Dgraph is a horizontally scalable, fast, highly-available, and distributed graph database providing ACID transactions, consistent replication, and linearizable reads.
It also supports a GraphQL-like query syntax, which is very useful for having more fine-grained searching features.
Graph databases, in turn, are databases that use graph structures (like nodes and edges) to represent entity relations and store data.
GraphQL, as the name suggests, is also a technology based on the graph’s area. So, why not mix both?
As you may know, GraphQL is an alternative and robust way to expose API endpoints rather than the usual REST.
It is flexible, language-agnostic, powerful, and very well-accepted by the community. But that doesn’t mean you have to write your data storing logic within a graph database.
This article aims to touch this subject in a practical way.
We’ll create a CRUD with Dgraph that, in turn, will generate scaffolded methods for each one of the queries and mutations. Then, by the use of the GraphQL Playground, we’ll test them out.
The quickest way to get Dgraph up and running is via Docker. You can also download it via curl and add it to the bash following these instructions.
However, for the sake of simplicity, we’ll stick to the Docker strategy.
First, install Docker if you still don’t have it.
Then, let’s run the following command, which pulls the latest Dgraph Docker image:
docker pull dgraph/dgraph:latest
If you want, you can also install a specific version rather than the latest version.
After it’s finished, you can run the following command to check the downloaded images:
docker images
Finally, let’s get the Dgraph up and running:
docker run -it -p 8080:8080 dgraph/dgraph:latest
This will start our application in the localhost at port 8080. You can change the port as you wish to.
Make sure to wait until the message “Listening on ...” appears to certify that it’s up.
This is it. The setup is pretty simple and the next step is to provide the schema to our Dgraph database.
Now, let’s analyze how our schema will look:
type Post {
id: ID!
title: String! @search(by: [exact])
content: String!
authors: [User]
comments: [Comment]
}
type User {
id: ID!
username: String! @search(by: [exact])
name: String! @search(by: [fulltext])
avatar_url: Url
}
type Comment {
id: ID!
description: String!
likes: Int
}
type Url {
url_address: String!
}
Our example will be a blog post’s schema. We’ll create a CRUD over blog users, posts, and comments.
If you’re not familiar with GraphQL schemas, I’d recommend a read over this.
When creating your schema, it’s important to think of it as you’d think of your database tables. Each type corresponds to a table that, in turn, should have an id (auto generated). In our example, the Url type doesn’t have an id, so it means we’ll have to explicitly insert the urls into the users.
The rest of the fields follow the convention. You have a type, and the ! defines if it’s required or not.
Special attention here for the @search directive.
It tells Dgraph that our model needs to be able to search for the specific attribute value.
The exact value states a search to be done over the exact string provided as param, and the fulltext value enables two other options that we’ll see in action further.
You still have the option regexp, which allows the filtering through regex.
You can read more about this here.
Now, let’s run the command that will create all of our database structures based on the seen schema:
curl -H "Content-Type: application/json" http://localhost:8080/admin/schema -XPOST -d $'
type Post {
id: ID!
title: String! @search(by: [exact])
content: String!
authors: [User]
comments: [Comment]
}
type User {
id: ID!
username: String! @search(by: [exact])
name: String! @search(by: [fulltext])
avatar_url: Url
}
type Comment {
id: ID!
description: String!
likes: Int
}
type Url {
url_address: String!
}'
After the command has finished successfully, you should see the following output message:
{"data":{"code":"Success","message":"Done"}}
Now’s time to test our example and feed the database blog data.
First, you need to download and install the GraphQL Playground tool to your computer.
Obviously, you can use whichever tool suits you best, but we’ll stick to the Playground because it is simple and automatically refreshes the GraphQL schema when you change it on the server.
Now, open it and type the http://localhost:8080/graphql in the address bar.
Click the “SCHEMA” button at the right side of the window and the following content will appear:
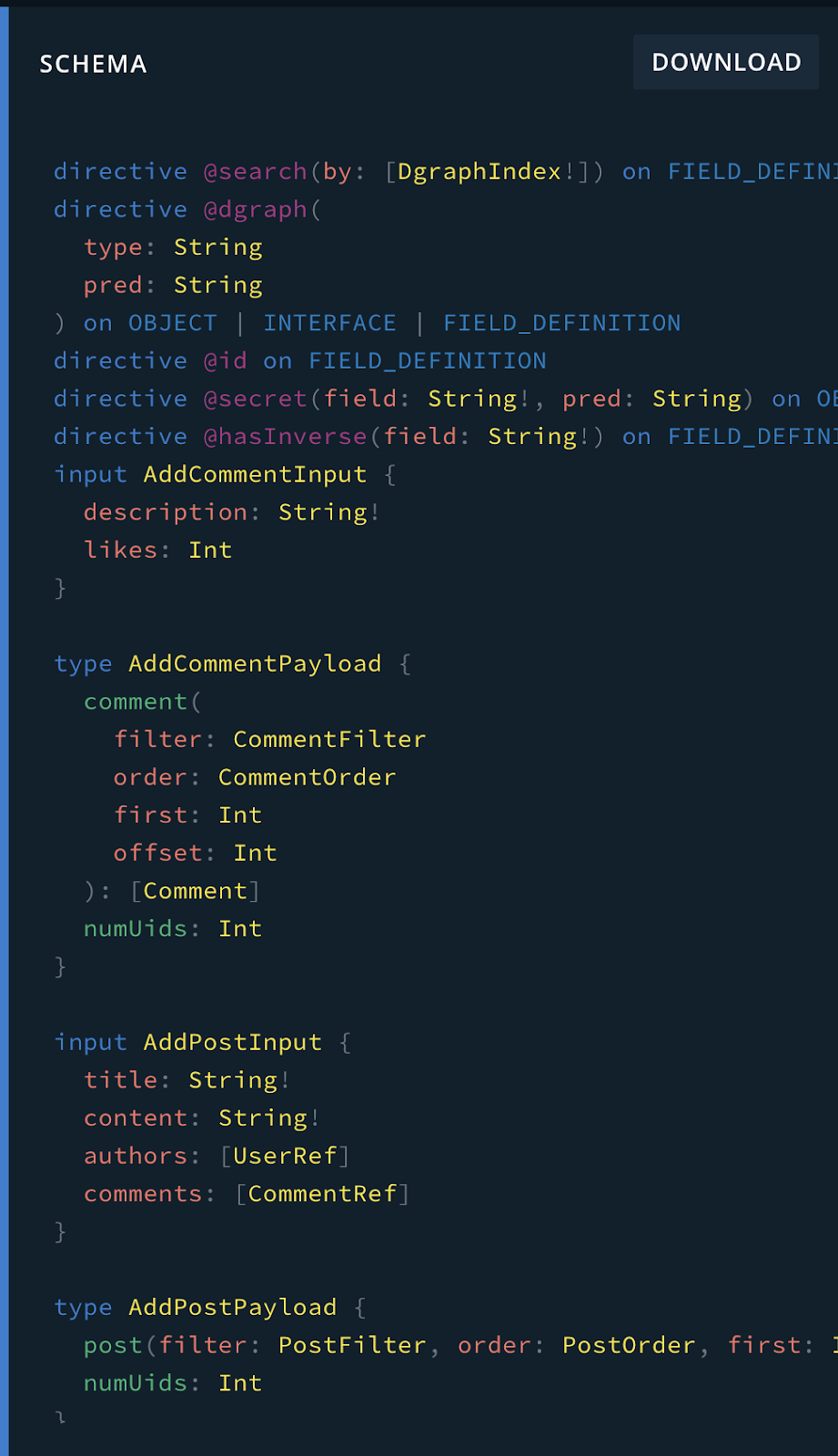
As you may notice, the initial schema we’ve provided to the Dgraph command is not the final one. Actually, Dgraph will take that as the default basis to generate the CRUD schema operations over each one of the established relationships.
The more complex the schema and its relationships are, the more complex the final generated GraphQL schema will be.
Dgraph follows the pattern of Add (to create new items), Update (to update existing items), Remove (to remove), and Get (to retrieve and filter) as prefixes coming in the beginning of the operation names.
Let’s start testing with a simple mutation that creates a new comment. This is the content:
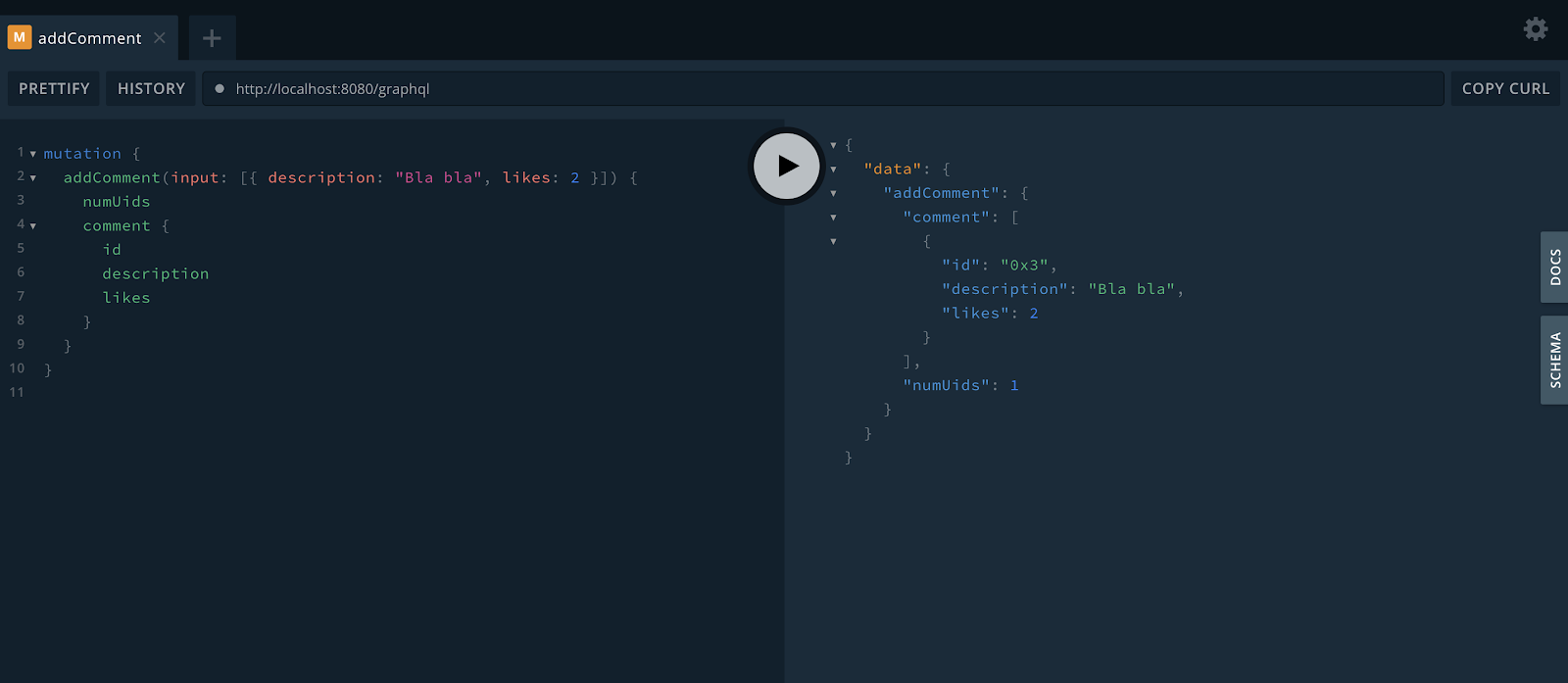
In order to make calls in this API, you must follow the type system determined by Dgraph — the one that was auto-generated and that we’ve seen before.
Each mutation receives one argument, the input. It is basically an array of entries that change depending on the type of operation you’re performing. For example, in order to create a new comment, you must provide a description and the number of likes.
Note, also, that right after we’re placing the result fields we want to be returned. This is obligatory.
On the right side, finally, you get to see the result, including the auto-generated id value. This value is important because it’s the one you must use when getting a comment. For example:
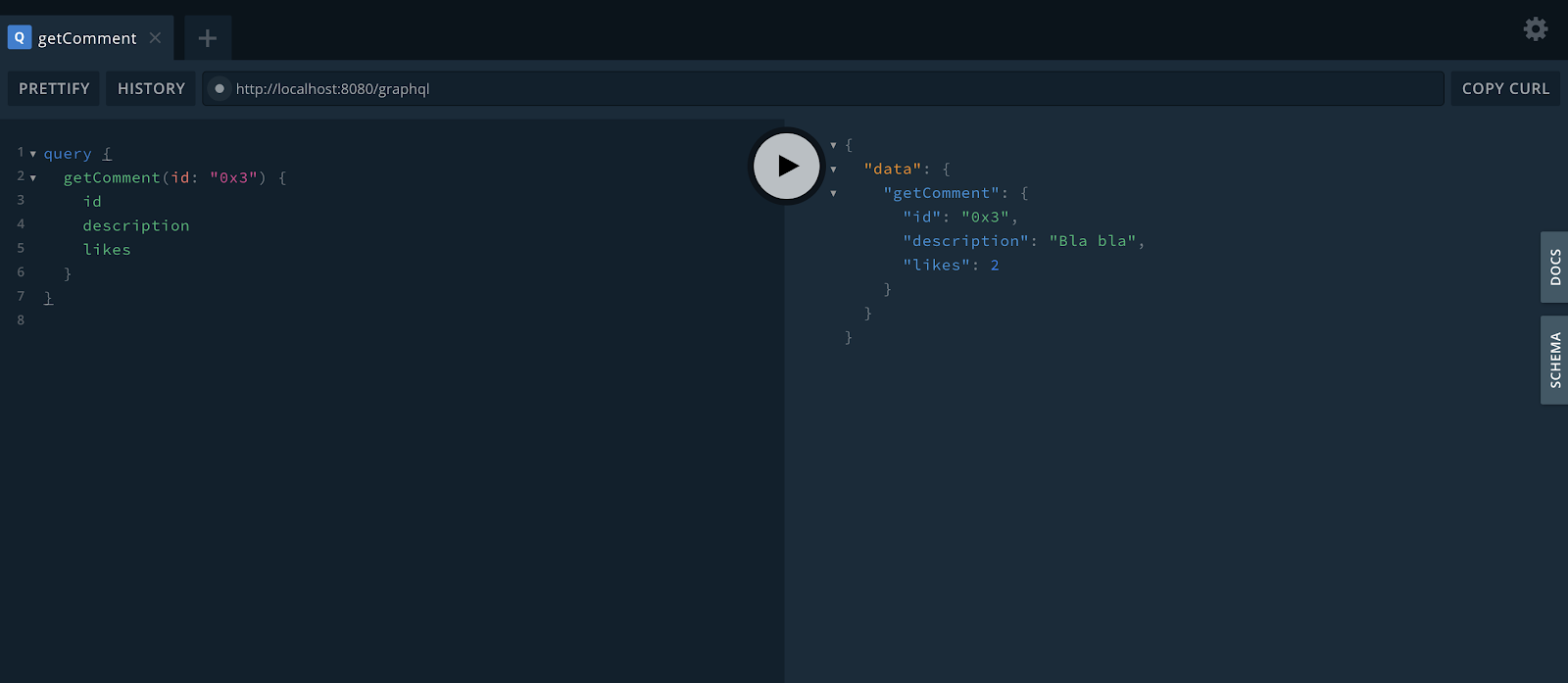
Let’s now create a new user. This is the mutation content for it:
mutation {
addUser(
input: [
{
username: "logrocket"
name: "LogRocket"
avatar_url: {
url_address: "https://blog.logrocket.com/wp-content/uploads/2020/01/logrocket-blog-logo.png"
}
}
]
) {
user {
id
username
name
avatar_url {
url_address
}
}
numUids
}
}
Note that we should explicitly place the avatar url content as a whole type. If you have many objects inside one another, they must be stated here as well.
This is the output:
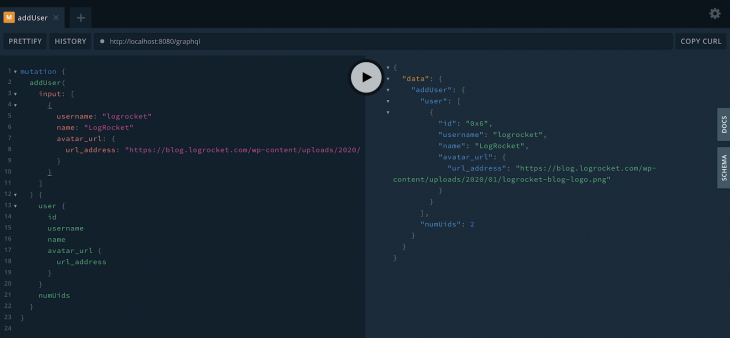
Querying for a created user is very similar to the comments. Playground actually helps a lot by autocompleting the available options for both mutations and queries.
This is a query example for the recently-created user:
query {
getUser(id: "0x6") {
id
username
name
avatar_url {
url_address
}
}
}
Now, let’s explore the filter feature.
As we mentioned, it allows us to query for specific statements, or text snippets. For example, imagine that you have a bunch of users already registered and you want to search for all the users with the username “logrocket”.
This would be your query:
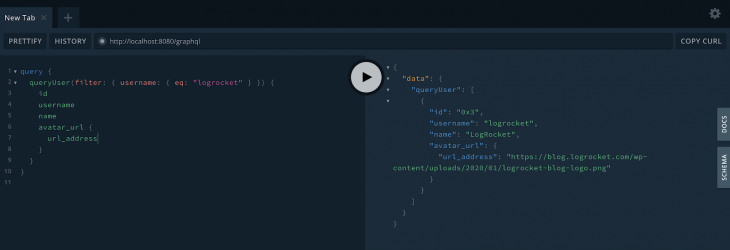
query {
queryUser(filter: { username: { eq : "logrocket" } }) {
id
username
name
avatar_url {
url_address
}
}
}
The eq operator stands for equals to. Remember that it is only possible because we’ve defined in our schema that the username field is searchable (@search(by: [exact])).
The name field, in the other way, was created as a searchable field, but with the option fulltext. That option provides us with two searching operators: alloftext (contains all of that) and anyoftext (contains at least one of that).
Take a look at a query with the first option:
query {
queryUser(filter: { name: { alloftext: "Login" } }) {
id
username
name
avatar_url {
url_address
}
}
}
This is going to be the result:
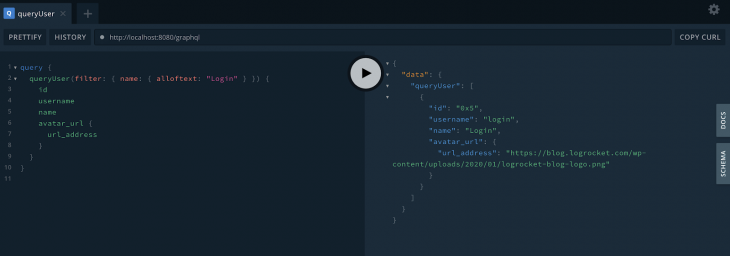
When it comes to the second option, here’s what we get:
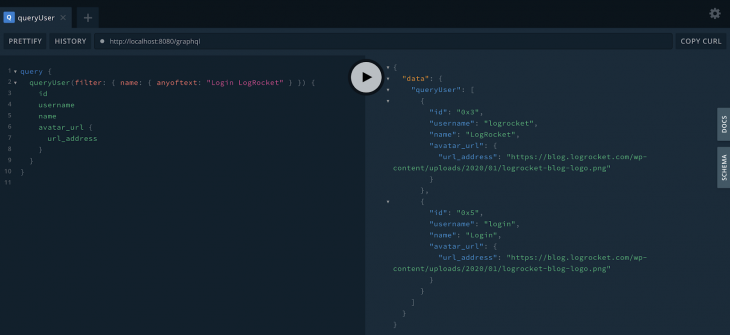
Now we have an array with two elements as a result. Dgraph will search for any content that matches at least one of the string arguments.
Another possible query would be the following:
query {
queryPost(
filter: { title: { eq: "bla" } }
order: { asc: content }
first: 2
) {
id
title
content
comments {
description
likes
}
}
}
After inserting some posts, you could query for all the posts with the title “bla”, ordered by their content and having the first two found items as a result.
These are just a few examples of the power of Dgraph aligned with GraphQL. Its scaffolding nature helps a lot to build a CRUD from scratch and have it up and running in no time.
Dgraph provides us with other interesting features, like authorization and authentication directives, custom resolvers, custom fields and more.
Make sure to refer to their official docs for more.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
This guide explores how to use Anthropic’s Claude 4 models, including Opus 4 and Sonnet 4, to build AI-powered applications.

Which AI frontend dev tool reigns supreme in July 2025? Check out our power rankings and use our interactive comparison tool to find out.

Learn how OpenAPI can automate API client generation to save time, reduce bugs, and streamline how your frontend app talks to backend APIs.

Discover how the Interface Segregation Principle (ISP) keeps your code lean, modular, and maintainable using real-world analogies and practical examples.


