Retrieval-augmented generation (RAG) integrates retrieval mechanisms with large language models (LLMs) to generate contextually relevant text. RAGs divide documents into chunks before retrieving relevant chunk-based queries and augment input prompts with chunks as context to answer queries.

There are many RAG software options in the market, but the most popular is LlamaIndex due to how easy it is to set up and use. Let’s see how to use LlamaIndex to add personal data to an LLM.
LlamaIndex is a data framework that enhances the capabilities of LLMs through context augmentation. This RAG framework is useful for building apps that require LLMs to operate on private or domain-specific data not built into an LLM.
LlamaIndex provides tools for ingesting, processing, and implementing complex query workflows that combine data access with LLM prompting.
You can build many different projects with LlamaIndex, from QA chatbots to document understanding and extraction to autonomous agents that can perform research and execute actions. It’s available to use in Python and TypeScript to help you build AI-composed apps.
LlamaIndex is really great software, but there are some drawbacks you may encounter when you try using it to add personal data to LLMs. Two of the most important considerations to keep in mind are:
Nonetheless, LlamaIndex is the most popular RAG tool with the most community support, so you should easily find help with navigating these issues.
You can use LlamaIndex when building applications that use AI for chatbots, data retrieval, multimodal interactions, and many other use cases. Since you can add custom data, you can also use LlamaIndex to improve your product offerings.
Here are some integrations where it makes sense to use LlamaIndex and other RAG tools:
These are just a few of the many possibilities you can achieve using RAGs like LlamaIndex in development and production.
RAGs, LLMs, and AI can be daunting subjects for developers, but LlamaIndex is quite straightforward. First, execute this command to create a new virtual environment for this project:
python -m venv llama
Activate the virtual environment with this command:
source llama/bin/activate
Now, install all the dependencies you need to follow through with a simple pip3 install command:
pip3 install llama-index python-dotenv pandas
Let’s quickly review the dependencies we just installed:
llama-index is the library you’ll use to add your data to LLMspython-dotenv is a package that helps with managing environment variablespandas is a popular and powerful library for data analytics and manipulationYou can use Pandas to feed the LLM with structured data like CSV files and then query the LLM for feedback based on the data.
In a real-world app, you’ll likely use customer data or data related to your project. You’ll also likely have a data preparation or manipulation process in place. However, for the purposes of this tutorial, we’ll use this ready-made data on cryptocurrency prices from Kaggle to train the LLM.
Download the dataset from Kaggle, extract the files and add them to a folder in the root directory of your project.
Finally, you’ll need a model to use LlamaIndex. LlamaIndex supports multiple models, and you can use local models as well. We’ll use OpenAI, so create a project and get an API key that you can use to request any of the OpenAI models. Add the environment variable to a .env file with the key OPENAI_API_KEY and you’re good to roll.
Now, let’s go over how you can build a knowledge base with LlamaIndex by adding custom data to the LLM.
Open the Python file in your project and add these imports:
from llama_index.core import TreeIndex, SimpleDirectoryReader import os
You’ll use the os module to load environment variables, but you can do much more, including interacting with the operating system and IO operations on files.
The llama_index.core module contains core functions for working with LlamaIndex. The TreeIndex module helps create and manage indexes in a tree structure, while the SimpleDirectoryReader module reads data from directories.
Next, you must load the OpenAI API key from the environment variables file. Here’s how you can do that with the dotenv module:
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Access the environment variable
api_key = os.getenv("OPENAI_API_KEY")
# Ensure the API key is loaded
if not api_key:
raise ValueError("OPENAI_API_KEY is not set in the .env file")
os.environ["OPENAI_API_KEY"] = api_key
You can use the SimpleDirectoryReader to easily read files in a directory — in this case, the local Crypto directory I have, which contains a bitcoin PDF file — and load the data with the load_data function:
bitcoin = SimpleDirectoryReader("crypto").load_data()
new_index = TreeIndex.from_documents(bitcoin)
The from_documents function of the TreeIndex class creates an index from the documents you specify.
Finally, you can instantiate a query engine to query the LLM with the as_query_engine function and make a query with the query function:
query_engine = new_index.as_query_engine()
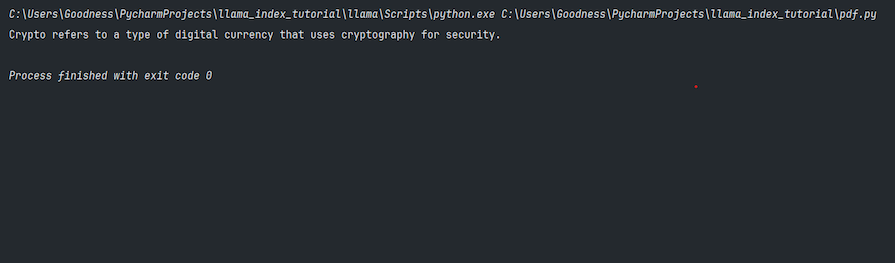
response = query_engine.query("What is Bitcoin")
print(response)
The response variable should hold the output of the query.
Here’s the output from querying the LLM:
The method above is a question-and-answer method where you query the LLM for answers. As discussed earlier, you can also build chatbots and many other AI applications with LlamaIndex.
Here’s how you can build a chatbot with LlamaIndex:
from llama_index.core import TreeIndex, SimpleDirectoryReader
import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Access the environment variable
api_key = os.getenv("OPENAI_API_KEY")
# Ensure the API key is loaded
if not api_key:
raise ValueError("OPENAI_API_KEY is not set in the .env file")
os.environ["OPENAI_API_KEY"] = api_key
# read the directory
bitcoin = SimpleDirectoryReader("crypto").load_data()
# index the directory tree
new_index = TreeIndex.from_documents(bitcoin)
# instantiate a query engine instance
query_engine = new_index.as_query_engine()
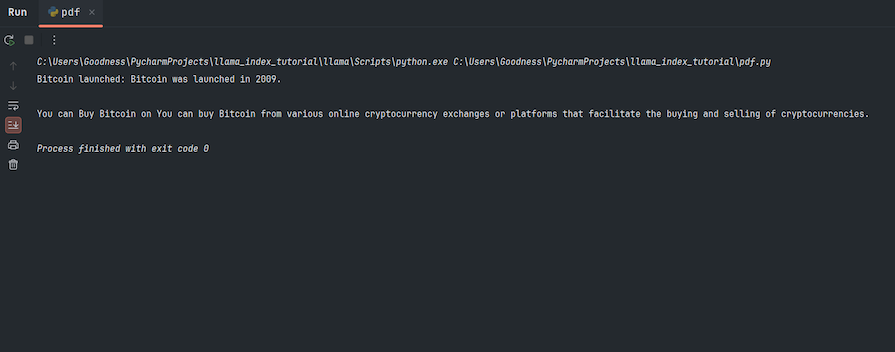
response = query_engine.chat("Who Wrote this document?")
print(response)
In this case, you’re using the chat function with the query_engine instance for chat functionality in contrast to the query function.
Here’s the output in this case:
Head over to the LlamaIndex documentation to learn more about what you can build with LlamaIndex and the tools and models you can use with the LLM.
There are other RAG tools you can explore if LlamaIndex doesn’t suit your needs. Let’s take a look at two popular alternatives: LangChain and Vellum.
LangChain is an open source framework for building apps with LLMs. It supports various LLM tasks beyond RAGs and offers tools for prompt engineering, AI workflows, customization, scaling, lifecycle management, and more:
You can use LangChain to build applications and collaborate through LangSmith, and it’s flexible for handling prompts. LangChain offers more pre-built components than LLamaIndex, although customization and scaling might be challenging since the components are over-engineered.
Vellum is a dedicated LLM product developer tool that offers scalability and advanced customizations for devs and product managers to build AI-ready apps:
You can use Vellum if you want a LlamaIndex alternative that’s easy to customize and adopt. It addresses some of the complexities and limitations you may face with LlamaIndex and LangChain.
Take a look at this table comparing LlamaIndex, LangChain, and Vellum:
| Feature | LlamaIndex | LangChain | Vellum |
|---|---|---|---|
| RAG applications | Seamless data indexing and retrieval | Supports RAG architectures but complex to scale | Focuses on production-ready AI apps with ease of use |
| AI workflows | Primarily for RAG architectures | More out-of-the-box components for diverse workflows | End-to-end development platform for AI apps |
| Prompt engineering | Basic prompt templates | LangSmith for prompt organization and versioning | Advanced prompt customization and comparison |
| Evaluation | Component-based evaluation for RAG | LangSmith evaluator suite for general LLM tasks | Comprehensive evaluation at scale |
| Lifecycle management | Integrations with observability tools | LangSmith for detailed debugging and monitoring | Full lifecycle management with version control |
| Scalability | Challenges with customization and complexity | More pre-built components but complex to manage | Built for scalability and advanced customizations |
| Community & improvements | Active community, proprietary core | Active community, open-source contributions | Continuous improvement with cross-functional collaboration |
In this tutorial, we learned about LlamaIndex and how you can use this RAG tool to add personal data to LLMs for the various use cases you may have. We explored a practical example using a sample dataset from Kaggle and then set up a simple chatbot with LlamaIndex.
Beyond the demos we saw in this article, you can do so much with customized LLMs in development and production. LlamaIndex and other tools make advanced application features possible, from question-and-answer features to chatbots and more. Happy coding!
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

