As AI systems move from prototypes to production, teams quickly discover that rising costs and inconsistent accuracy are rarely caused by the model alone. Architecture, data preparation, retrieval design, and system constraints all shape how an AI feature behaves in real use. One of the most overlooked factors in this process is chunking, which refers to the way information is split before it’s embedded and retrieved.
Chunking is often treated as a minor preprocessing step, but it plays a central role in cost and accuracy. Poor chunking increases embedding and storage costs, reduces retrieval precision, and forces models to work with irrelevant or incomplete context. These issues show up in production environments as slower responses, higher infrastructure spend, and answers that feel inconsistent or unreliable to users.
Even teams using advanced models and modern retrieval systems can struggle if their chunking approach is misaligned with their data and usage patterns. Teams that design chunking deliberately often achieve more accurate results at a lower cost while relying on simpler models and infrastructure. In many systems, chunking quietly determines whether an AI feature scales reliably or degrades under real-world conditions.
This article explains how poor chunking drives up AI costs, undermines accuracy, and affects user trust, and why teams should treat chunking as a core engineering and UX design decision rather than an afterthought.
Chunking is the technique of breaking down huge amounts of text or structured data into smaller, coherent parts before encoding them in vector embeddings. These components, known as chunks, serve as the fundamental building blocks for retrieval. When a user asks a question or initiates an AI workflow, the system examines the chunks that represent those documents rather than the whole documents.
Although chunking may appear to be a simple step, it typically determines the overall effectiveness of a retrieval process. Poorly chunked data can cause confusion in embedding models, give irrelevant search results, and compel language models to operate with mismatched or missing material.
Properly chunked data, on the other hand, is consistent with how the content is structured and how the user thinks, allowing retrieval to bring out the most useful, context-rich pieces.
In essence, chunking is the art of carving information into pieces that are small enough to process efficiently but large enough to remain coherent.
One of the most important decisions in chunking is choosing the right chunk size. Chunk size directly affects both retrieval precision and the model’s ability to interpret context.
Larger chunks preserve more context by including broader sections of text. This can be useful when a user’s inquiry spans multiple ideas or when the relevant information is embedded within a long paragraph rather than a single sentence. However, larger chunks often include irrelevant material, which can dilute relevance during retrieval and confuse the model during generation.
Smaller chunks, by contrast, improve retrieval precision by isolating individual ideas. When a user asks a specific question, the retrieval system is more likely to surface a clean, highly relevant passage instead of a noisy block of text. However, many questions depend on background that extends beyond the confines of a small chunk. In those cases, the system must retrieve and combine multiple chunks, increasing the risk of incomplete reasoning, stitch errors, or hallucinations.
Determining the right chunk size for you depends on the structure and intent of the content. The table below summarizes the key differences between them:
| Chunk size | Advantages | Disadvantages | Best suited for |
| Large chunks | Preserve broader context; useful for questions spanning multiple ideas or long passages | Introduce irrelevant information; reduce retrieval prevision; can confuse the model during generation | Legal documents, policy texts, content where clauses depend on surrounding context |
| Medium chunks | Balance context and precision; represent complete concepts | Still risk partial noise or missing adjacent context | Technical manuals, documentation subsections, feature explanations |
| Small chunks | High retrieval precision; isolate individual ideas or facts | Lack sufficient context; require stitching multiple chunks, increasing error and hallucination risk | FAQs, knowledge bases, fact-based reference content |
One of the first advantages teams notice after improving their chunking method is reduced operational costs. Embedding models typically charge per token, while vector databases charge for storage, indexing, and retrieval operations. Inefficient chunking increases all of these costs without delivering better retrieval quality.
Overly large chunks are expensive to embed because every token must be processed, even when a lot of the content is irrelevant to retrieval. Larger chunks also inflate storage requirements, since fewer but heavier vectors need to be stored and indexed. In addition, poor retrieval precision causes the system to return more data than necessary, increasing downstream costs during reranking or response generation.
On the other hand, when chunks are too small, the system generates additional total chunks. Even if each chunk is cheap to embed, the overall number of embeddings increases dramatically. This leads to higher storage and indexing overhead, as well as increased retrieval latency as the system scans more vectors per query. Small chunks also force the model to aggregate many retrieved segments to answer a single question, increasing the number of retrieval calls and the volume of tokens passed into the model during inference.
In both cases, poorly chosen chunk sizes drive up cost by increasing token usage, storage footprint, and retrieval complexity.
While cost matters, chunking has a far greater impact on accuracy and reliability. Retrieval-augmented generation (RAG) systems are fully dependent on the quality of the knowledge they present. If retrieval surfaces irrelevant, fragmented, or misleading chunks, even the best language model will produce incorrect or unstable results.
Chunking influences accuracy in three interconnected ways:
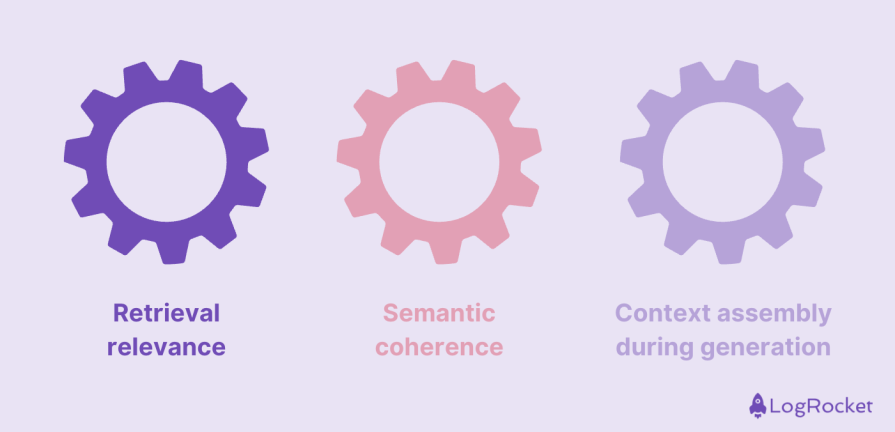
Well-designed chunks represent a single, coherent idea, producing embeddings that accurately reflect that concept. When a user asks about that idea, similarity search works as expected. In contrast, chunks that bundle multiple topics create blended embeddings that fail to align clearly with any one query. The system may retrieve a chunk that is only loosely related, reducing precision and introducing noise into generation.
Embedding models assume that the text they encode follows a consistent semantic theme. When chunking cuts across natural boundaries, such as dividing a paragraph mid-sentence or merging unrelated sections, the resulting embeddings become less meaningful. In these cases, the retrieval system then returns unclear chunks, causing answers to be unstable.
Chunking also determines how effectively the model can assemble context at inference time. Fewer, more coherent chunks give the model clear signals and reduce the need for inference-time guesswork. On the other hand, retrieving many small fragments or large, noisy chunks forces the model to infer missing relationships or discard irrelevant information, significantly increasing the risk of hallucinations and omitted details.
In practice, chunking decides whether the AI system understands your data correctly. It shapes the retrieval signal, constrains what the model can reason over, and serves as the foundation for all subsequent reasoning steps.
Although chunking happens behind the scenes, its effects are immediately visible to users. Perceived intelligence, responsiveness, and reliability are core parts of the AI user experience, not just the interface design. Poor chunking often surfaces as vague answers, inconsistent responses to identical queries, or outputs that include irrelevant material.
Users quickly notice when an AI system behaves inconsistently. Responses may feel bloated one moment or incomplete the next. The same question may yield different answers across sessions, undermining confidence in the system. These issues are often misattributed to model quality or prompt design, when inefficient chunking is frequently the root cause.
Well-designed chunking improves both accuracy and perceived performance. Relevant information is retrieved faster, responses are more focused, and the system relies on cleaner context during generation. Because the model operates on well-structured inputs, answers feel more decisive and grounded. Reduced retrieval overhead also improves latency, making interactions feel smoother and less cognitively demanding.
For this reason, chunking should be regarded as both a technical and UX and decision. It directly shapes clarity, speed, and trust, all essential components of a positive user experience in AI-powered products.
As organizations develop AI capabilities, chunking transitions from a one-time preprocessing step into an ongoing engineering concern. It becomes part of the data pipeline, retrieval architecture, and long-term system maintenance rather than a static configuration choice.
Effective chunking requires balancing multiple production constraints, including document structure, model token limits, latency targets, content update frequency, and storage and inference budgets. It also depends on how users actually ask questions and which information they expect to receive first, not just how the source documents are organized.
Teams that take chunking seriously treat it the same way they treat indexing or caching. They iterate on chunking strategies as content grows, benchmark retrieval quality and latency, monitor precision and recall metrics, and continuously refine preprocessing logic.
PMs that adopt this mindset consistently achieve higher retrieval accuracy, lower operational costs, and more predictable user experiences.
There isn’t one correct way to chunk content. Each approach reflects a tradeoff between its ease of use, semantic accuracy, and system cost, and the right choice depends on the structure of the data and how it will be queried.
Most teams start with simple token based splitting, but more structured approaches typically produce better retrieval outcomes. Fixed length chunking is easy to implement and computationally predictable, but it ignores semantic boundaries, often cutting across ideas in ways that degrade embedding quality.
Sentence level chunking improves semantic consistency by keeping individual thoughts intact, but it can be too granular for long form reasoning or topics that rely on surrounding context.
For structured content such as manuals, policies, and technical documentation, header based chunking tends to perform better because it respects the document’s natural hierarchy and groups related information together. This approach aligns well with how users scan and reference long form material.
Semantic chunking goes a step further by using models to identify natural topic boundaries within text. This approach usually produces higher quality embeddings and cleaner retrieval, but it comes at the cost of additional computation and preprocessing complexity.
In highly technical domains such as source code, specifications, or research papers, sliding window or hybrid strategies are often more effective, preserving local context while keeping chunk sizes within practical limits. Production systems often combine multiple approaches based on content type, retrieval goals, and performance constraints.
You should treat chunking as a measurable system property, not a guessing game. Effective chunking improves retrieval precision by reducing the number of chunks required to answer a query, lowering embedding and storage overhead, and decreasing end to end response latency. It also produces answers that are more accurate, consistent, and faithful to the source material.
Evaluating chunking quality requires a combination of automated metrics and human review:
Together, these approaches create a feedback loop that allows you to iteratively refine chunking strategies as content and usage patterns evolve.
Chunking is one of the most important, yet least discussed, factors in developing reliable AI systems. It directly shapes cost structure, retrieval accuracy, user trust, and model behavior. As models improve and source material grows more complex, teams that treat chunking as a core capability rather than a peripheral task will succeed.
When done well, chunking is efficient and largely invisible. However, when done poorly, the symptoms are immediate and clear to your users. Hallucinated details, slow responses, and irrelevant context are rarely model failures alone. They signal breakdowns in the retrieval layer, often rooted in weak chunking strategies.
For product managers building AI powered features, understanding chunking is essential. It directly influences reliability, performance, and user trust, and ultimately determines whether an AI system can scale from a promising demo into a dependable product.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.
Learn how PMs can use AI evals to diagnose output quality issues, set pass criteria, and improve AI features with less guesswork.

Learn how PMs can replace bloated PRDs with lightweight docs that align teams, reduce risk, and keep AI-assisted development moving.

New from LogRocket: Galileo AI now spots your highest-impact bugs and dispatches them to AI agents in Cursor, Claude Code, or Codex to fix.

Learn how PMs can use AI and communication to spot duplicate work early, align teams, and protect engineering capacity.


