To reinvent the wheel means to rebuild something that has already been built before. Its connotation is frequently negative — i.e., reinventing something is pointless and a waste of time because somebody has already done it before.

In general, this is a good warning. You should be careful where you invest your time and focus. But I recently had the experience of recreating a popular technology.
I’ve essentially rebuilt GraphQL.
In this blog post, I’d like to introduce you to my new open-source project called MiniQL. We’ll also talk about why I reinvented the wheel and when it’s OK to do that.
Itching to get a look at MiniQL? Want to get a look at it and then come back to this blog post? Check out the interactive example here. You can find the code for MiniQL on GitHub.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
I’d really like to use GraphQL. I’ve used it before when working for other companies. But unfortunately, it didn’t quite fit the needs of my startup (more on that soon), so I wasn’t able to use it.
I spent a number of months wishing I could integrate GraphQL into our project. I knew it would simplify a lot of things and create a cohesive data model, but I just couldn’t make it fit.
For a while, the idea brewed that if I could just replicate some parts of GraphQL, I could get what I needed. The concept of MiniQL was forming.
GraphQL, if you haven’t heard of it yet, is a language and runtime to describe, query, and manipulate your data. It’s very popular, it’s open-source, and it was created by Facebook.
GraphQL isn’t tied to any particular database or data format, and it’s supported in many programming languages. GraphQL is awesome, and you can read more about it here.
If GraphQL is indeed so awesome, then why didn’t I just use it?
Well, there’s definitely a time and a place for GraphQL. I’ve seen it work really well in production. But it didn’t work for my startup.
The main problem was the need to create a data schema. We didn’t already have one, and I didn’t want to create one. We are a startup that is experimenting rapidly to evolve our product and find the right market fit. Using a schema during fast evolution of a product creates a lot of busywork.
A schema requires constant updates to keep it relevant — not to mention continual data migrations to bring the data up to date with the schema, plus managing separate schemas for different environments. Creating the schema in the first place (across our 20-something microservices) is a daunting job in itself.
So we said no thanks to having a schema — it works against our fast pace of development.
There are other issues as well. GraphQL adds an extra language to our mix of technologies. That means extra training for our developers and additional complexity in our stack. The time it would take to integrate and implement GraphQL would be better spent adding features for our customers.
Also, it’s a relatively small thing, but I find it really tedious that I have to specify all the fields in the data that are to be returned. I know that in GraphQL this is an optimization to minimize the data returned to the frontend. That’s great for optimization, but it’s really bad for data exploration.
Sometimes I just want to explore the data and see it all. Or maybe I just need to get something done quickly in an MVP or prototype and I want to get all the data without thinking about it. Sure, I’ll need to do the optimization later, but for now I just want the quick and easy route.
Why can’t I just have the best of both worlds? In some situations I’d like to retrieve all my data; in others, I’d like to retrieve an optimal or minimized dataset. For my startup, the barrier to entry for GraphQL turned out to be higher than the value it delivers.
Although reinventing the wheel is often seen as a pejorative, there are actually occasions where it’s a good thing.
For a start, consider this: if no one ever reinvented anything, we’d never have better things.
We’d all be stuck with the same tired old programming languages, databases, and frameworks. Reinvention is necessary for innovation and evolution — sometimes even for revolution.
But unfortunately, we can only see this in hindsight. It’s only when a reinvention is successful (bearing in mind that they are often unsuccessful) that you will be praised. Before that point, you will most certainly be criticized. Getting to success means getting past those telling you not to reinvent the wheel.
Here are some valid reasons to reinvent the wheel:
I created MiniQL because GraphQL didn’t work the way that I wanted.
Personally, I don’t think I could make something better than GraphQL; it is already very good, and bettering it would require a team and resources that we don’t have. So that wasn’t my motivation. But it is a perfectly good reason to reinvent something — because you want a better version of it.
Of course, it’s also perfectly OK to reinvent things for fun or education, and that’s a fantastic way to learn new things and gain experience as a developer.
Just be careful you don’t get so deep that you are drowning. Rebuilding sophisticated technology is no easy task. It can be very difficult, and more often than not, it’s not going to be successful.
That’s not the case for MiniQL. It’s already successful — at least for my startup. It’s doing what it was intended to do.
MiniQL is small and simple. I made it like that on purpose, and I knew that it would be achievable. Taking just the bits of GraphQL we need (customized to our particular use case) and simply discarding those parts of GraphQL that are too cumbersome or that we don’t require.
If you do find yourself too deep, please feel free to just drop your project. When coding for a hobby or for education, just stop coding as soon as you have had your fun or learned something useful.
Starting a project, discovering it is very difficult, and then dropping it is perfectly OK. Just make sure you get something in return, be it fun, learning, something for your portfolio, or some other outcome.
But please don’t go and unnecessarily reinvent things on work time! If you are going to do this at work, you better have a good reason and the support of your manager — otherwise, things will get awkward.
MiniQL (as it became known) has been brewing in my mind for most of 2020. I knew I needed some way to simplify the data management and retrieval for my startup. Then one weekend, I sat down and started coding.
MiniQL was born in a single weekend. It is developed in TypeScript for use in both JavaScript and TypeScript. I had a good idea of how it was going to work (after thinking about it for months and taking copious notes). I had a priority to keep it small and manageable. I used test-driven development (TDD) from the start.
MiniQL needed another weekend to flesh out the feature set and stabilize the core logic. The core query engine was completed fairly quickly, and since then, it has proceeded intermittently as I worked on plugins, examples, and documentation. It’s interesting to note that I have now spent way more time on examples and documentation than I did on the core query engine.
The code is quite abstract, although it was straightforward to develop through iterations of TDD. At each stage, I added features or refactored, but at no time did I let any bugs enter the picture. That’s how TDD works: it adds a scaffolding to your project that supports and protects you while you are coding.
TDD really supported the abstract nature of the code, which makes it difficult to read. The abstract code also makes it difficult to explain, hence the work on examples and documentation.
You can find the MiniQL query engine on GitHub. For a quick, interactive overview of MiniQL, see the interactive example here.
If you are new to development and you want to see an example of how TDD plays out, this is a great project for that. You could time-travel and replay the history of this project commit-by-commit to see how it builds up over time (in fact, I made a time-lapse video of the first few hours of development).
Feel free to work through it by getting each commit in turn and running the tests to see what tests were added and how they exercise the code. This is a great way to get a feeling for the iteration-by-iteration nature of test-driven development.
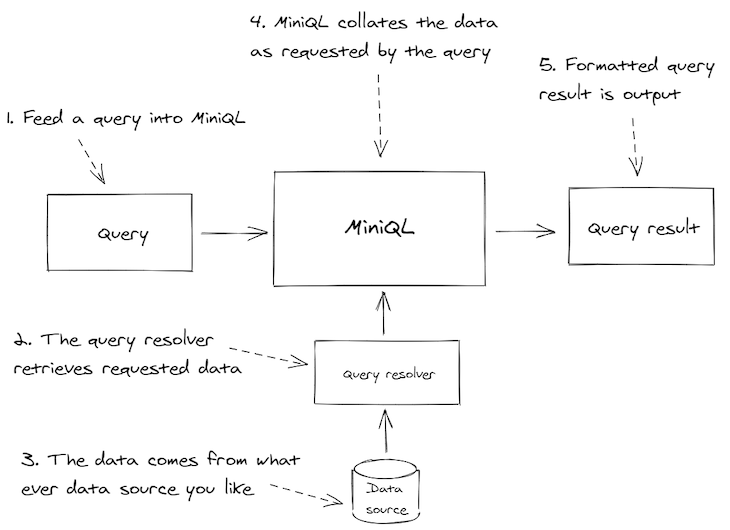
Figure 1 below succinctly describes MiniQL.
We execute JSON queries against MiniQL (1). A user-defined query resolver is responsible for retrieving data from whatever database or data source we are using (2). The resolver is an implementation of the adapter pattern — it adapts our chosen data source to work with MiniQL.
MiniQL then organizes the retrieved data as requested by the query (4) and returns a formatted JSON document containing the requested data (5).
MiniQL aims to be tiny, yet very flexible.
Primarily, we want to be able to easily create and execute queries. It must be possible to send queries and receive results across the network. That’s why both queries and results are expressed in the JSON format.
JSON is already common in many tech stacks, so this means we aren’t introducing any new language. It also means that both queries and results are easily serializable, which is great if you need to implement caching.
It must also be easy to implement a query resolver for MiniQL. We’d like to be able to easily plug in any custom database or data format that we’d like to execute queries against. In fact, MiniQL already has a bunch of pre-built resolvers implemented, with more coming soon (see the GitHub page for links to examples). But it isn’t difficult to create your own query resolver.
MiniQL delegates features to the query resolver. Delegating features to the resolver also means we can take advantage of any special features that are offered by our particular database.
One of the primary drivers for MiniQL was the need to simplify the REST API in my startup’s product. Instead of having hundreds of endpoints in the REST API, I wanted to have only a few.
MiniQL allows many types of queries and update operations to be routed through a single endpoint. This means we can greatly reduce the number of endpoints needed by our application. It also makes our code simpler and gives us a single place to apply authentication and other security measures.
We’d also like to be able to retrieve optimized or minimal data to the frontend (just like GraphQL), but in addition, it makes sense to be able to just retrieve all the data whenever we need that capability. Getting all the data is good for exploring our data or for those times when we don’t need or don’t want to optimize the results (say, when we are prototyping an MVP).
And finally, but very importantly, MiniQL does not impose unnecessary structure or rules on our data. MiniQL doesn’t have any built-in concept of a schema.
Of course, that doesn’t mean we can’t make our own rules or structure. Personally, I like to use TypeScript to impose a system of static typing on my data. If you’d like to layer a schema on top of MiniQL, you can easily use JSON schema. You can see an example of that in the query editor of the interactive example.
At its core, MiniQL is about retrieving and updating entities in our data store. We can retrieve a single entity, all entities, or search for a set of entities. We can resolve nested entities as well. Through simple combinations, we get a lot of flexibility in how our query results are structured. In this blog post, I only show how to retrieve entities from our data source. In a future blog post, I’ll show how to update entities.
Let’s look at some simple examples to retrieve entities from a Star Wars universe dataset (thanks to Kaggle for the data).
The query in Listing 1 shows how to retrieve the record for a single entity: Darth Vader.
MiniQL queries are written in JSON, but for these examples (as well as in the interactive example), I’m demonstrating using JSON5, which is a more human-oriented version of JSON that supports comments.
Note how we use the args field to set the name of the entity to be retrieved. The meaning of args is entirely up to the query resolver. So what you need to pass in here really depends on the resolver. In this case, we look up the record based on the name column in a CSV file, and that’s why we set the name field in the query to "Darth Vader".
{
"get": {
"character": { // Gets the character entity.
"args": {
"name": "Darth Vader" // Gets Darth Vader by name.
}
}
}
}
{
"character": {
"name": "Darth Vader", // Got Darth Vader.
"height": 202,
"mass": 136,
"hair_color": "none",
"skin_color": "white",
"eye_color": "yellow",
"birth_year": "41.9BBY",
"gender": "male",
"homeworld": "Tatooine",
"species": "Human"
}
}
The query in Listing 2 shows how to get all characters from the Star Wars universe. Note that we have left the args field empty. Not specifying arguments to match any particular character indicates to the query resolver that we’d like to get all characters instead of a particular character.
{
"get": {
"character": { // Gets the character entity.
"args": {
// No args, gets all characters.
}
}
}
}
{
"character": [ // Got all Star Wars characters.
{
"name": "Luke Skywalker",
"height": 172,
"mass": 77,
"hair_color": "blond",
"skin_color": "fair",
"eye_color": "blue",
"birth_year": "19BBY",
"gender": "male",
"homeworld": "Tatooine",
"species": "Human"
},
{
"name": "C-3PO",
"height": 167,
"mass": 75,
"hair_color": "NA",
"skin_color": "gold",
"eye_color": "yellow",
"birth_year": "112BBY",
"gender": "NA",
"homeworld": "Tatooine",
"species": "Droid"
},
// ... and so on
]
}
MiniQL supports retrieving related entities and nesting the result in the output.
The query in Listing 3 shows how to get the character Darth Vader and also retrieves details of his homeworld as a nested entity. Notice how the resolve field is used to specify that we’d like to also resolve details of Vader’s homeworld.
{
"get": {
"character": {
"args": {
"name": "Darth Vader" // Gets Darth Vader.
},
"resolve": {
"homeworld": { // Gets Darth Vader's homeworld.
}
}
}
}
}
{
"character": {
"name": "Darth Vader", // Got Darth Vader.
"height": 202,
"mass": 136,
"hair_color": "none",
"skin_color": "white",
"eye_color": "yellow",
"birth_year": "41.9BBY",
"gender": "male",
"homeworld": { // Got Darth Vader's homeworld.
"name": "Tatooine",
"rotation_period": 23,
"orbital_period": 304,
"diameter": 10465,
"climate": "arid",
"gravity": "1 standard",
"terrain": "desert",
"surface_water": 1,
"population": 200000
},
"species": "Human"
}
}
Now that we can make some basic queries, it’s time to learn how to create a query resolver. There are various MiniQL plugins that implement query resolvers for some types of data sources, but true to its goals, it’s quite easy to create one for yourself with MiniQL.
The examples below are based on using MongoDB as the data source, but for your implementation, you can use any other database or data format you prefer.
The query resolver in Listing 4 shows a simple resolver for the character entity used in the previous example. Note how the one resolver is used to get either a single character or all characters depending on whether a name field was provided in the query arguments.
The entire arguments object is passed directly through the resolver, so our resolver here actually has access to any arguments that are passed through from the query. This provides a way to pass custom arguments through to the resolver that can be used in any way you could imagine.
As you can see, query resolvers are async-enabled. The invoke function is async to allow for asynchronous data retrieval from databases, files, REST APIs, or wherever else you might like to get your data from.
const characterCollection = // ... A MongoDB collection.
const queryResolver = {
get: { // Resolver for "get" operations.
character: { // Resolver for the character entity.
invoke: async (args, context) => { // Function to get characters.
if (args.name !== undefined) {
// Gets a single character.
const character = await characterCollection.findOne({ name: name });
return character;
}
else {
// Gets all characters.
const characters = await characterCollection.find().toArray()
return characters;
}
},
},
},
};
We can easily support multiple entity types by adding more fields to our query resolver. You can see in Listing 5 that we have added a new species entity to our resolver.
const queryResolver = {
get: {
character: { // Resolver for the character entity.
invoke: async (args, context) => {
// ... Gets Star Wars characters.
},
},
species: { // Resolver for the species entity.
invoke: async (args, context) => {
// ... Gets Star Wars species.
},
},
},
};
We can support entities by placing them under the nested field in the parent entity. For example, in Listing 6, we have nested the homeworld entity resolver under the character entity resolver.
const queryResolver = {
get: {
character: {
invoke: async (args, context) => {
// ... Gets Star Wars characters.
},
nested: {
homeworld: { // Gets the homeworld for the character.
invoke: async (args, context) => {
// ... Gets a Star Wars planet.
},
},
},
},
};
MiniQL delegates all details about entity retrieval to the query resolver. Anything that is supplied in the args field of an entity query is passed through to the resolver. This means you can implement any query features you, like such as text-based search for entities or exposing special features of your particular database.
As an example, Listing 7 shows how we can implement pagination in our query resolver. Note how this code expects skip and limit fields to be supplied through the query arguments. MiniQL doesn’t know or care about these particular fields; they only have relevance to how we implement our query resolver.
In this example, the values for skip and limit are passed to the MongoDB driver to paginate the set of all characters.
const queryResolver = {
get: {
character: {
invoke: async (args, context) => {
if (args.name !== undefined) {
// Gets a single character.
const character = await characterCollection.findOne({ name: name });
return character;
}
else {
// Gets all characters.
const characters = await characterCollection.find()
.skip(args.skip) // Skips a number of records.
.limit(args.limit) // Limits the number of records returned.
.toArray()
return characters;
}
},
},
},
};
MiniQL is a tiny, but powerful, JSON-based query language inspired by GraphQL. It aims to replicate the parts of GraphQL that I can’t do without and discards the parts that I find to be extraneous, tedious, or unnecessary.
MiniQL is implemented in TypeScript for use in JavaScript or TypeScript, but there’s no reason it can’t also be implemented for other programming languages. The inputs and outputs to MiniQL are JSON, so the MiniQL query language is essentially programming language-agnostic.
If you’d like to make an implementation for a different language, please send me a DM on Twitter to let me know.
Love the idea of MiniQL? Please put a star on the repo and follow me for updates.
Reinventing the wheel is often considered a bad thing. But it can be useful and is sometimes necessary for progress. We might also do it just for fun or education, but be aware of the reasons why you are doing it and the value you are getting from it. If a “reinvention” project becomes too difficult, don’t be afraid to just drop it. If you had some fun or you learned something, that’s a good outcome — even if you didn’t finish it.
Actually completing projects is hard work. To stand the best chance of completing a project, keep your focus narrow. That will give you the best chance of finishing it.
If you are reinventing something for fun or education, just don’t do it on work time! I don’t want you to get you into any trouble at work. If you have to reinvent something for work, make sure your manager is on board with it before you start.
Before reinventing any technology please consider the following…
| Consideration | Should I reinvent X? |
| X almost does what I want and it is open-source. | No, it’s better to contribute to X.
Fork your own copy and change it to do what you want. Submit a pull request to have your changes integrated into X. |
| I like some of the ideas in X but not others. | Maybe — consider reinventing a smaller version of X that does only the things that you need. |
| I think I can build a better X. | Maybe, but even though you can conceive of this, you might find it very difficult to achieve, especially if X is a technology created by a team of developers.
It’s going to be very difficult for a solo developer to compete with that. |
| I can learn by building a new X. | Yes, but only to a point.
Reinventing things is a great way to learn and gain experience as a developer. Work on it while you have motivation and while you are learning. Once the learning runs out and it just feels like hard work, feel free to drop it. |
| I think it would be fun to rebuild X. | Yes, but only to a point.
Coding is fun, and reinventing things can be enjoyable. Just don’t become obsessed with it. Be mindful of how you feel about the project. As soon as it’s no longer fun, drop it. |

LogRocket lets you replay user sessions, eliminating guesswork by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks, and with plugins to log additional context from Redux, Vuex, and @ngrx/store.
With Galileo AI, you can instantly identify and explain user struggles with automated monitoring of your entire product experience.
Modernize how you understand your web and mobile apps — start monitoring for free.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 25th issue.

Discover a practical framework for redesigning your senior developer hiring process to screen for real diagnostic skill.

I tested the Speculation Rules API in a real project to see if it actually improves navigation speed. Here’s what worked, what didn’t, and where it’s worth using.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

