Being data-driven isn’t about excelling in Python, being an Excel god, or being great at SQL queries. It’s about asking the right questions so that you can get a relevant, true, and measurable answer. I believe the trickiest part of the last sentence is the word “true.”

Have you ever heard the joke that statistics are the highest form of a lie? I bring this up because numbers aren’t just numbers and their origin and features are important when presenting any results. What if there was a way to achieve those true, measurable results in a reliable way?
There is one universal solution: A/B testing! What is it? And how can you ensure its results are really rock solid? Stick around for today’s article!
A/B testing, also known as split testing, is a method of comparative analysis where two versions of a product change (A and B) are tested against each other to determine which one performs better against a specific metric. Of course, you can test with more variants and look at different metrics, but A/B/C/…/Z testing doesn’t roll as easily from the tongue.
To put it in a simpler, yet abstract way, A/B testing can be easily compared to watching events in two (or more!) parallel dimensions and then being able to choose to live in one you like most!
The greatest advantage over other forms of testing is the faith in the results by default. The test’s audience and conditions are the same; the only real change in the product is the one you introduced. Thus, if any metric changes in any of the testing groups, it can be attributed to the change alone. There are a few exceptions to that, but I will get to that.
Now, let’s look at a basic outline of the process of performing an A/B test:
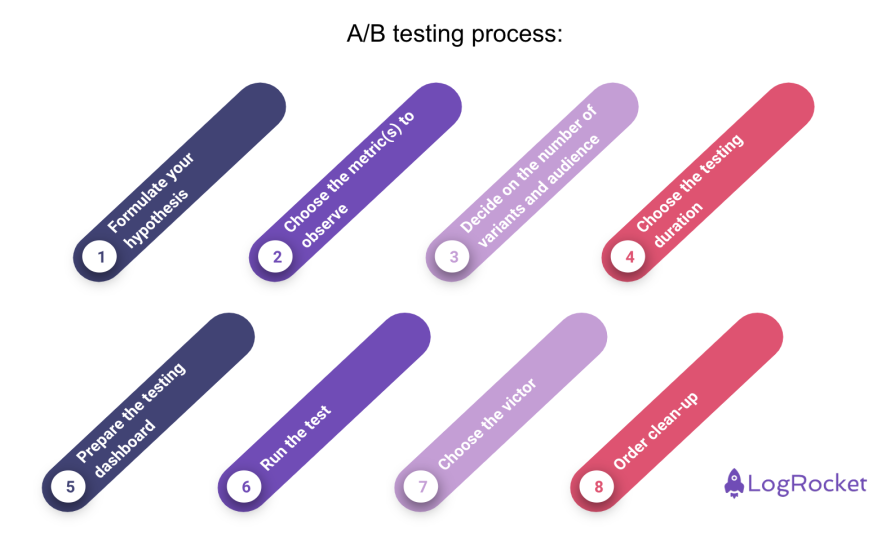
As with anything in product management, you need to start with a problem to solve. Once you know what you want to address, you can decide on the solution that will be A/B tested.
An example here would be: “Changing the string of a button will increase the number of registered users.”
Every goal you set as a PM needs to be measurable and represented by a metric. Thus, with your A/B tests, you need to select a KPI that determines which test variant is the winning one. It’s also important to know the typical measurement error rate on the metric you choose.
In my career, I usually want to see at least 5 percent change to make sure that the change brought a significant impact. However, you can also use a dedicated calculator, but that’s more on the data analysis part after the test.
That being said, the data analysis software can come with an inherent measurement error that you need to take into account when setting your tests’ goals. Your business/data analyst should be able to help with this.
Now this can be tricky. The general recommendation is to have a single reference group (A – no change) against a single variant. However, if you have more potential solutions and a big enough user group, not to mention the development resources to create more variants, there is nothing here to stop you.
You can use a dedicated calculator to determine the minimum sample size. However, if you have a risky or really disturbing test to perform, you may choose to reduce the test group to limit potential fallback from a failed test.
This will be connected with the number of users you have and the minimum sample size you need to achieve. You probably need a week or two for the biggest products, but might need way longer if your test user group needs that time to grow that minimum number.
Based on your selected testing metric(s), have a dashboard ready to monitor your results from day one of the test. It would be also great to test if data is flowing to the dashboard that was created. There’s nothing more disappointing than running an A/B test and seeing no data flowing in.
Hit the “go” on your test once the code is live and see the magic happen!
When you have enough data to determine the winning variant, you can complete the test and decide what next. Whether you have a clear victor, find that all variants performed similarly, or you need more work to determine the next actions, it’s up to you to decide based on the data available.
Once you’re done, make sure to remove testing and lost variant-related code. The more dead code from past tests left in the product, the harder it is for the devs to maintain the product.
One of my favorite examples of A/B testing is the famous Pepsi Challenge. It was a real-life, blind taste test where participants were asked to taste two unmarked colas and decide which one they preferred. Despite Coke being the market leader, many participants picked Pepsi, leading to a major marketing campaign by Pepsi highlighting these results.
This experiment played a pivotal role in the Cola Wars and is a prime example of A/B testing in action.
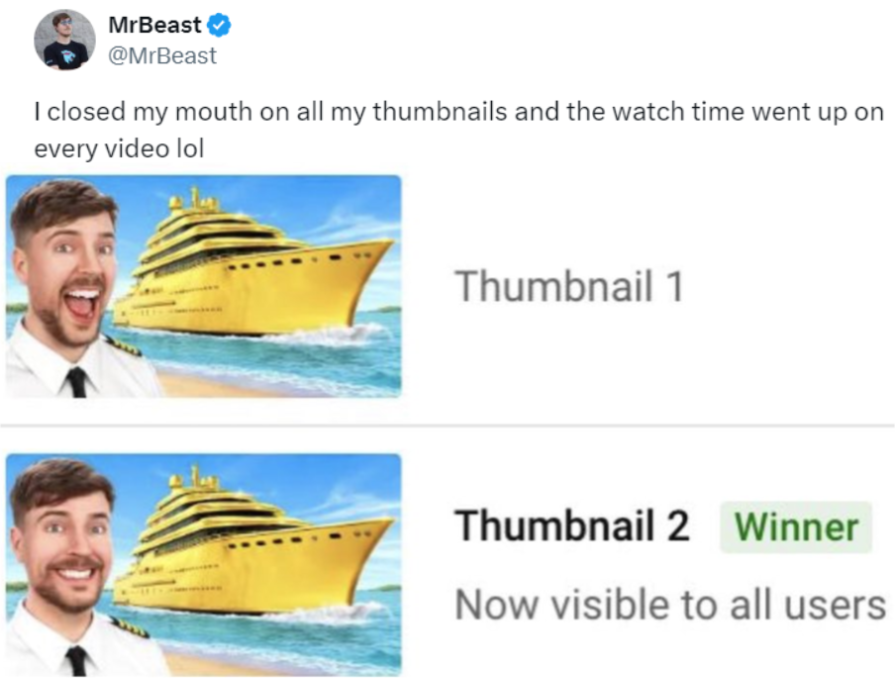
Another great example is when an A/B testing feature was enabled by YouTube. It enabled creators to test different aspects of their videos, including video thumbnails. With this, the biggest YouTuber on the platform determined that if he closed his mouth on his thumbnails, people would watch more of the videos!
While this is an unlikely connection, MrBeast has millions of subscribers and I’m pretty sure that he saw so much uptake on his watch time metric that the results were reliable and conclusive:
As I mentioned, A/B testing is an easy-to-implement tool with conclusive results. However, to get the most from your testing, take into account the following suggestions
A/B testing has its best practices, but it’s as good as the people setting it up. To this end, here are some pitfalls you want to avoid.
Don’t close the test after 2-3 days when you believe that you have the results. Let more data flow in, say from the weekend, to ensure the results that you’re observing early on are correct and relevant.
A/B test results should be applied only to an actual A/B test run. As a person who was running A/B tests of the same product updates on Android and iOS, it wasn’t uncommon to see different results on two platforms. The iOS user base is quite different from the Android one and running a single test on one of the platforms was never enough.
Both too-small and too-large sample sizes can be problematic. A small sample size may not provide reliable insights while running a test for a large cohort for too long will simply be a waste of time. Time you could spend on another test!
Unless your A/B test reaches statistical significance, the results are completely unreliable and random. Only with this status reached, will you be able to consider the test’s results as actionable.
As mentioned in the best practices section, you need to monitor a set of metrics, regardless of which are actual success criteria. If you just present the favorable changes without understanding and disclosing the potential downsides, you won’t benefit the users or the product. Failed A/B test is nothing to be ashamed of.
If you’re running different A/B tests at the same time, they can influence one another and thus leave mutual contamination. Only if the different tests happen in different, very far apart, areas of the product, can you consider parallel testing.
Consider segmenting your results to understand how different groups of users may behave differently. This can be super useful if your users behave differently in different countries. An A/B test with all countries mixed up may not give reliable results.
Sometimes, events outside the test, such as holidays or marketing campaigns, can influence the results. It’s important to account for these factors when analyzing the data. The most common case here is a product bug that affects only one of the testing groups.
Sometimes, users may respond positively to a change simply because it’s new and the impact can become irrelevant in time. A good idea here is to analyze new and existing user cohorts and see if the positive test impact is similar across the two. If there is inconsistency between the two, you might be looking at a novelty effect.
A/B testing is the most reliable and successful way to collect data to prove your product hypothesis. However, take into account that it’s not free in terms of development time and I recommend you still use common sense when issuing such an experiment.
Some updates won’t require it and it’s up to you to decide. That said, knowing when not to run an A/B test is quite a different story for another article. If you liked this piece, make sure to come back for more! Thank you.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.
PMs often misread acquisition spikes as growth. Learn which retention and activation signals show whether users actually find value.

The LogRocket MCP connects your AI agents to Galileo AI. Detect issues, diagnose root causes, and ship fixes from Claude, Cursor, Codex, or your own agent.

PMs don’t need fake authority to lead well. Learn how shared context, clearer trade-offs, and better decision-making build stronger teams.
Learn how PMs can spot novelty effects in A/B tests, validate wins over time, and avoid mistaking short-term lifts for impact.


