I used to run AI projects just like I would ordinary features: spec, build, QA, launch. The calendar moved, the charts rose, and the team checked boxes. Then, the models kept changing after launch. Inputs shifted, users adapted, data aged, and the work kept going.

After tripping over the same problem a few times, I realized my mindset, not my tools, was the problem. I was trying to manage probability with a deterministic frame.
So, I tried something different: a portfolio-style operating model. Thinking along the lines of a good investor, I learned to size my bets, manage risk, and rebalance instead of pretending every model is a “done” project.
The new AI-focused product landscape demands a new framework for building those products. In this article, I’ll show you how I figured out an approach that works, and demonstrate how you can apply it too.
Traditional product work rewards certainty. You’re heard the questions before. Did we ship? Does it match the spec? Are there bugs?
But machine learning produces distributions. Your job as a PM shifts towards shaping the odds and aligning expectations.
Because of this, it’s time for you to start thinking probabilistically, not deterministically. In simple terms: trade “Is the model right?” for “When is the model useful, at what risk, and for whom?”
That single shift reduces product drama and improves your timing. Debates turn into trade-offs that fit on a single page.
By thinking this way, you’ll be able to:
Probabilistic thinking raises standards because thresholds and trade-offs become explicit and testable.
If you’ve ever felt whiplash from an AI launch, great demo, or messy reality, you’re not alone. You’re not bad at your job. You’re just using a hammer on a screw.
The first step is to treat each model as an asset in a portfolio. Give it a class, a size, and a cadence according to these categories:
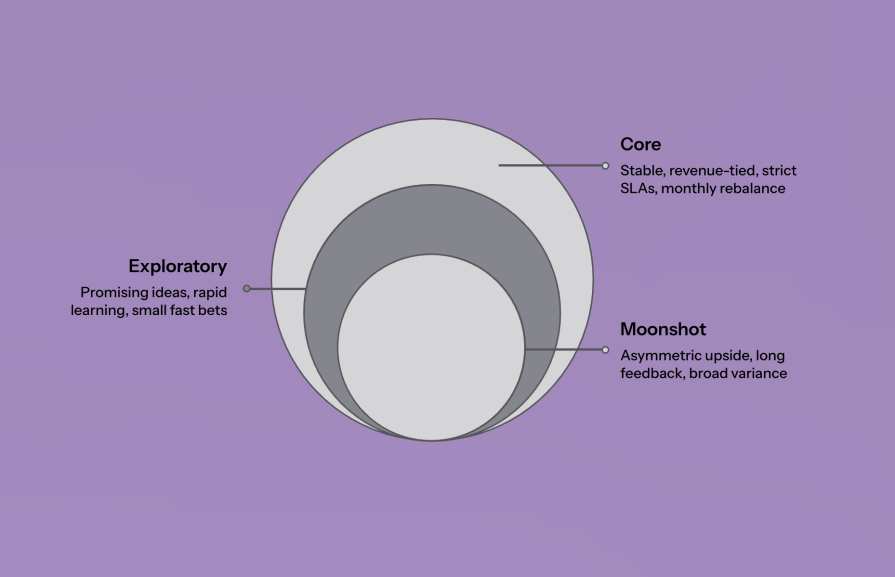
Here, sprints remain useful, while the true unit of progress becomes your bet — an experiment, a threshold change, or a rollout slice. Ownership shifts from “the model’s opinion” to “the system around the model,” guardrails, fallbacks, monitoring, and recovery paths.
As the PM, it’s up to you to determine:
To help get you started, let’s walk through my four part approach that you can take back to your product team:
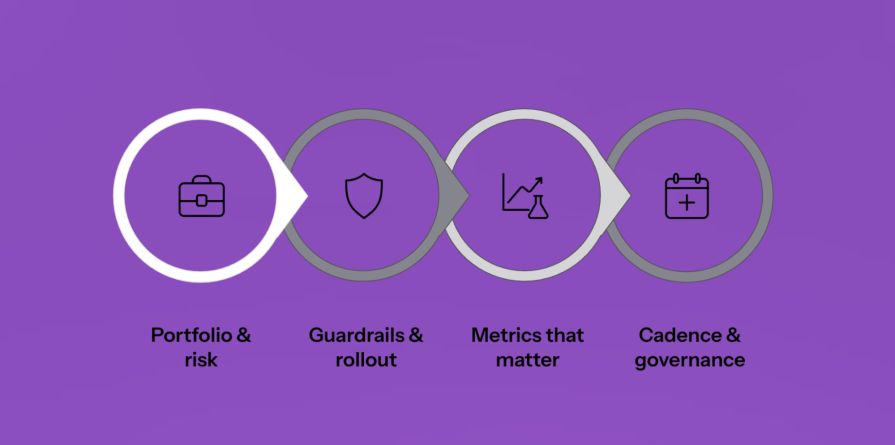
Now, keeping my approach in mind, let’s take a look at how I implemented it with my teams.
A support team I worked on built an internal writing assistant for agents. Our demos impressed, and the production revealed variability across intent, tone, and macro freshness. We sized the bet and optimized for fast feedback.
Guardrails included citations, refusals on sensitive topics, and a single-click return to the legacy macro. The rollout started with twenty agents across two queues.
Our median time-to-first-response went down 18 percent, escalations went down nine percent, and the edit distance on drafts even trended downwards. The risk budget permitted extra verbosity in exchange for a lower rate of incorrect factual claims.
Monitoring showed spikes in complaints when fresh macros launched. To address this the team added an automatic dampener that tightened phrasing for 48 hours after macro changes, then relaxed as feedback stabilized.
We looked for consistent improvement across the top ten intents, a strict complaint threshold, and steady behavior through a seasonal surge. Graduation moved the assistant from exploratory to core with monthly rebalance.
Another time, my team rebuilt a weekly demand forecast for a multi-region catalog. Feedback cycles stretched across months, with holiday periods revealing the truth. The team invested in calibration, feature stability, and scenario stress tests. Shadow mode ran six weeks. Rollout advanced by region pairs with planner sign-off.
Our service level went up three points and inventory carry costs went down by double-digit percentages. Guardrails capped week-over-week forecast deltas and provided planner override during promotions.
The risk budget set tight error bounds for peak months and wider bounds for shoulder seasons. When a pricing engine update shifted demand elasticity, drift monitors alerted planners within hours and the system reverted elasticity for affected SKUs until retraining finished.
We looked for performance above baseline across seasons, resilience through pricing and catalog shifts, and SLA compliance during the holiday window. Graduation advanced the model into core with monthly governance and quarterly scenario tests.
Our assistant fails loudly and cheaply, one answer at a time, leading to rapid iteration with strong content guardrails and compounding gains. On the other hand, the forecaster fails quietly and expensively, systemic decisions, leading to slower promotion with strict governance protects margins.
One company, two models, two operating modes, but one portfolio lens.
This operating model delivers simple advantages:
Results appear through calmer on-call weeks, steadier margins, satisfied users, and a roadmap that ages with grace.
Some things break loud and fast. Others drift quietly until the numbers don’t add up.
We learned that the hard way, running the same rituals for every AI project. Daily standups, sprint points, feature flags, they worked for shipping fast, but not for staying right.
A generative assistant needs speed, feedback, and permission to be a little weird. A forecasting model needs stability, patience, and zero surprises.
That’s why we switched to a portfolio approach.
Label the model: Core, exploratory, moonshot. Match the rhythm to the risk. Fast loops for small bets. Tight guardrails for big ones.
Some models grow into core. Some stay weird. Some quietly disappear.
That’s the job. It sounds simple, and it is. But it works.
As you work through your portfolio, keep the following terms in mind:
| Term | Short definition | Example in practice |
| Risk budget | Agreed tolerance for error in pursuit of value | “Accept two percent false positives for approximately five percent conversion lift on cold traffic” |
| Expected return | Outcome forecast at the chosen tolerance | “Forecast plus four to six percent lift in assisted resolution rate at this threshold” |
| Monitoring cost | Time and spend required to keep the model healthy | “Two analyst days per month and one on-call rotation for drift checks” |
| Rebalance schedule | Rhythm for shifting attention and budget based on evidence | “Weekly for exploratory, monthly for core, milestone gates for moonshots” |
| Graduation criteria | Evidence that advances a model’s class | “Beat baseline across seasons, sustain SLA during peak, pass scenario stress test” |
| Cost-of-error | Business impact when the model errs | “Refund rate, false decline rate, SLA breach count, on-call hours” |
| Guardrail | Boundary or fallback that limits harm and preserves trust | “Refuse sensitive topics, cap delta on forecasts, provide one-click revert” |
| Bet size | Scope and surface area of the model’s influence | “Start with five percent of traffic, expand by task family after evidence review” |
Language shapes behavior. This glossary keeps legal, data science, ops, design, and finance inside the same frame and reduces translation overhead.
The product environment runs on probability while many habits still expect certainty. A portfolio operating model aligns the work with reality.
To get started, classify assets, budget risk, and set guardrails. Measure outcomes and the price of error. Then, rebalance on schedule and promote with evidence.
Ship certainty for problems that reward fixed rules. Ship odds for opportunities that reward learning and iteration. Own the system around both, and value compounds.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

Learn how PMs can use AI and communication to spot duplicate work early, align teams, and protect engineering capacity.

Audit freemium conversion points by use case to cut clutter, improve UX, and protect long-term revenue from upgrade fatigue.
PMs often misread acquisition spikes as growth. Learn which retention and activation signals show whether users actually find value.

The LogRocket MCP connects your AI agents to Galileo AI. Detect issues, diagnose root causes, and ship fixes from Claude, Cursor, Codex, or your own agent.


