For years, cloud-based AI has been the default choice – scalable, simple, and accessible. But as costs climb and data privacy demands tighten, many enterprises are starting to rethink that reliance. Running AI models locally promises control, predictability, and independence, but it also brings new challenges.

In this blog, we’ll explore what local AI really means in practice: the hardware it requires, the tradeoffs it introduces, and the organizational shifts it sets in motion.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Three main reasons are driving enterprises and developers to run AI models locally: data privacy, cost stability, and offline reliability. Let’s look at each in more detail:
It’s understandable that organizations don’t want their proprietary code, client data, or business logic exposed while training or interacting with third-party models. In many industries, including healthcare, finance, and legal, strict data protection regulations make this not just a preference, but a requirement. Running models locally ensures sensitive data stays within organizational boundaries, reducing compliance risks and preserving intellectual property.
For many enterprises, sustainability comes down to cost predictability. Cloud API expenses can rise unpredictably as usage scales, especially during peak operational periods. Local inference, by contrast, provides clearer visibility into costs tied to hardware, power, and maintenance. This predictability makes budgeting more reliable and long-term planning more practical.
Consider mission-critical sectors like healthcare, where access to real-time AI support may be needed in remote areas with limited or unstable internet. Locally deployed AI models ensure continued functionality even without connectivity, an essential capability when uptime directly impacts outcomes. In these situations, local AI isn’t just a convenience; it’s a safeguard.
When discussing large language models (LLMs), a critical question often goes unaddressed: hardware requirements, much like the tradeoffs behind local-first architectures in web development. Here’s a clearer picture of what those numbers mean for enterprise planning.
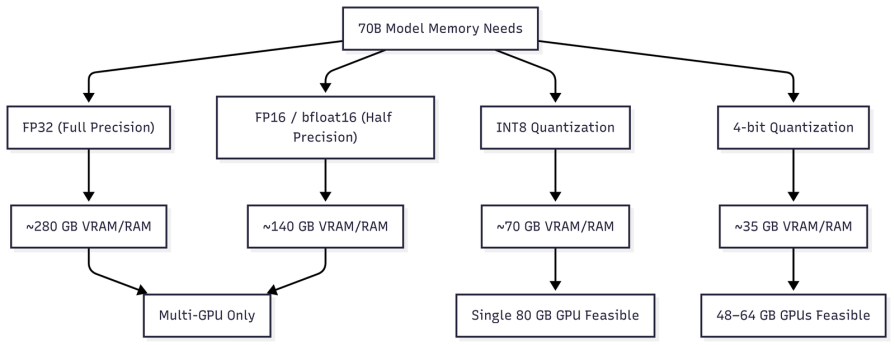
For organizations exploring 70-billion-parameter models such as LLaMA-2 or LLaMA-3-70B, the key bottleneck isn’t computation: it’s memory.
At the most basic level, every parameter is just data that must be stored somewhere. In FP16, a 70B model consumes roughly 140 GB of memory just for its weights. That means even the highest-end 80 GB GPUs can’t run the model alone, making multi-GPU parallelism necessary.
There are two main ways to reduce this footprint:
FP32 down to FP16 or bfloat16, which is now standard practiceINT8, memory needs drop to about 70 GB; at 4-bit quantization, they fall to around 35 GBThis shift is more than a technical trick – it’s what makes 70B-parameter models feasible on single high-memory GPUs. In practice, 48 GB and 64 GB GPUs running 4-bit quantized models have become the sweet spot for ambitious teams and serious hobbyists alike, delivering near-state-of-the-art performance without enterprise-scale hardware budgets:
But model weights are only part of the story. Every token generated also requires storing intermediate results known as the KV cache. For a 70B model, this adds roughly 0.3 GB of memory per 1,000 tokens at FP16. An 8K-token context adds around 2.5 GB on top of the base model, while a 32K context can demand nearly 10 GB more.
This is why memory requirements scale not just with model size, but also with the user experience you want to deliver. Longer conversations, larger documents, or extended context windows all directly increase hardware costs.
The result is a simple rule of thumb for enterprise planning:
FP16 (no quantization) – multi-GPU only (~140 GB+)INT8 (weights only) – viable on an 80 GB GPUUnderstanding these dynamics helps inform hardware purchasing, cloud budgeting, and edge deployment feasibility, turning abstract technical tradeoffs into concrete business decisions.
The rapid increase in AI models creates both opportunity and confusion. Choosing the right model requires looking beyond benchmark scores to assess which delivers consistent, measurable impact in production. Benchmarks alone don’t tell the story. By placing each model under practical, business-relevant criteria, we uncovered how they perform when it matters most.
Strategic model selection means prioritizing measurable business value over impressive benchmarks. That’s why we tested leading open-weight LLMs against three enterprise-relevant lenses:

The table below summarizes the tradeoffs at a glance:
| Model | Speed Performance | Resource Usage | Code Quality | Math Accuracy | Reasoning | Overall Assessment |
|---|---|---|---|---|---|---|
| Llama 3.2 (3.2B) | 10s simple, 38s complex | 2.5 GB RAM | Good structure, helper functions | Math error (1.01864 vs 1.191016) | Sound logical reasoning | Best for resource-constrained environments |
| Qwen 7B (7.7B) | 33s simple, 89s complex | 4.5 GB RAM | Syntax errors, verbose comments | Calculation errors, formatting issues | Reasonable but flawed logic | Moderate performance, verbose output |
| Mistral (7.2B) | 33s simple, 96s complex | 4.4 GB RAM | Clean code but inefficient algorithm | Incorrect principal assumption | Cautious, accurate reasoning | Balanced but conservative approach |
| DeepSeek-R1 (7.6B) | 40s simple, 207s complex | 4.7 GB RAM | Excellent implementation, optimal algorithm | Perfect calculations, clear formatting | Thorough analysis with thinking process | Highest quality output with reasoning transparency |
This testing demonstrates why benchmark scores alone mislead deployment decisions. The 3.2B Llama model outperforms much larger 7B models in practical scenarios, highlighting the importance of optimization over raw parameter count in local deployment contexts.
Running AI models locally doesn’t just change your infrastructure; it rejuvenates how you think about your team structures and decision-making processes. Teams’ access to AI models changes the questions from “can we use AI?” to”what model best fits the team’s needs?”
A new design principle for enterprise structure is emerging: assigning models as deliberately as you allocate resources. An engineering group might deploy a high-memory, code-optimized model. A customer-facing analytics team could leverage a fast, quantized model that balances accuracy with responsiveness.
Since you can orchestrate these models through shared GUIs like Open WebUI and management layers, organizations no longer need to standardize every team on the same heavy infrastructure. Instead, local AI enables differentiated deployment by placing the right tool on the appropriate hardware for each team:
To enable local teams to share and manage models collaboratively, tools like Open WebUI provide a lightweight graphical interface for running and monitoring local LLMs.
Here’s a quick example of how to set it up using Docker:
docker run -d -p 3000:8080 \ -e OLLAMA_BASE_URL=http://host.docker.internal:11434 \ -v open-webui:/app/backend/data \ --name open-webui \ --restart always \ ghcr.io/open-webui/open-webui:main
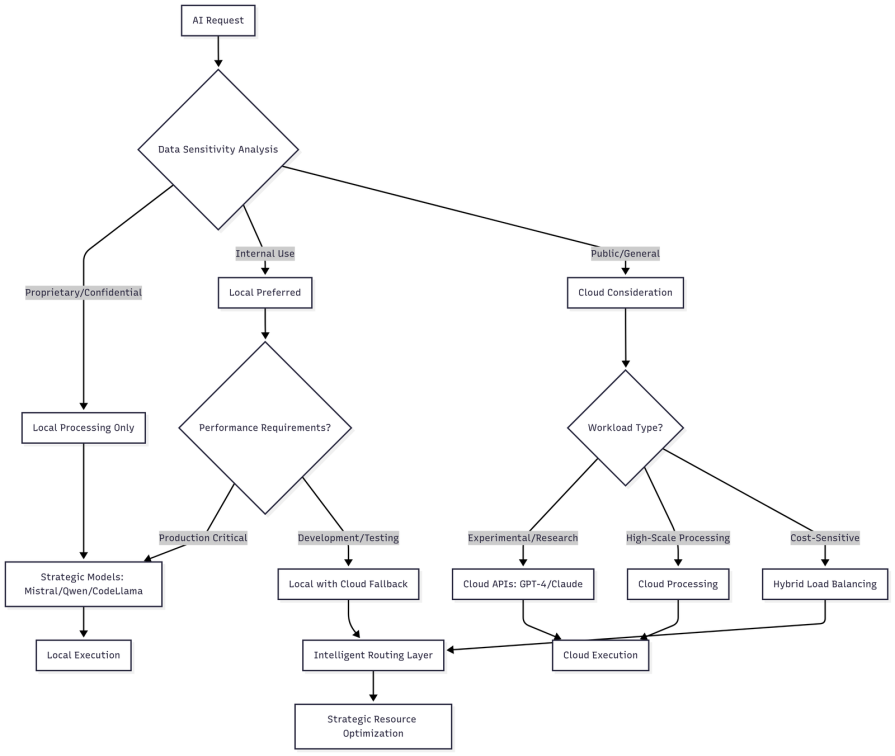
The future of AI model use in enterprises lies in combining the best of both local and cloud-based models – as seen in hybrid, edge-friendly frameworks like MediaPipe – to deliver optimal results when one approach fails. Hence, the goal is to maximize strategic advantage while minimizing risk and cost.
Future leading organizations see the potential and are developing frameworks for workload distribution that optimize for different strategic objectives.
Local deployment becomes the foundation when considering the strategic side of things. Your proprietary data is processed securely within organizational boundaries, and you can achieve regulatory or sovereignty requirements without compromise. Core business logic and competitive algorithms remain protected, ensuring that what makes a company unique stays within its control.
On the other hand, cloud integration drives operational efficiency. It handles non-sensitive development and testing, manages peak capacity, and enables rapid experimentation across multiple models. It also provides access to specialized capabilities that require massive scale, without burdening local infrastructure:
Understanding the implications of local deployment requires an honest look at the tradeoffs, not just technical, but organizational.
It’s essential to be honest about these tradeoffs and recognize them as a strategic commitment that provides autonomy and resilience while demanding operational rigor.
The math is straightforward: 70B-parameter models require about 35 GB with 4-bit quantization, hybrid architectures resolve the cloud-versus-local dilemma, and organizational friction ultimately becomes a competitive advantage. The enterprises getting this right aren’t chasing benchmarks; they’re building capabilities that others can’t replicate without walking the same path of hardware selection, optimization, and maintenance.
Local AI has moved beyond “Is it possible?” to “What’s your deployment strategy?” The organizations investing in this setup today are developing institutional knowledge that compounds over time. The question isn’t whether this approach becomes standard practice; it’s who leads the transformation.
The hardware reality is clear – the models are ready, and hybrid approaches have been proven. The question now is whether you’re building these capabilities yourself or letting competitors define your AI future. It’s time to take a hard look at your infrastructure reality.
Running AI models locally is no longer an experimental idea; it’s a defining shift in how enterprises approach control, cost, and capability. The organizations investing in local infrastructure today aren’t just optimizing performance; they’re building internal knowledge, operational independence, and resilience that compound over time.
Hybrid architectures will continue to bridge the gap between local and cloud, but the strategic advantage lies in understanding when and why to deploy each. As the ecosystem matures, the leaders won’t be those chasing the biggest models; they’ll be the ones who’ve mastered their environments, balanced autonomy with scale, and built systems that truly serve their teams and customers.
Local AI is here to stay. The question is no longer if you’ll adopt it, but how strategically you’ll make it your own.

Memory leaks in React don’t crash your app instantly, they quietly slow it down. Learn how to spot them, what causes them, and how to fix them before they impact performance.

Build agent-ready websites with Google Web MCP. Learn how to expose reliable site actions for AI agents with HTML and JavaScript.

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 25th issue.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

