Imagine you’re a product manager for an e-commerce business. The business has one million orders per day and the platform usually handles this fine.

The entire system has multiple services and platforms, developed and integrated to work together in serving customers from booking orders to fulfilling them. At a high level, the system architecture would look like:
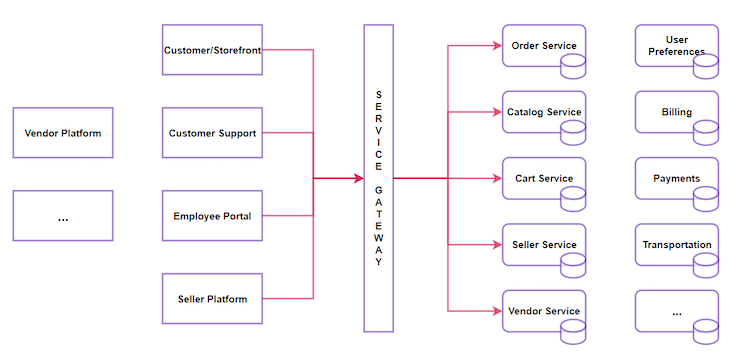
Now imagine your customer adds their items to the cart and wants to check out when this happens:
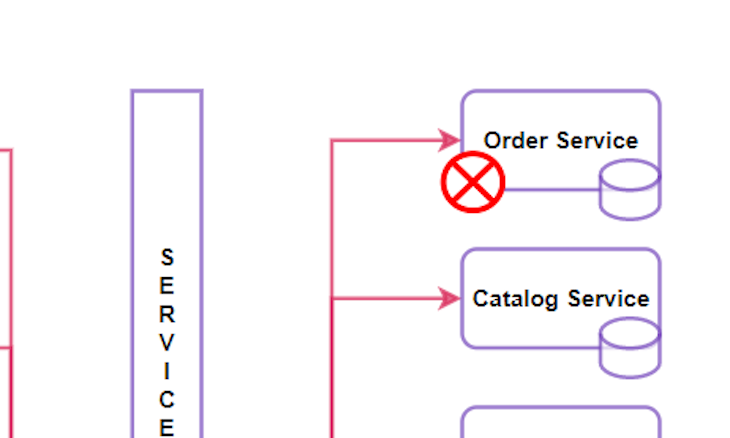
The order service is unavailable, which prevents your customer from placing their order. In this case, the business faces losses and you weaken the trust of your customers
As a PM, you cannot afford to have any services or components in your system not function properly.
By now, you may wonder:
To answer these, you can utilize site reliability engineering.
In this article, you will learn what site reliability engineering is, its key terms and core principles, and how SRE will assist you in your role as a PM.
Site reliability engineering (SRE) is a discipline used for solving the challenges faced in running large-scale, highly distributed systems. SRE applies software engineering practices to operations and infrastructure, aiming to improve the system’s reliability and reduce the time needed in detecting and recovering from outages.
SRE incorporates aspects of software engineering and applies them to IT operations. At its core, SRE majorly focuses on the following activities:
System reliability engineering can be traced back to the early 2000s when Google was experiencing rapid growth and faced system outages and performance issues due to increased customer base and usage.
To solve the reliability problems that Google sites were facing Google formed a team of engineers led by Ben Treynor. This team was responsible for making Google websites available, performant, and reliable.
They found that the development team (responsible for releasing new features to the market) and the operations team (responsible for maintaining the systems and their operations) were working in isolation with different goals. This resulted in delays in the release of features.
As a software engineer, Treynor decided to apply engineering practices in operations to solve reliability issues. He termed the word site reliability engineering. He automated repetitive tasks in operations, developed tools for monitoring, and automated processes for change management, incident analysis, and resolution.
The SRE team quickly made a significant impact on Google’s reliability by solving site outages and performance problems. As a result, Google was able to improve its customer experience and reduce its operating costs.
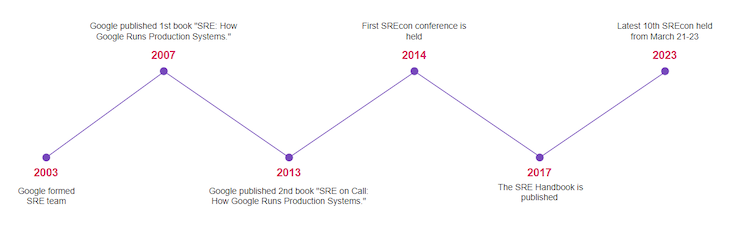
The success of the SRE team at Google helped to improve its customer experience and reduce its operating costs. This led to the adoption of SRE by other companies. Today, SRE is a well-established discipline that companies of all sizes use. Below are some major events in the development of SRE:
Before proceeding further, let’s cover some key terms related to site reliability. These will help you learn the concepts of SRE:
Service level agreement (SLA) is a contract agreed on between the customer and the business (service provider). An SLA is a document that records and dictates all the service levels that a business is offering with different metrics that those services should meet for a customer to be satisfied.
The SLA also records the implications or consequences the business should bear when a service level breach occurs. The consequence might be penalties a business should pay or the termination of a contract.
For example, say a business and customer agrees on a support SLA. The SLA states that any issue raised or support requested by a customer will be fulfilled within 24 hours. If the support team fails to respond or provide resolution within 24 hours, it will be considered a breach of the SLA and business would face consequences.
A typical SLA would have the following definitions:
A service level indicator (SLI) is a metric used to measure the performance of the system or service. These are specific quantifiable values of a system that help engineers to understand the behavior and performance of the system or service.
By monitoring SLIs, engineering teams can gain insights into the health of the system. Using these indicators, helps engineers make data driven decisions, identify areas of improvement, and take preventive measures.
As an example, assume that service level objective is set to meet an accuracy of 95 percent in generated monthly reports. In this case, the SLI will be the actual accuracy attained in the report. The actual accuracy of data may be 99 percent, 100 percent, or even 94 percent.
These are the SLIs attained against the SLO. SLI helps the SRE team know whether its objective is being met, or what actions should be taken to meet the objectives.
Many different SLIs are tracked by organizations based on their nature of business. For any website, the following would be the common SLIs tracked and measured:
Service level objectives are specific targets or thresholds set for service level indicators (SLIs) that define the desired level of service quality, reliability, and performance for a system or service. There can be one or more SLOs in an SLA based on the agreement between the service provider and the customer.
Imagine the SLO for a website is to be available 99.9 percent of the time with a max downtime of two hours once a month.
The mean time between failures is the average time between two incidents. The MTBF is always calculated for a certain period such as 24 hours, six months, etc. It is an essential metric that the SRE team tracks to understand how reliable their systems are.
The MTBF can be calculated by dividing the number of hours the system is operating by the number of times system failures occurred in that period.
For example, let’s calculate the MTBF of a site for the last 24 hours. Imagine the system had four failures and it took 15 minutes every time to fix it and bring the site back up.
To calculate the MTBF, consider 23 hours of operation time with 1 hour of downtime, due to 4 failures. The MTBF will be:
23/4 = 5.75 hours
This implies, on average, the system is up for 5.75 hours before the next failure. Knowing this metric, the SRE team will work towards increasing the MTBF to make the system more reliable.
The mean time to repair is a metric that measures the average time it takes to repair or recover from a failure or incident. It measures how long it takes to repair a system or component after it has failed.
The MTTR helps assess the efficiency and effectiveness of incident response and recovery processes. A lower MTTR indicates a more efficient repair process. A higher MTTR indicates a less efficient repair process.
MTTR can be calculated by dividing the number of hours taken to repair a system by the number of times a system is being repaired.
Let’s say a system was down for repair 15 times in 3 months and the total hours it took to restore a system was 30 hours. This means customers faced a downtime of 30 hours in the last 3 months.
The MTTR can be calculated by:
30 / 15 = 2 hours
This implies, on average, the SRE team’s repair process takes 2 hours to get the system up whenever a failure occurs.
SRE defines availability as whether a system can fulfill its intended function at any given point in time. It is a measure of how long the system or service is available for users. Availability usually refers to the uptime a site is running.
The availability of a system can be measured in two different ways:
Time-based availability = uptime / total time (where total time is uptime + downtime of the system in a given period)
Aggregate availability = number of successful requests / total number of Requests
Observability is the ability to gain insight into the internal state and behavior of a system based on its external outputs and interactions. In SRE, it plays a crucial role in understanding, diagnosing, and troubleshooting complex systems.
SRE teams collect and analyze metrics, logs, and traces to gain a deeper understanding of how their systems are performing. This enables engineers to identify and fix problems before they cause any failures.
Observability has three main pillars:
Response time is the time it takes for an engineer to respond to an alert or incident. This is a critical metric as it has a significant impact on the availability and performance of systems.
SRE teams can improve response time by investing efforts in diagnosing delays or inefficiencies in responding to incidents, automating almost everything possible, providing training and education, and creating a feedback loop.
Latency is the time it takes to serve a user request by a system or service. It represents the delay in the system to respond to user queries. SRE teams should keep calculating the response time a system or service takes to serve any request.
SRE teams calculate the latency of successful and failed requests separately rather than as a whole. It is possible, an error request might be faster in responding than a successful request.
The rate of requests that fail for a given period of time either explicitly via server or network issues, implicitly via code errors, or through SLOs via SLA breach. SRE teams monitor these errors separately and work towards reducing these errors.
An error budget represents the number of acceptable errors or downtime that a system or service can experience within a defined time period, typically measured as a percentage.
An error budget is calculated by subtracting the system’s SLO from 100 percent. For example, if a system has an SLO of 95 percent, its error budget is 5 percent. This means that the system can experience 5 percent of errors that customers can or are ready to tolerate.
Error budgets help SRE teams decide on prioritizing resources between new feature delivery and reliability improvements.
Saturation refers to how much load or requests a service can handle. SRE teams use saturation to understand how many requests a service can take. SRE teams answer questions such as whether a service can respond the same on 10 percent more load than usual.
It’s possible that a system degrades in performance for even 50 percent of its capacity. SRE teams measure saturation to develop efficient resource utilization in systems. When a system reaches saturation, it can experience increased latency, reduced performance, or increased errors.
Hence, it is critical for SRE teams to measure saturation and define the capacity the service can handle.
The main goal for building SRE is customer satisfaction. Any organization that has or wants to build an SRE team should adhere to these seven core principles:
This principle states two important factors to learn and implement:
Instead of trying to eliminate risk entirely, teams should focus on identifying and managing risks. SRE teams should focus on potential failure points, developing mitigation strategies, and monitoring systems for any signs of trouble.
Think of a large system connected to hundreds of devices at a customer’s location. Every time a new device is purchased by a customer, a system engineer (operations) will have to visit the customer site, register the device to the system, and update its software.
In terms of scale, if there are 400 customers and every customer is located in a different location, you will have to hire operation resources as and when volume increases.
Toil is repetitive, manual work that doesn’t add any value. SRE teams should work to automate as much toil as possible, freeing up their time to focus on more strategic tasks. Eliminating repetitive work helps organizations scale with the same or lessened cost of maintaining a system or service.
By automating, SRE teams save at least 50 percent of their time in performing these repetitive tasks and focus more on other strategic assignments.
Monitoring systems is the process of collecting and analyzing data about a system to identify and address potential problems. SRE teams use monitoring data to ensure that systems are reliable, scalable, and secure.
There are four key aspects of monitoring:
Release engineering is the process of safely and reliably deploying changes to production systems. SRE teams work with development teams to develop and implement a release process that minimizes risk and disruption. Release engineering focuses on the management, coordination, and automation of the software release process.
A good release process would:
By incorporating these release engineering principles into their overall SRE practices, teams can effectively manage software releases, minimize disruptions, and maintain system reliability during the deployment process.
Implementing automation within your product team:
Many common tasks are automated by SRE teams. Some to list are:
SRE teams can use a variety of automation techniques, such as:
Automation is a continuous process. As systems evolve, SRE teams must continue to automate new tasks and improve existing automation.
Simple things are easy to understand, maintain and improvise. If a system has a complex architecture, you will always need creators around to fix if anything goes wrong.
Simplicity is one of the core principles of SRE. It is the idea that systems should be designed and built in a way that is easy to understand, maintain, and operate.
Keeping systems simple allows for:
You can achieve simplicity in your systems by:
Organizations can define various roles under their SRE practice group per the need or demand they have in their environment, but you will find these common roles any organization:
At the moment, there’s a debate to differentiate SRE and DevOps. Some say they’re the same thing with different names. Some say DevOps is a broader framework and SRE is part of it.
To understand the difference between the two, see the following:
| Area | DevOps | SRE |
| Primary Focus | DevOps focuses on the collaboration and integration of development (Dev) and operations (Ops) teams to streamline software delivery and improve the overall software development lifecycle | SRE focuses on the reliability, availability, and performance of software systems and services. It aims to ensure that systems meet defined service level objectives (SLOs) while enabling innovation and scalability |
| Primary Work Area | DevOps work from product development to delivery. They streamline the entire operations of development, review, and release of software. They primarily work with development teams | SRE teams work on maintaining the reliability of systems that are live. They are involved with pre-delivery projects with software teams at a very minimal level to help software teams develop reliable systems. They primarily work with operation teams |
| Primary Responsibility | DevOps solve development problems, build and release problems, downtime, and deployment problems | SRE teams solve production failures, incident analysis and responses, production health, and overall reliability of systems |
| Cross-functional collaboration | DevOps is based on org size and can be a separate team or work in the development team itself. However, DevOps engineering collaborates with cross-functional teams to achieve smoother software delivery | SRE is a separate group of SRE engineers built in any org with the goal to achieve systems reliability, performance, and quality in production systems |
| Primary Goal | Develop and deliver new features to production faster in a smoother process | Ensure SLOs are met with customer agreements and no failures occur in systems running live |
| Tools Used | DevOps mostly use CI/CD tools like Jenkins, Jira, Git, Circle CI, etc. for attaining continuous smoother integration and release | SRE on the other hand uses tools like Prometheus, Grafana, Graylog, Skywalk, etc. to observe, monitor, analyze and fix reliability in systems |
There are many benefits to having a fully functional SRE team built in your organization. The main reason for building SRE is to bridge the gap and solve the disconnect between development and operation teams. Alongside this, SRE contributes to:
Product managers spend their time focusing on keeping their customers content with new features, enhancing existing features, enriching user experience, and providing high-quality services to their customers.
You can leverage the expertise that SRE teams bring in to manage the products and services you offer to your customers.
As a PM you can practice SRE by:
SRE is a discipline practiced to solve reliability, performance, and quality issues that customers face on large-scale, distributed systems. It is critical to businesses that systems are always available to their customers and functioning.
SRE teams monitor production systems, automate repetitive tasks, analyze incidents, and ensure uptime, latency, performance, and reliability issues are solved. As a PM, one should work closely with the SRE team to define SLOs and SLIs to track and measure the reliability of the system.
Remember, the SRE is a continuous process and PM’s continuous involvement in SRE is very important in maintaining site reliability.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.

Memos don’t have to be complicated. Just keep them clear, concise, and focused on actionable items. More on that in this blog.


