Data modeling is important in information management as it serves as the basic structure upon which robust databases and efficient information systems are developed.
In this article, you’ll learn about the details of data modeling, exploring each type, components, and common mistakes, as well as key data modeling terminology.
Data modeling is a systematic representation of data, including its relationships and limitations. It governs how data in a database are structured and organized, as well as how they can be stored, retrieved, and modified. Data modeling may be used to analyze data, build databases, and develop systems.
Data modeling can be represented using various data techniques such as data flow diagrams, entity-relationship diagrams, and class diagrams for building simple or complex systems. It provides an understanding of the data requirements and helps to ensure data consistency and requirements.
There are three types of data models: conceptual, logical, and physical.
The conceptual model, sometimes referred to as the business model or semantic model, describes how a business uses data to run its operations. It defines the core entities of a business such as products, invoices, logistics, etc. The goal of the conceptual model is to get every entity to interact with each other on a high level.
The conceptual model doesn’t need any technical system or solution. If defined properly, it becomes valuable no matter the project or tool you apply. Data is represented using an entity-relationship (ER) diagram.
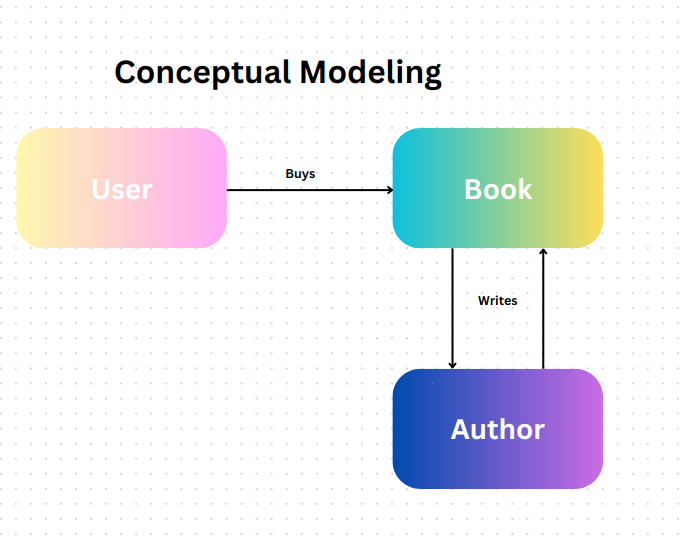
Choosing the right entities for the business is essential while working with conceptual modeling to prevent system failure. The appropriate entities involve the things you have data about and are countable such as customers, products, orders, etc.
The category versus instance problem should also be considered while selecting your entities. Is your entity an actual object (instance) or a type of thing (category)? Are you choosing a car or a type of car as an entity?
Define your entity and provide more details about the things you’re describing. For instance, in a transport system, you could have a bus entity, which could be a logistics, booking, or ticketing entity.
When you attempt to model an entire system at once, from beginning to end, you risk becoming bogged down in details and losing sight of your goals. It’s possible to develop separate models and connect them with a single entity.
Data modeling can’t be conceptualized without understanding the actual business, value, and stakeholders involved. The business expert or stakeholder and the data architect must work together.
The logical model is an implementation design for a particular use case. For instance, building a data structure to enable a particular use case, such as reporting or self-service analytics. By applying technical detail or a solution, the logical model converts the conceptual model into an application-specific model.
Here, more detail is provided and your data model becomes less comprehensible to non-technical stakeholders. It uses schema to represent data. A logical model aims to provide a technical understanding of the data structure.
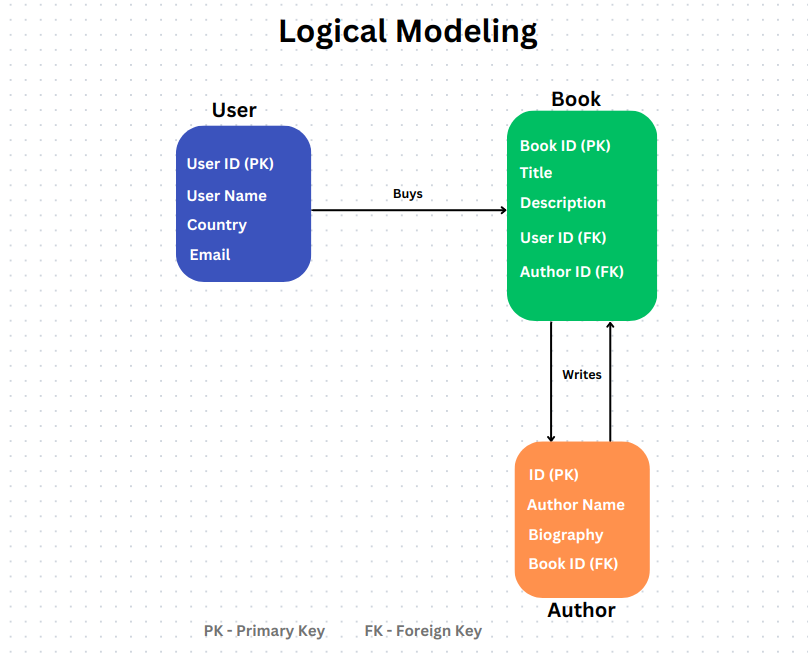
Ignoring the conceptual modeling stage is a common mistake made when developing a logical model for a system. The logical model for creating a seamless data model is based on the conceptual model. It’s important to first understand the system at its conceptual level rather than diving right into its technical details.
When choosing your methodology, you need to understand the rules that govern it. Each method that you can use has its own features and the conceptual model should guide you towards a structure that reflects the business reality by using features from the methodology.
The physical data model is a representation of relational data objects (such as tables, columns, primary and foreign keys) and their relationships in a database. Creating physical data models is often the responsibility of developers and database administrators. A vital component of software applications and information systems is their ability to interact with properly designed databases.
Once data from an existing application gets loaded into databases, it’s difficult to modify the physical data models. The logical data model provides a framework for the physical data models and their attributes and names don’t have to be the same as the physical data model tables and columns.
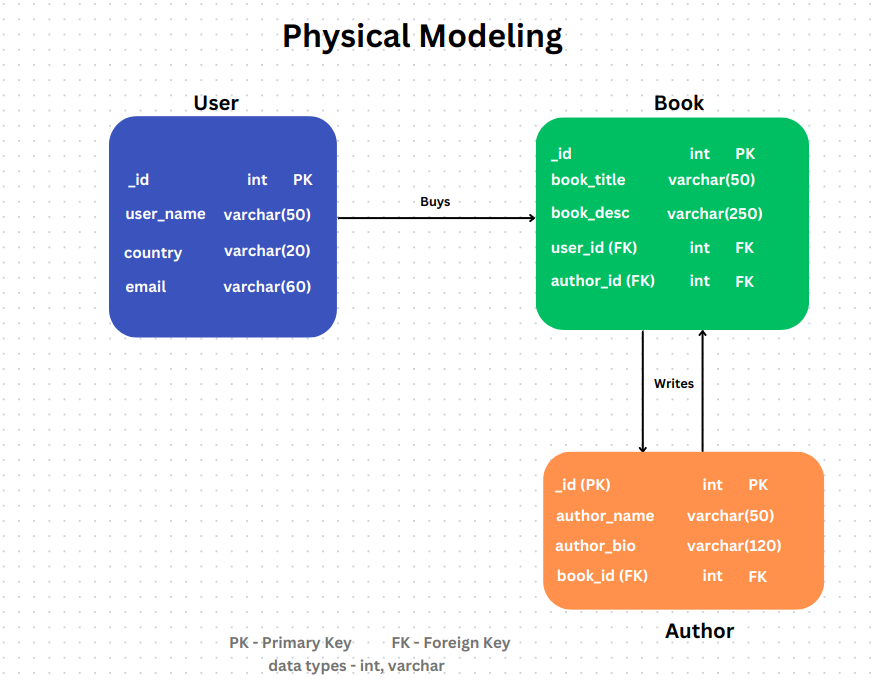
Ignoring normalization rules in physical data modeling involves failing to eliminate redundant data and not organizing data into tables efficiently. This mistake can lead to data redundancy, inconsistent information across the database, and challenges in maintaining and updating the system due to a lack of adherence to established normalization rules.
Overlooking indexing in physical data modeling involves neglecting to define appropriate indexes for database tables. This mistake can result in poor query performance as the database engine has to scan the entire table to find the required data. Adequate indexing is crucial for optimizing query execution, reducing response times, and enhancing overall database performance.
This refers to the common mistake of choosing inappropriate data types for columns in a database. This could involve using unnecessarily large data types, leading to wasted storage space and slower query performance, or selecting insufficiently precise types, risking data integrity issues.
Inconsistent naming conventions involve using varied or unclear naming patterns for tables, columns, indexes, and other database objects. This mistake hinders the readability and understanding of the database schema, leading to confusion among developers and potential errors in the application code.
Data modeling incorporates various terminologies that describe different aspects of organizing and representing data within a database. Here are some common data modeling terminologies that you should know:
A table is a collection of related data organized in rows and columns. Each table represents a specific entity or concept within the database, and each row in the table corresponds to a specific record or instance of that entity.
Relationships define how entities are connected or associated with each other in a data model. They indicate how data in one entity relates to data in another, often expressed as one-to-one, one-to-many, or many-to-many relationships, providing a structure for organizing and linking information in the database.
A schema is a collection of database objects, including tables, views, indexes, and more, that defines the structure of the database. It provides a logical framework for organizing and representing data.
A primary key is a unique identifier for each record in a database table. It ensures that each row can be uniquely identified and is often used to establish relationships between tables.
A foreign key is a field in a database table that is used to establish a link between the data in two tables. It creates a relationship by referencing the primary key of another table. Foreign keys enforce referential integrity, ensuring that relationships between tables remain consistent.
An index is a data structure that enhances the speed of data retrieval operations on a database table. It’s created on one or more columns of a table and provides a quick reference or pointer to the data, facilitating efficient querying. However, excessive or unnecessary indexing can lead to increased storage requirements and maintenance overhead.
A data type defines the kind of values that a column can hold, such as integers, characters, dates, or floating-point numbers. For instance, a “date of birth” column might use the date data type, while a “product price” column could use a decimal data type to represent monetary values.
An entity in data modeling represents a real-world object or concept, such as a person, place, thing, or event, which can be uniquely identified and described by its attributes. Entities are typically depicted as tables in a database schema, with each row representing an instance of the entity and columns representing its attributes.
Attributes are the properties or characteristics that describe entities in a data model. Each attribute corresponds to a specific piece of information about an entity, and they are represented as columns within a table. For example, a “person” entity might have attributes such as “name,” “age,” and “address.”
Cardinality defines the number of instances in one entity that can be associated with the number of instances in another entity within a relationship. It is often expressed as one-to-one, one-to-many, or many-to-many and helps define the nature of the connections between entities in a data model.
Normalization is the process of organizing and structuring data in a database to reduce redundancy and dependency. It involves breaking down large tables into smaller, related tables and is aimed at improving data integrity and minimizing anomalies in the database.
Denormalization is the opposite of normalization, involving the introduction of redundancy into a database design to improve query performance. While normalization focuses on reducing data duplication, denormalization may be used strategically to optimize data retrieval in scenarios where performance is a higher priority than data redundancy.
A detailed review of data modeling shows its vital significance in database design and implementation. Entities, attributes, relationships, and other key elements are carefully designed to generate an organized and efficient structure, allowing organizations to manage their data with accuracy and flexibility.
As technology advances and data complexity increases, data modeling remains an essential factor in a seamless integration of information systems, supporting not only the security of data but also you to derive useful insights from your constantly growing records.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.

Memos don’t have to be complicated. Just keep them clear, concise, and focused on actionable items. More on that in this blog.

Learn how tech PMs can take over inherited products, gather context, clean up backlogs, find quick wins, and make smarter decisions.


