A new version of the GraphQL specification has been released: the October 2021 Edition. This new release comes over three years after the previous one (from June 2018) and involved 35 contributors who produced nearly 100 changes.

You might think that, coming after three years of work, there will be major new features in the spec. Checking the changelog, though, we can see that most of the changes are simple improvements, and only a handful of them are actually new features. You may then wonder, if only a few of them are new features, why did this new release take over three years to produce?
In this article, we will address this question, pore over the newly-added features, and see which exciting new features did not make it to the new version.
Producing a new release of the GraphQL spec basically amounts to tagging the GitHub repo graphql/graphql-spec. Why did the maintainers take over three years to do it?
GraphQL Java creator and spec contributor Andi Marek gives us an answer, by stating that the GraphQL spec releases are not important. As he explains, in addition to the official release, the GraphQL spec also publishes a Working Draft pre-release, which is more routinely and continuously updated:
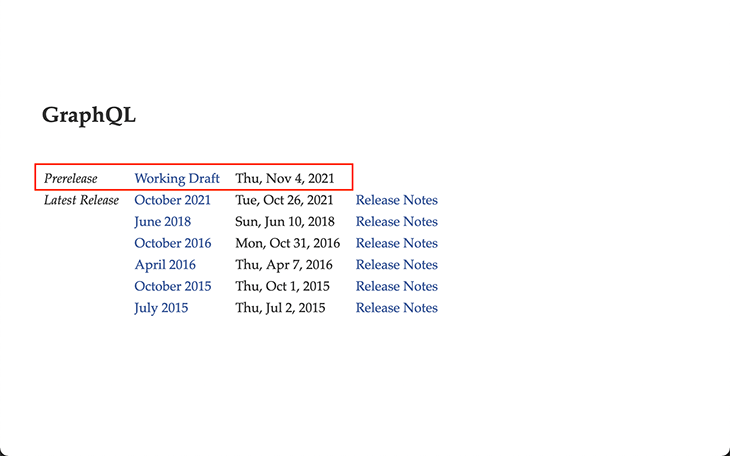
Hence, GraphQL servers, clients and tools can directly adhere to the spec from the ongoing working draft, and not need to wait over three years to incorporate new features.
Additions to the GraphQL spec must satisfy the guiding principles:
All changes incorporated to the main branch of graphql/graphql-spec will have already undergone a strict and rigorous process, which is why the working draft serves as a reliable interim reference. This process requires a champion to drive the PR through four stages before it can be merged:

During stage 0, the goal is to reject the proposal (e.g., because it produces undesired side-effects, it adds complexity, the issue can be solved with another proposal, or another reason), as early as possible.
If it is not rejected, the proposal then moves to stage 1, which indicates that the Working Group, who steer the development of the spec, acknowledges that the issue needs to be addressed, and one or more possible solutions are offered and debated by the community. Since the GraphQL spec is open source, anyone can contribute, for both proposals and solutions.
In stage 2, the list of solutions is narrowed down to a specific one that must be successfully implemented for graphql-js, (the reference GraphQL server implementation).
It ends on stage 3 “Accepted”, in which the solution is deemed complete and added to the spec.
To find out more about the GraphQL RFC process, in addition to GraphQL’s contributing guide, I recommend watching these talks:
Let’s explore the new features added to the latest GraphQL spec.
This feature enables us to unambiguously identify the behavior of a custom scalar via a new directive, @specifiedBy, which points to a document holding data-format, serialization, and coercion rules for the scalar.
For instance, we can declare that a scalar type DateTime is based on RFC3339 like this:
scalar DateTime @specifiedBy(url: "https://tools.ietf.org/html/rfc3339")
We can now declare that a GraphQL interface itself implements another interface:
interface Node {
id: ID!
}
interface Resource implements Node {
id: ID!
url: String
}
interface Image implements Resource & Node {
id: ID!
url: String
thumbnail: String
}
Notice that the interface must still define the fields from its implemented interfaces. That’s why the field id is in all three interfaces — Node, Resource and Image — and url is in both Resource and Image.
In addition, Image transitively implements interface Node via Resource, and it also needs to explicitly declare it — that’s why it implements Resource & Node.
A directive can now be added more than once, if declared using the repeatable keyword:
directive @delegateField(name: String!) repeatable on OBJECT | INTERFACE
type Book
@delegateField(name: "pageCount")
@delegateField(name: "author")
{
id: ID!
}
This new feature makes it evident that the order in which directives are applied is important. For instance, applying the directive @appendContent twice will produce different results depending on the order in which the content argument is provided:
directive @appendContent(content: String!) repeatable on FIELD
query {
post(id:1) {
# Result: "Hello world! - By Leo - leoloso.com"
title1: title
@appendContent(content: " - By Leo")
@appendContent(content: " - leoloso.com")
# Result: "Hello world! - leoloso.com - By Leo"
title2: title
@appendContent(content: " - leoloso.com")
@appendContent(content: " - By Leo")
}
}
Declaring that the directive order matters has also been added to the spec.
Basically, any of the open pull requests in graphql/graphql-spec are still a work in progress:
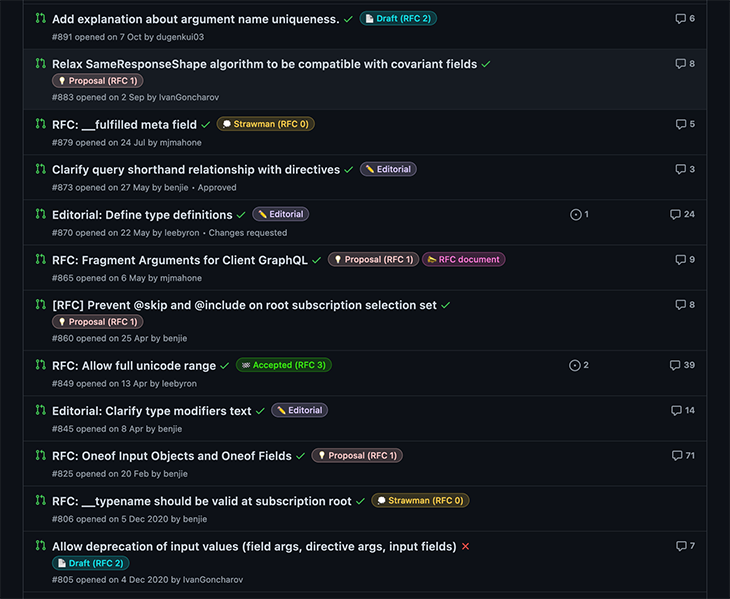
Some of these features are quite important for the future of GraphQL, and yet it may take several years before they are added to the spec.
One example is the inclusion of a polymorphic input union type, which would enable to provide values of different types to the same field. This feature would help support the union of scalar types for inputs (which was first raised over five years ago already), and show a way to do the same for outputs.
Why is it taking so long? The answer is that the contributors are making sure that the accepted solution, whichever that is, is the best solution available. Given how big GraphQL has become, and how many stakeholders there are, this is not an easy task.
Reading the RFC on the GraphQL Input Union by the working group puts in evidence the scope of the challenge, and the attention to detail by the contributors. This proposal has seen several iterations on what’s the best way to deal with it, each one of them superseding the previous one:
After exhaustive research by contributors, and consultation within the working group, it seems that the oneof input objects and oneof fields will be the chosen solution. As such, this feature will (or should) soon be merged into the GraphQL spec.
Even though the process may take a long time, such detailed research and due diligence means that no shortcuts are taken, giving us peace of mind for the long-term. Whenever the new proposal is finally accepted for the spec, we most likely won’t come to regret its employed solution over an alternative one.
Among the open PRs, there are also several others that, once approved, will have a significant impact in GraphQL:
@defer and @stream directives (#742) will improve performance when fetching dataI’m very eager to see these PRs completed!
In this article, we reviewed what important contributions were added to the latest release for October 2021, and explored what exciting new features are coming next.
The release cycle of new GraphQL specs is slow, which is why the latest version took over three years to be released. This is intentional: GraphQL is already well-established and used by an untold number of stakeholders, so new features cannot be added without great consideration. The current process makes sure every new feature is indeed needed and does not create incompatibilities with previous versions, among the other guiding principles we listed above.
However, this does not represent a problem because the GraphQL ecosystem can keep a steady pace of development by relying on the latest working draft, which is being continuously updated with the latest features.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

