Modern web applications are increasingly using “blocks,” which are high-level JavaScript components with a definitive purpose or functionality. We encounter blocks when using Notion, where every piece of content we add to the page (whether it is an image, a text paragraph, a quotation, a list, a table, or anything else) is a block:

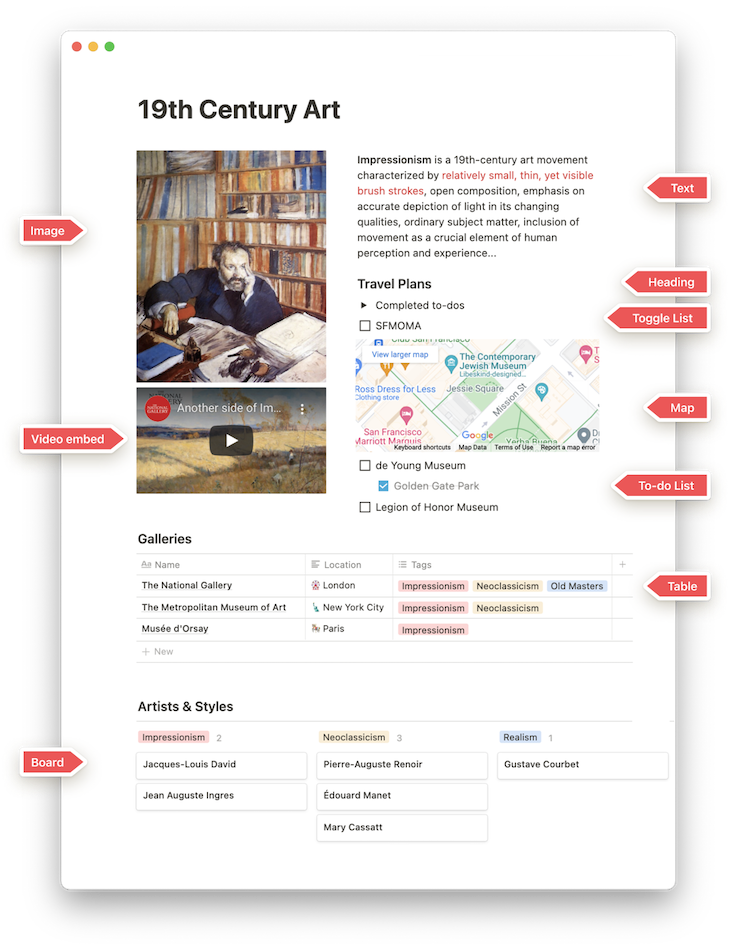
In these applications, the resulting page is a combination of blocks in a particular order, a certain configuration for each of the blocks, and user-specific data injected to the block.
As blocks gradually become the backbone of these applications, a new consideration arises: Would it be possible to grab a block that was coded for one app, and also use it in another app?
The obvious answer is “no” because blocks are most likely opinionated towards the specific applications they were coded for. Block customization concerns include things like styling, data sources, APIs to interact with underlying engines, configuration, and user permissions, among others.
For instance, if the block needs to fetch data from some source, it will possibly do it from a REST endpoint that has a certain shape, or a GraphQL endpoint that has a specific schema, and these endpoints are the ones exposed by the application; embedding the same block on a different application without compatible REST endpoints or GraphQL schema will not work.
But even though the natural answer is “no,” that doesn’t mean it cannot be done.
Instead of having the block fetch data from an endpoint all by itself, the application can also inject data into the block via props. By doing so everywhere (i.e., for all customization areas, including for styling, configuration, APIs, data sources, user permissions, etc.), the block could be made reusable across applications.
In other words, we can make blocks be interoperable across applications by building them in such a way that all data they need is provided by the application, and all functionality they can access from the underlying engine is similarly injected into them by the application.
The block and the application need to communicate with each other — the block to express its needs, and the application to satisfy them — so they must speak a common language. If this language is standardized, then the blocks and applications written by different people within the community may also communicate with each other, which would allow us to easily embed third-party blocks into our apps.
It is to attain this goal that a new open source project has been recently launched: the Block Protocol, an
open standard for building and using data-driven blocks, allowing developers to embed any block anywhere on the web, using data from any source, providing a set of guidelines on how to write blocks that render, create, update, and delete data in a predictable way, as to make it possible to easily move both blocks and data between applications that adhere to the protocol.
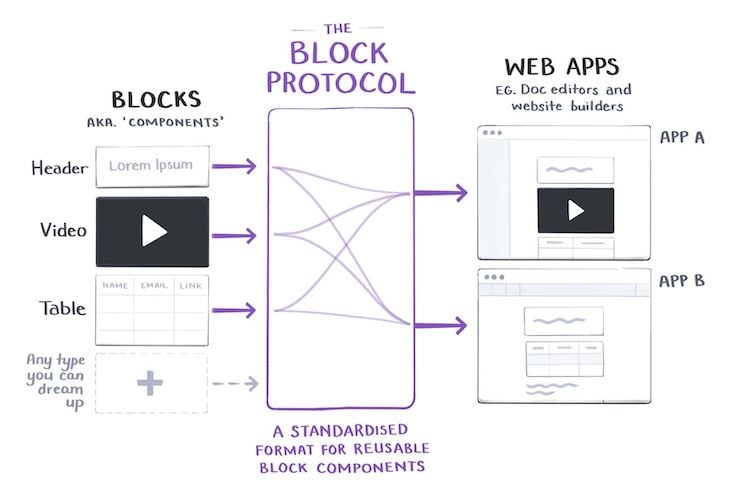
Let’s analyze this new protocol, pore over its stated goals and perceived drawbacks, reviewing the state of its current development, and assessing if it is in good enough shape for the community to benefit from it already. Here’s what we’ll cover:
These are the main benefits of having our blocks and applications comply with the Block Protocol.
This is the most evident benefit, and the main reason why the Block Protocol was created: being able to grab a block we have coded for some application, and use it in a different application in a plug-and-play fashion — with no extra configuration required — has clear implications for developer experience.
As the specification is standardized, every compliant block will work on any compliant application, independently of its author. This means that a marketplace of blocks could rise up, allowing us to easily embed third-party blocks within our applications, thus reducing the time and effort needed to develop them.
A familiar precedent for an open source specification engendering far-reaching effects already exists, thanks to GraphQL.
After Facebook (now called Meta) released GraphQL, it was immediately adopted by the community. Plenty of tooling has been subsequently created, involving areas such as schema browsing and visualization, static documentation generation, static code generation, schema stitching, telemetry, and others.
This must not be taken for granted (and it may indeed never happen), but we can hope that a similar situation could happen with the Block Protocol, spawning an ecosystem of tooling that any compliant block or application can immediately benefit from.
In order to get started with the Block Protocol, we must first read the specification, and then follow these steps:
Let’s explore these in more detail.
While the Block Protocol is technology-agnostic, the safest bet is to use React and TypeScript to develop our blocks, since this is the stack employed for all existing blocks in the Hub. As such, we have some reassurance that it works, and we can also easily explore the source code of existing blocks to learn from them (such as the Code block).
There is the intention of adding examples of blocks using other stacks:
We will be releasing examples of how to write blocks using different web technologies and frontend libraries in the near future.
However, how long “the near future” will be is not clear: it could be a month, three months, a year or even more. As this statement is a wish and not a plan — and, as the project is open source, which means that it is dependent on not-always-predictable involvement from the community — I’d recommend sticking to what we know already works: React and TypeScript.
The project includes a package to easily scaffold a new block (based on React/TypeScript):
yarn create block-app [your-block-name]
The generated block package structure looks like this:
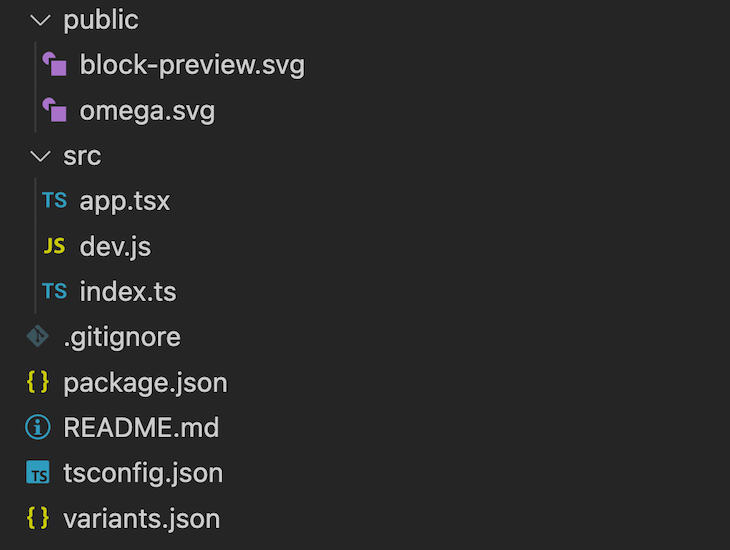
Our src/app.tsx file is the starting point for the block:
import { BlockComponent } from "blockprotocol/react";
import * as React from "react";
type AppProps = {
name: string;
};
export const App: BlockComponent<AppProps> = ({ entityId, name }) => (
<>
<h1>Hello, {name}!</h1>
<p>
The entityId of this block is {entityId}. Use it to update its data when
calling updateEntities.
</p>
</>
);
Running yarn install && yarn dev, and opening http://localhost:63212 in the browser, we can visualize our scaffolded block:
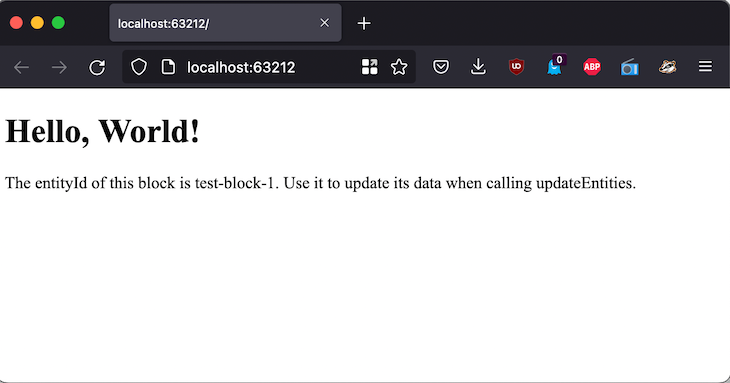
We can then edit our block, ensuring that the Block Protocol’s required block-schema.json, which is the JSON schema documenting the block properties, can already be added to the root of the project (as in the unpublished countdown block), or it can also be generated as an artifact from TypeScript (as with the table block).
To bundle the component, run yarn build to generate a release file including all the block dependencies, minus the common dependencies (such as React), which must be loaded by the application and not by the block. (These common dependencies must be declared under the peerDependencies entry of the block’s package.json.)
The Block Hub is a repository of open source blocks, managed by the company behind the Block Protocol, HASH. We can publish our blocks to this registry if we wish for others to use them; if our intention is to create blocks for our own applications only, then we can completely skip this step.
In order to embed the block in the application, we must first have the application provide all the required data to the block, including:
Once this is done, we must render the block, but as of publication, this procedure does not come without complications, as we’ll learn in the next section.
Unfortunately, the documentation for rendering blocks in the app is still currently incomplete:
We will be releasing source code in January 2022 which demonstrates how all this can be done.
HASH is building its website based on the Block Protocol, so we can use this web application as an example to follow. However, we can’t fully rely on it yet, because:
This app is not yet ready for production use. For now it is intended to be used as a test-harness for developers building Block Protocol-compliant blocks. It is currently not secure, not optimized, and missing key features.
The beta of this web application should’ve been ready by April 2022, but it didn’t make it on time and its roadmap was pushed forward to “Q3 2022”:
Moreover, the Block Protocol is still a draft, and plenty of work is needed until it becomes stable. Some sections in the spec need to be fundamentally improved (including some important ones, such as block styling), and new sections may need be added (such as a “configuration” section, indicating what options the application can display for editing and configuring the block). As such, the spec is not yet ready to power applications for production. We’ll discuss these unfinished items in more detail in a section below.
We should not expect the Block Protocol to reach v1.0 before having a fully-functional, compliant application because, when working with an actual real-life application, developers will find issues within the spec that must be rectified. Mostly during the initial stages of the project, this produces a self-relying cycle: the application will help improve the spec, and upgrading the spec will help define how to make the app compliant with it. The fact that the compliant app is not ready effectively demonstrates that the spec is not ready.
In summary, the Block Protocol should not be used yet. We can start playing with it already, but if our goal is to develop protocol-compliant blocks and applications for production, then we should wait until the minimal requirements are met.
As much as the benefits of the Block Protocol are worth pursuing, we must also explore the costs and drawbacks associated with the project.
The section on styling blocks is not 100 percent suitable because it imposes restrictions on how much we can style our blocks. This is because the block is treated as a black box, and supports only a handful of CSS properties being injected into the block via props.
There is a discussion requesting feedback to improve the solution, but the problem may be intractable: as the Block Protocol will not accept every single CSS property, there may always be some unsupported property that we need to use — even basic ones, such as margins and paddings, are not currently supported.
As a consequence, styling our blocks may end up having to be “good enough” instead of “perfect,” possibly making us not able to reflect our brand identity in our blocks.
When using a block available in the Hub, we will be using a generic block that was not specifically designed for our application. If the block contains functionality that we do not need, then our application will suffer performance penalties, as the code for that functionality will still be shipped and must still be parsed by the JavaScript engine.
If the application supports custom features, which are not expected to work in a generic context, then a generic block will not support them.
An example is dynamic tokens, a custom feature proposed for the WordPress editor, which requires a custom "tokenSupport" section in the block’s JSON schema:
{
"attributes": {
"url": {
"type": "string",
"source": "attribute",
"selector": "img",
"attribute": "src"
}
},
"tokenSupport": {
"core/featured-image": {
"selector": "img",
"attribute": "src"
}
}
}
As "tokenSupport" is not a property to be expected in a generic block, the Block Protocol could not support it. Then, by using generic blocks, the WordPress site will be less powerful when using the Block Protocol than when relying on native blocks.
Abstracting blocks so that they work anywhere and everywhere is a magnificent goal, but in practice it involves plenty of effort to achieve. This is because there are dozens of elements that must be considered for abstraction, and a single one of them that cannot be satisfied may be enough to render the approach unusable.
I have in the past converted my GraphQL server for WordPress to make it agnostic of the underlying CMS (the fact that this concerns PHP instead of JavaScript is irrelevant, as the functionalities to abstract are standard across any application, independent of their stack). The development took three months to accomplish, and it was so extensive in scope that it required two articles to document it (one for describing the strategy, and another one for explaining the implementation). The abstraction was not even complete, as certain features remained CMS-specific.
Now, I’m not suggesting that creating generic blocks is not worth pursuing, as I’m indeed quite satisfied with the abstraction of my GraphQL server, and I do believe it was worth the effort. (For instance, the server can now be executed as a standalone app, which is particularly useful for running unit tests.) However, because the cost of doing the abstraction may be steep, we should evaluate if this cost justifies the potential benefits.
The Block Protocol is a great idea, but it is not ready yet. The protocol was launched without a fully-functional protocol-compliant application to demonstrate its use, which severely limits the development of blocks by the community, and impedes us from properly evaluating the benefits of adopting the protocol for our applications.
After being introduced to the world in January 2022, the Block Protocol got the attention of the development community and managed to receive several hundred stars on GitHub. However, the project seems to have stalled since then, with no significant contributions being made from outside the HASH team.
As publishing blocks to the Hub requires submitting pull requests to the Block Protocol repo, the lack of contributions indicates that the community is not creating blocks, which further demonstrates that the Block Protocol is not ready for prime-time yet — what’s its value, when there’s no marketplace of blocks available for our use?
In summary, the Block Protocol has wonderful potential, but it’s not yet a reality. As timelines are pushed forward and the spec needs significant upgrades, it is not clear when the Block Protocol will be ready for production. Until then, we can start exploring the spec and getting acquainted with it, and consider if the potential benefits of decoupling blocks from apps is worth the extra effort.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

