Hi everyone! 👋

You’ve probably heard of FastAPI, Strawberry, GraphQL, and the like. Now, we’ll be showing you how to put them together in a Next.js app. We will be focusing on getting a good developer experience (DX) with typed code. Plenty of articles can teach you how to use each individually, but there aren’t many resources out there on putting them together, particularly with Strawberry.
There are multiple Python-based GraphQL libraries and they all vary slightly from each other. For the longest time, Graphene was a natural choice as it was the oldest and was used in production at different companies, but now other newer libraries have also started gaining some traction.
We will be focusing on one such library called Strawberry. It is relatively new and requires Python v3.7+ because it makes use of Python features that weren’t available in earlier versions of the language. It makes heavy use of dataclasses and is fully typed using mypy.
N .B., you can find the complete code from this article on GitHub.
We will have a basic project structure in place that will demonstrate how you can successfully start writing SQLAlchemy + Strawberry + FastAPI applications while making use of types and automatically generating typed React Hooks to make use of your GraphQL queries and mutations in your Typescript code. The React Hooks will make use of urql, but you can easily switch it out for Apollo.
I will create the DB schema based on the idea of a bookstore. We will store information about authors and their books. We will not create a full application using React/Next.js but will have all the necessary pieces in place to do so if required.
The goal is to have a better developer experience by using types everywhere and automating as much of the code generation as possible. This will help catch a lot more bugs in development.
This post is inspired by this GitHub repo.
We first need to install the following libraries/packages before we can start working:
Let’s create a new folder and install these libraries using pip. Instead of creating the new folder manually, I will use the [create-next-app](https://nextjs.org/docs/api-reference/create-next-app) command to make it. We will treat the folder created by this command as the root folder for our whole project. This just makes the explanation easier. I will discuss the required JS/TS libraries later on. For now, we will only focus on the Python side.
Make sure you have create-next-app available as a valid command on your system. Once you do, run the following command in the terminal:
$ npx create-next-app@latest --typescript strawberry_nextjs
The above command should create a strawberry_nextjs folder. Now go into that folder and install the required Python-based dependencies:
$ cd strawberry_nextjs $ python -m venv virtualenv $ source virtualenv/bin/activate $ pip install 'strawberry-graphql[fastapi]' fastapi 'uvicorn[standard]' aiosqlite sqlalchemy
Let’s start with a “Hello, world!” example and it will show us the bits and pieces that make up a Strawberry application. Create a new file named app.py and add the following code:
import strawberry
from fastapi import FastAPI
from strawberry.fastapi import GraphQLRouter
authors: list[str] = []
@strawberry.type
class Query:
@strawberry.field
def all_authors(self) -> list[str]:
return authors
@strawberry.type
class Mutation:
@strawberry.field
def add_author(self, name: str) -> str:
authors.append(name)
return name
schema = strawberry.Schema(query=Query, mutation=Mutation)
graphql_app = GraphQLRouter(schema)
app = FastAPI()
app.include_router(graphql_app, prefix="/graphql")
Let’s look at this code in chunks. We start by importing the required libraries and packages. We create an authors list that acts as our temporary database and holds the author names (we will create an actual database briefly).
We then create the Query class and decorate it with the strawberry.type decorator. This converts it into a GraphQL type. Within this class, we define an all_authors resolver that returns all the authors from the list. A resolver needs to state its return type as well. We will look at defining slightly complex types in the next section, but for now, a list of strings would suffice.
Next, we create a new Mutation class that contains all the GraphQL mutations. For now, we only have a simple add_author mutation that takes in a name and adds it to the authors list.
Then we pass the query and mutation classes to strawberry.Schema to create a GraphQL schema and then pass that on to GraphQLRouter. Lastly, we plug in the GraphQLRouter to FastAPI and let GraphQLRouter handle all incoming requests to /graphql endpoint.
If you don’t know what these terms mean, then let me give you a quick refresher:
You can read more about the schema basics in Strawberry in the official docs page.
To run this code, hop on over to the terminal and execute the following command:
$ uvicorn app:app --reload --host '::'
This should print something like the following as output:
INFO: Will watch for changes in these directories: ['/Users/yasoob/Desktop/strawberry_nextjs'] INFO: Uvicorn running on http://[::]:8000 (Press CTRL+C to quit) INFO: Started reloader process [56427] using watchgod INFO: Started server process [56429] INFO: Waiting for application startup. INFO: Application startup complete.
Now go to https://127.0.0.1:8000/graphql and you should be greeted by the interactive GraphiQL playground:

Try executing this query:
query MyQuery {
allAuthors
}
/pre>
This should output an empty list. This is expected because we don’t have any authors in our list. However, we can fix this by running a mutation first and then running the above query.
To create a new author, run the addAuthor mutation:
mutation MyMutation {
addAuthor(name: "Yasoob")
}
And now if you rerun the allAuthors query, you should see Yasoob in the output list:
{
"data": {
"allAuthors": [
"Yasoob"
]
}
}
You might have already realized this by now, but Strawberry automatically converts our camelcase fields into PascalCase fields internally so that we can follow the convention of using PascalCase in our GraphQL API calls and camelcase in our Python code.
With the basics down, let’s go ahead and start working on our bookstore-type application.
The very first thing we need to figure out is what our schema is going to be. What queries, mutations, and types do we need to define for our application.
I will not be focusing on GraphQL basics but rather only on the Strawberry-specific parts in this article. As I already mentioned, we will be following the idea of a bookstore. We will store the data for authors and their books. This is what our database will look like at the end:

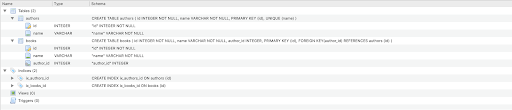
We will be working with SQLAlchemy, so let’s define both of our models as classes. We will be using async SQLAlchemy. Create a new models.py file in the strawberry_nextjs folder and add the following imports:
import asyncio from contextlib import asynccontextmanager from typing import AsyncGenerator, Optional from sqlalchemy import Column, ForeignKey, Integer, String from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship, sessionmaker
These imports will make sense in just a bit. We will be defining our models declaratively using classes that will inherit from the declarative base model from SQLAlchemy. SQLAlchemy provides us with declarative_base() function to get the declarative base model. Let’s use that and define our models:
Base = declarative_base()
class Author(Base):
__tablename__ = "authors"
id: int = Column(Integer, primary_key=True, index=True)
name: str = Column(String, nullable=False, unique=True)
books: list["Book"] = relationship("Book", lazy="joined", back_populates="author")
class Book(Base):
__tablename__ = "books"
id: int = Column(Integer, primary_key=True, index=True)
name: str = Column(String, nullable=False)
author_id: Optional[int] = Column(Integer, ForeignKey(Author.id), nullable=True)
author: Optional[Author] = relationship(Author, lazy="joined", back_populates="books")
Our Author class defines two columns: id and name. books is just a relationship attribute that helps us navigate the relationships between models but is not stored in the authors table as a separate column. We back populate the books attribute as author. This means that we can access book.author to access the linked author for a book.
The Book class is very similar to the Author class. We define an additional author_id column that links authors and books. This is stored in the book table, unlike the relationships. And we also back populate the author attribute as books. This way we can access the books of a particular author like this: author.books.
Now we need to tell SQLAlchemy which DB to use and where to find it:
engine = create_async_engine(
"sqlite+aiosqlite:///./database.db", connect_args={"check_same_thread": False}
)
We use aiosqlite as part of the connection string as aiosqlite allows SQLAlchemy to use the SQLite DB in an async manner. And we pass the check_same_thread argument to make sure we can use the same connection across multiple threads.
It is not safe to use SQLite in a multi-threaded fashion without taking extra care to make sure data doesn’t get corrupted on concurrent write operations, so it is recommended to use PostgreSQL or a similar high-performance DB in production.
Next, we need to create a session:
async_session = sessionmaker(
bind=engine,
class_=AsyncSession,
expire_on_commit=False,
autocommit=False,
autoflush=False,
)
To make sure we properly close the session on each interaction, we will create a new context manager:
@asynccontextmanager
async def get_session() -> AsyncGenerator[AsyncSession, None]:
async with async_session() as session:
async with session.begin():
try:
yield session
finally:
await session.close()
We can use the session without the context manager too, but it will mean that we will have to close the session manually after each session usage.
Lastly, we need to make sure we have the new DB created. We can add some code to the models.py file that will create a new DB file using our declared models if we try to execute the models.py file directly:
async def _async_main():
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all)
await conn.run_sync(Base.metadata.create_all)
await engine.dispose()
if __name__ == "__main__":
print("Dropping and re/creating tables")
asyncio.run(_async_main())
print("Done.")
This will drop all the existing tables in our DB and recreate them based on the models defined in this file. We can add safeguards and make sure we don’t delete our data accidentally, but that is beyond the scope of this article. I am just trying to show you how everything ties together.
Now our models.py file is complete and we are ready to define our Strawberry Author and Book types that will map onto the SQLAlchemy models.
By the time you read this article, Strawberry might have stable inbuilt support for directly using SQLAlchemy models, but for now, we have to define custom Strawberry types that will map on to SQLAlchemy models. Let’s define those first and then understand how they work. Put this code in the app.py file:
import models
# ...
@strawberry.type
class Author:
id: strawberry.ID
name: str
@classmethod
def marshal(cls, model: models.Author) -> "Author":
return cls(id=strawberry.ID(str(model.id)), name=model.name)
@strawberry.type
class Book:
id: strawberry.ID
name: str
author: Optional[Author] = None
@classmethod
def marshal(cls, model: models.Book) -> "Book":
return cls(
id=strawberry.ID(str(model.id)),
name=model.name,
author=Author.marshal(model.author) if model.author else None,
)
To define a new type, we simply create a class and decorate it with the strawberry.type decorator. This is very similar to how we defined the Mutation and Query types. The only difference is that this time, we will not pass these types directly to strawberry.Schema so Strawberry won’t treat them as Mutation or Query types.
Each class has a marshal method. This method is what allows us to take in a SQLAlchemy model and create a Strawberry type class instance from it. Strawberry uses strawberry.ID to represent a unique identifier to an object. Strawberry provides a few scalar types by default that work just like strawberry.ID. It is up to us how we use those to map our SQLAlchemy data to this custom type class attribute. We generally try to find the best and closely resembling alternative to the SQLAlchemy column type and use that.
In the Book class, I also show you how you can mark a type attribute as optional and provide a default value. We mark the author as optional. This is just to show you how it is done; later, I will mark this as required.
Another thing to note is that we can also define a list of return types for our mutation and query calls. This helps ensure our GraphQL API consumer can process the output appropriately based on the return type it receives.
If you know about GraphQL, then this is how we define fragments. Let’s first define the types, and then I will show you how to use them once we start defining our new mutation and query classes:
@strawberry.type
class AuthorExists:
message: str = "Author with this name already exists"
@strawberry.type
class AuthorNotFound:
message: str = "Couldn't find an author with the supplied name"
@strawberry.type
class AuthorNameMissing:
message: str = "Please supply an author name"
AddBookResponse = strawberry.union("AddBookResponse", (Book, AuthorNotFound, AuthorNameMissing))
AddAuthorResponse = strawberry.union("AddAuthorResponse", (Author, AuthorExists))
We are basically saying that our AddBookResponse and AddAuthorResponse types are union types and can be either of the three (or two) types listed in the tuple.
Let’s define our queries now. We will have only two queries. One to list all the books and one to list all the authors:
from sqlalchemy import select
# ...
@strawberry.type
class Query:
@strawberry.field
async def books(self) -> list[Book]:
async with models.get_session() as s:
sql = select(models.Book).order_by(models.Book.name)
db_books = (await s.execute(sql)).scalars().unique().all()
return [Book.marshal(book) for book in db_books]
@strawberry.field
async def authors(self) -> list[Author]:
async with models.get_session() as s:
sql = select(models.Author).order_by(models.Author.name)
db_authors = (await s.execute(sql)).scalars().unique().all()
return [Author.marshal(loc) for loc in db_authors]
There seems to be a lot happening here, so let’s break it down.
First, look at the books resolver. We use the get_session context manager to create a new session. Then we create a new SQL statement that selects Book models and orders them based on the book name.
Afterward, we execute the SQL statement using the session we created earlier and put the results in the db_books variable. Finally, we marshal each book into a Strawberry Book type and return that as an output. We also mark the return type of books resolver as a list of Books.
The authors resolver is very similar to the books resolver, so I don’t need to explain that.
Let’s write our mutations now:
@strawberry.type
class Mutation:
@strawberry.mutation
async def add_book(self, name: str, author_name: Optional[str]) -> AddBookResponse:
async with models.get_session() as s:
db_author = None
if author_name:
sql = select(models.Author).where(models.Author.name == author_name)
db_author = (await s.execute(sql)).scalars().first()
if not db_author:
return AuthorNotFound()
else:
return AuthorNameMissing()
db_book = models.Book(name=name, author=db_author)
s.add(db_book)
await s.commit()
return Book.marshal(db_book)
@strawberry.mutation
async def add_author(self, name: str) -> AddAuthorResponse:
async with models.get_session() as s:
sql = select(models.Author).where(models.Author.name == name)
existing_db_author = (await s.execute(sql)).first()
if existing_db_author is not None:
return AuthorExists()
db_author = models.Author(name=name)
s.add(db_author)
await s.commit()
return Author.marshal(db_author)
Mutations are fairly straightforward. Let’s start with the add_book mutation.
add_book takes in the name of the book and the name of the author as inputs. I am defining the author_name as optional just to show you how you can define optional arguments, but in the method body, I enforce the presence of author_name by returning AuthorNameMissing if the author_name is not passed in.
I filter Authors in db based on the passed in author_name and make sure that an author with the specified name exists. Otherwise, I return AuthorNotFound.
If both of these checks pass, I create a new models.Book instance, add it to the db via the session, and commit it. Finally, I return a marshaled book as the return value. add_author is almost the same as add_book, so thter’s no reason to go over that code again.
We are almost done on the Strawberry side; just a few more minutes before we wrap it up.
Another (not always) fun feature of GraphQL is recursive resolvers. You saw above that in the marshal method of Book I also define author. This way we can run a GraphQL query like this:
query {
book {
author {
name
}
}
}
But, suppose we want to run a query like this:
query {
author {
books {
name
}
}
}
This will not work because we haven’t defined a books attribute on our Strawberry type. Let’s rewrite our Author class and add a DataLoader to the default context Strawberry provides us in our class methods:
from strawberry.dataloader import DataLoader
# ...
@strawberry.type
class Author:
id: strawberry.ID
name: str
@strawberry.field
async def books(self, info: Info) -> list["Book"]:
books = await info.context["books_by_author"].load(self.id)
return [Book.marshal(book) for book in books]
@classmethod
def marshal(cls, model: models.Author) -> "Author":
return cls(id=strawberry.ID(str(model.id)), name=model.name)
# ...
async def load_books_by_author(keys: list) -> list[Book]:
async with models.get_session() as s:
all_queries = [select(models.Book).where(models.Book.author_id == key) for key in keys]
data = [(await s.execute(sql)).scalars().unique().all() for sql in all_queries]
print(keys, data)
return data
async def get_context() -> dict:
return {
"books_by_author": DataLoader(load_fn=load_books_by_author),
}
# ...
Let’s understand this code from the bottom up. Strawberry allows us to pass custom functions to our class (those wrapped with @strawberry.type) methods via a context. This context is shared across a single request.
DataLoader allows us to batch multiple requests so that we can reduce back and forth calls to the db. We create a DataLoader instance and inform it how to load books from the db for the passed-in author. We put this DataLoader in a dictionary and pass that as the context_getter argument to GraphQLRouter. This makes the dictionary available to our class methods via info.context. We use that to load the books for each author.
In this example, DataLoader isn’t super useful. Its main benefits shine through when we call the DataLoader with a list of arguments. That reduces the database calls considerably. And DataLoaders also cache output and they are shared in a single request. Therefore, if you were to pass the same arguments to the data loader in a single request multiple times, it will not result in additional database hits. Super powerful!
Strawberry allows us to define custom input types for our mutations and queries. This is a feature of GraphQL itself that is supported by Strawberry and allows us to limit the number of types we can use for different fields.
Let’s use custom input types to add a filter to our books query in order to enable users to filter books by a particular author.
We will start by defining a custom input type:
@strawberry.input
class BooksQueryInput:
author_name: Optional[str] = strawberry.UNSET
This class will encapsulate all the inputs we expect to receive for our books query. We are making the author_name optional. We will filter the books based on this value if it is present. strawberry.UNSET makes the field optional in the generated GraphQL schema.
Next, we need to use this custom input in our books query and filter the books based on the author_name if present:
@strawberry.type
class Query:
@strawberry.field
async def books(self, query_input: Optional[BooksQueryInput] = None) -> list[Book]:
async with models.get_session() as s:
if query_input:
sql = select(models.Book).join(models.Author) \
.filter(models.Author.name == query_input.author_name)
else:
sql = select(models.Book).order_by(models.Book.name)
db_book = (await s.execute(sql)).scalars().unique().all()
return [Book.marshal(book) for book in db_book]
In the code above, we are defining a new optional method argument with the name of query_input. We set its default value to None to ensure our query works even when it is not present. Then, we modify the SQL query and add a filter based on the author name if it is present.
The uvicorn instance should automatically reload once you make these code changes and save them. Go over to http://127.0.0.1:8000/graphql and test out the latest code.
Try executing the following mutation twice:
mutation Author {
addAuthor(name: "Yasoob") {
... on Author {
id
name
}
... on AuthorExists{
message
}
}
}
The first time it should output this:
{
"data": {
"addAuthor": {
"id": "1",
"name": "Yasoob"
}
}
}
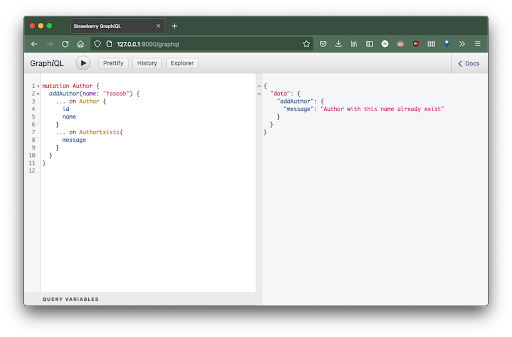
The second time it should output this:
{
"data": {
"addAuthor": {
"message": "Author with this name already exist"
}
}
}

Now, let’s try adding new books:
mutation Book {
addBook(name: "Practical Python Projects", authorName: "Yasoob") {
... on Book {
id
name
}
}
}

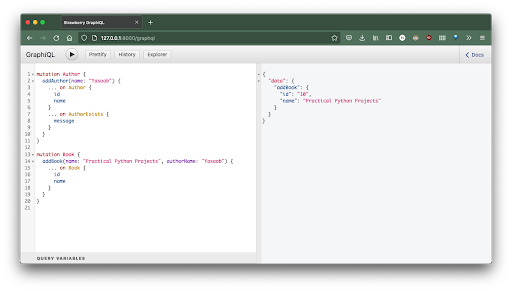
Finally, let’s add another A``uthor and B``ook. To do so, run this new mutation:
mutation addAuthors {
secondAuthor: addAuthor(name: "Ahmed") {
... on Author {
id
name
}
... on AuthorExists{
message
}
}
ahmedBook: addBook(name: "Ahmed's book", authorName: "Ahmed") {
... on Book{
id
name
}
... on AuthorNotFound {
message
}
... on AuthorNameMissing{
message
}
}
}
Now we can try the books query to make sure we are getting the result we expect:
query filterBooks {
all: books{
name
author {
name
}
}
byAuthor: books(queryInput: {authorName: "Yasoob"}) {
name
author {
name
}
}
}
The first query should list two books; the second query should only list only one book:
{
"data": {
"all": [
{
"name": "Ahmed's book",
"author": {
"name": "Ahmed"
}
},
{
"name": "Practical Python Projects",
"author": {
"name": "Yasoob"
}
}node depen
],
"byAuthor": [
{
"name": "Practical Python Projects",
"author": {
"name": "Yasoob"
}
}
]
}
}
Sweet! Our Python/Strawberry side is working perfectly fine. But now we need to tie this up on the Node/Next.js side.
We will be using graphql-codegen to automatically create typed hooks for us. So the basic workflow will be that before we can use a GraphQL query, mutation, or fragment in our Typescript code, we will define that in a GraphQL file. Then graphql-codegen will introspect our Strawberry GraphQL API and create types and use our custom defined GraphQL
Query/Mutations/Fragments to create custom urql hooks.
urql is a fairly full-featured GraphQL library for React that makes interacting with GraphQL APIs a lot simpler. By doing all this, we will reduce a lot of effort in coding typed hooks ourselves before we can use our GraphQL API in our Next.js/React app.
Before we can move on, we need to install a few dependencies:
$ npm install graphql $ npm install @graphql-codegen/cli $ npm install @graphql-codegen/typescript $ npm install @graphql-codegen/typescript-operations $ npm install @graphql-codegen/typescript-urql $ npm install urql
Here we are installing urql and a few plugins for @graphql-codegen.
Now we will create a codegen.yml file in the root of our project that will tell graphql-codegen what to do:
overwrite: true
schema: "http://127.0.0.1:8000/graphql"
documents: './graphql/**/*.graphql'
generates:
graphql/graphql.ts:
plugins:
- "typescript"
- "typescript-operations"
- "typescript-urql"
We are informing graphql-codegen that it can find the schema for our GraphQL API at http://127.0.0.1:8000/graphql. We also tell it (via the documents key) that we have defined our custom fragments, queries, and mutations in graphql files located in the graphql folder. Then we instruct it to generate graphql/graphql.ts file by running the schema and documents through three plugins.
Now make a graphql folder in our project directory and create a new operations.graphql file within it. We will define all the fragments, queries, and mutations we plan on using in our app.
We can create separate files for all three and graphql-codegen will automatically merge them while processing, but we will keep it simple and put everything in one file for now. Let’s add the following GraphQL to operations.graphql:
query Books {
books {
...BookFields
}
}
query Authors {
authors {
...AuthorFields
}
}
fragment BookFields on Book {
id
name
author {
name
}
}
fragment AuthorFields on Author {
id
name
}
mutation AddBook($name: String!, $authorName: String!) {
addBook(name: $name, authorName: $authorName) {
__typename
... on Book {
__typename
...BookFields
}
}
}
mutation AddAuthor($name: String!) {
addAuthor(name: $name) {
__typename
... on AuthorExists {
__typename
message
}
... on Author {
__typename
...AuthorFields
}
}
}
This is very similar to the code we were executing in the GraphiQL online interface. This GraphQL code will tell graphql-codegen which urql mutation and query hooks it needs to produce for us.
There has been discussion to make graphql-codegen generate all mutations and queries by introspecting our online GraphQL API, but so far it is not possible to do that using only graphql-codegen. There do exist tools that allow you to do that, but I am not going to use them in this article. You can explore them on your own.
Let’s edit package.json file next and add a command to run graphql-codegen via npm. Add this code in the scripts section:
"codegen": "graphql-codegen --config codegen.yml"
Now we can go to the terminal and run graphql-codegen:
$ npm run codegen
If the command succeeds, you should have a graphql.ts file in graphql folder. We can go ahead and use the generated urql hooks in our Next code like so:
import {
useAuthorsQuery,
} from "../graphql/graphql";
// ....
const [result] = useAuthorsQuery(...);
You can read more about the graphql-codegen [urql](https://www.graphql-code-generator.com/plugins/typescript-urql) plugin here.
In a production environment, you can serve the GraphQL API and the Next.js/React app from the same domain+PORT and that will make sure you don’t encounter CORS issues.
For the development environment, we can add some proxy code to next.config.js file to instruct NextJS to proxy all calls to /graphql to uvicorn that is running on a different port:
/** @type {import('next').NextConfig} */
module.exports = {
reactStrictMode: true,
async rewrites() {
return {
beforeFiles: [
{
source: "/graphql",
destination: "http://localhost:8000/graphql",
},
],
};
},
};
This will make sure you don’t encounter any CORS issues on local development either.
Of course, Strawberry is not the only GraphQL client that is available for Python and FastAPI. Graphene and Ariadne are both viable alternatives; let’s examine some details about these two libraries.
The biggest difference between these GraphQL libraries is the philosophy they follow. Graphene is similar to Strawberry and follows a code-first approach; we write the code that is then used to generate the GraphQL schema.
Graphene is the oldest GraphQL library for Python and has wide support. It used to be the natural choice for implementing GraphQL-related stuff in Python. It supports some old Python versions that do not allow it to completely rely on newer features of Python. Therefore, unlike Strawberry, Graphene has a bit of a cumbersome API. More boilerplate code is required to get your GraphQL API up and running compared to Strawberry.
If I were to start a new Python project, I would choose Strawberry over Graphene. But, if I wanted to support old Python versions (that Strawberry doesn’t support) and still use with a code-first GraphQL library, I would go with Graphene.
Alternatively, Ariadne follows a schema-first approach. We write the GraphQL schema and then some minimal boilerplate code in Python to get our GraphQL API up and running. Ariadne is a natural choice for developers who prefer this philosophy. Ariadne offers a simple API, making it easy to work with. I would recommend you check out Ariadne to see if its philosophy resonates with you.
I hope you learned a thing or two from this article. I deliberately did not go into too much detail on any single topic as such articles already exist online, but it is very hard to find an article that shows you how everything connects together.
You can find all the code for this article on my GitHub. In the future, I might create a full project to show you a more concrete example of how you can make use of the generated code in your apps. In the meantime, you can take a look at this repo, which was the inspiration for this article. Jokull was probably the first person to publicly host a project combining all of these different tools. Thanks, Jokull!
Also, if you have any Python or web development projects in mind, reach out to me at [email protected] and share your ideas. I do quite a variety of projects so almost nothing is out of the ordinary. Let’s create something awesome together.
😄
See you later! 👋 ❤️
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
Debugging Next applications can be difficult, especially when users experience issues that are difficult to reproduce. If you’re interested in monitoring and tracking state, automatically surfacing JavaScript errors, and tracking slow network requests and component load time, try LogRocket.
LogRocket captures console logs, errors, network requests, and pixel-perfect DOM recordings from user sessions and lets you replay them as users saw it, eliminating guesswork around why bugs happen — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
The LogRocket Redux middleware package adds an extra layer of visibility into your user sessions. LogRocket logs all actions and state from your Redux stores.

Modernize how you debug your Next.js apps — start monitoring for free.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.

Learn how to build a harness-style AI workflow using Claude Code with specialized Dev, QE, and Ops subagents, gated handoffs, MCP telemetry, and LEARNING.md.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

