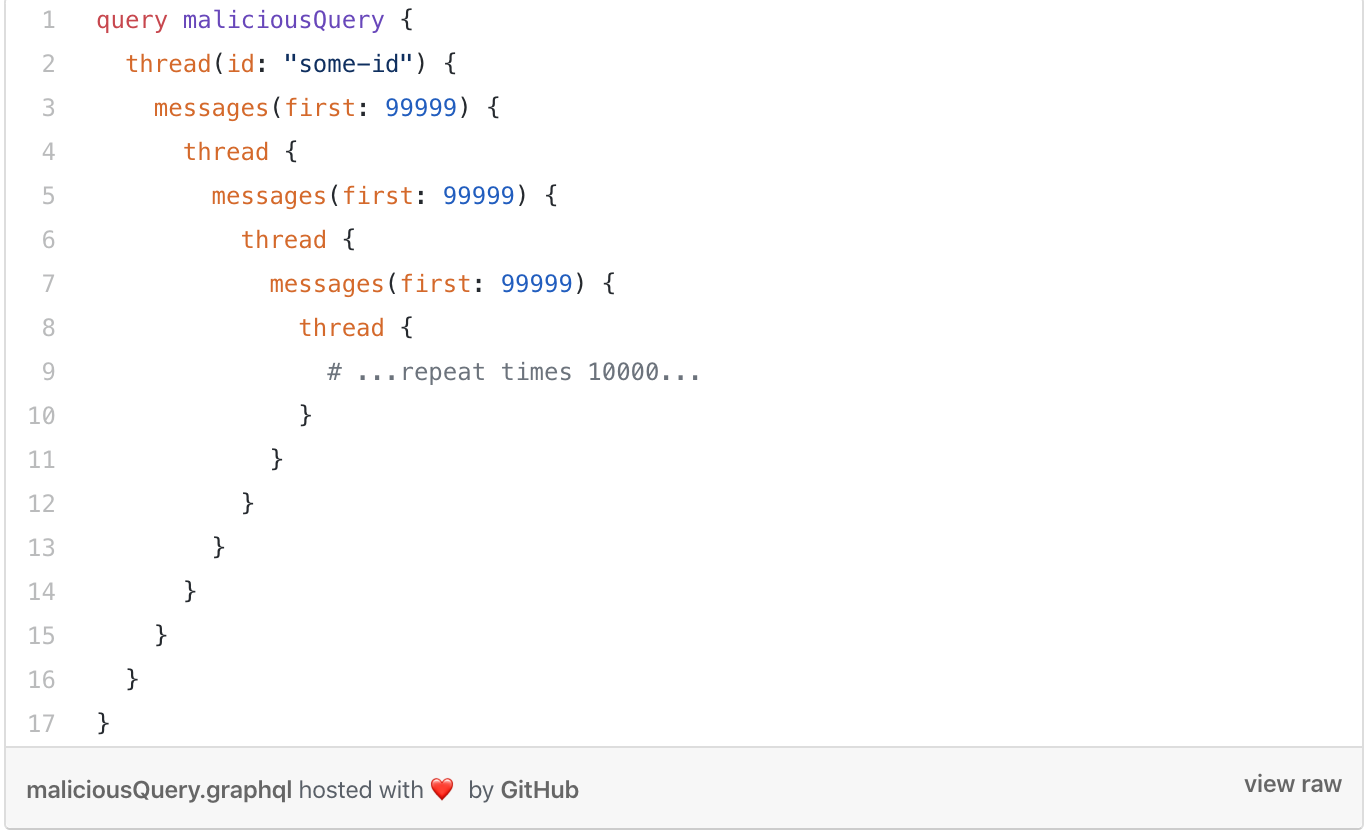
Max Stoiber also went into great details in his article as to how this can be prevented.
It is up to the developer to properly validate and sanitize input so as to prevent a malicious request from hitting the database. A malicious user could simple attach the * in SQL to return all from the database if not properly sanitized.
Here is an example depicting how this can be done:
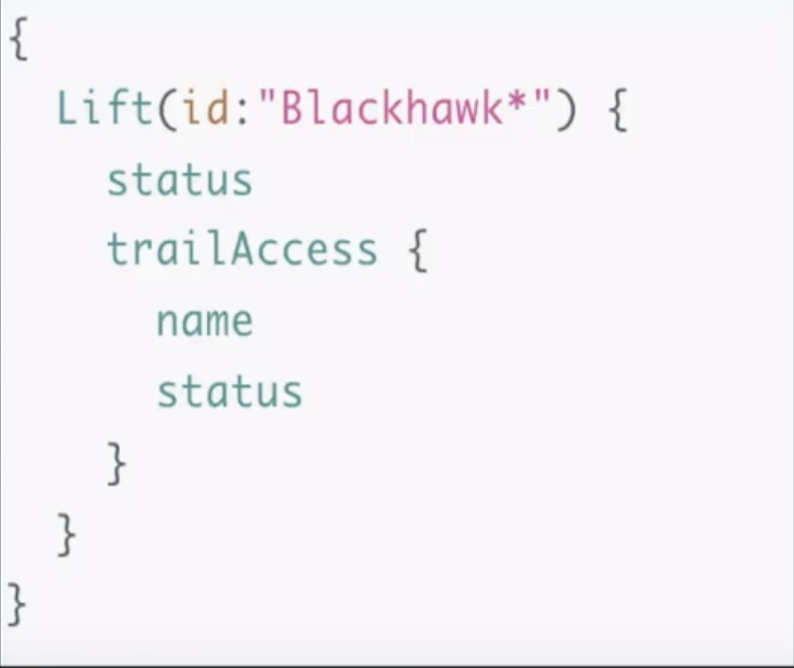
A NoSQL injection is also very possible through JSON types.
Pete Corey describes in his article how a malicious query can be sent to a GraphQL server through the use of custom scalar types.
Be sure to check that out.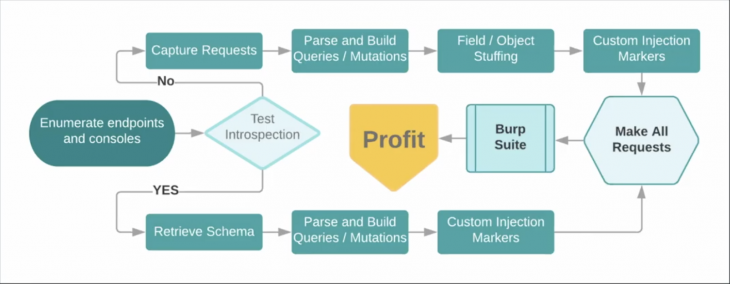
Here are a few things to consider to properly protect your server:
This post was inspired by the work of Matt Szymanski in his informative youtube video.
Happy coding!
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

useEffect breaks AI streaming responses in ReactSee why useEffect breaks AI streaming in React, and how moving stream state outside React fixes flicker and stale updates.

A real-world debugging session using Claude to solve a tricky Next.js UI bug, exploring how AI helps, where it struggles, and what actually fixed the issue.

CSS wasn’t built for dynamic UIs. Pretext flips the model by measuring text before rendering, enabling accurate layouts, faster performance, and better control in React apps.

Why do real-time frontends break at scale? Learn how event-driven patterns reduce drift, race conditions, and inconsistent UI state.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

