If you’re reading this article, then I assume you’re fairly convinced of the benefits GraphQL brings to the table. As you may have heard, GraphQL solves one of the fundamental problems of REST, which is the overfetching and underfetching of data.

These problems become even more apparent when you are building a server for mobile-first apps. In REST, there are two ways you can architect and design new requirements:
Both approaches have their own set of tradeoffs: the first option will lead to more round trips, which is not ideal if the mobile user is in a spotty network condition; the second option wastes bandwidth unnecessarily.
We can solve both of these problems elegantly with GraphQL because it promises to give us exactly what we ask for. But if you don’t understand the quirks of GraphQL resolvers, you may run into overfetching problems even with GraphQL. Well-designed resolvers are fundamental to reaping the benefits of GraphQL.
In simple terms, resolvers are functions that resolve the value for a GraphQL type or a field of a GraphQL type. Before we jump into the resolver design process, however, let’s briefly look at the GraphQL query type.
What really makes GraphQL queries tick is the fact that they look like JSON, and everyone knows JSON well. For the sake of explanation, let’s design a GraphQL API for fetching data from a school database that has student and course information in the database.
Let’s say you’re writing a query that looks like:
query {
student(id: "student1") {
name,
courses {
title
}
}
}
Before this query hits the corresponding resolver, it is parsed into a tree/graph. As you might already know, a query is a root type. This means the query will be the root node of the tree, which looks something like this:
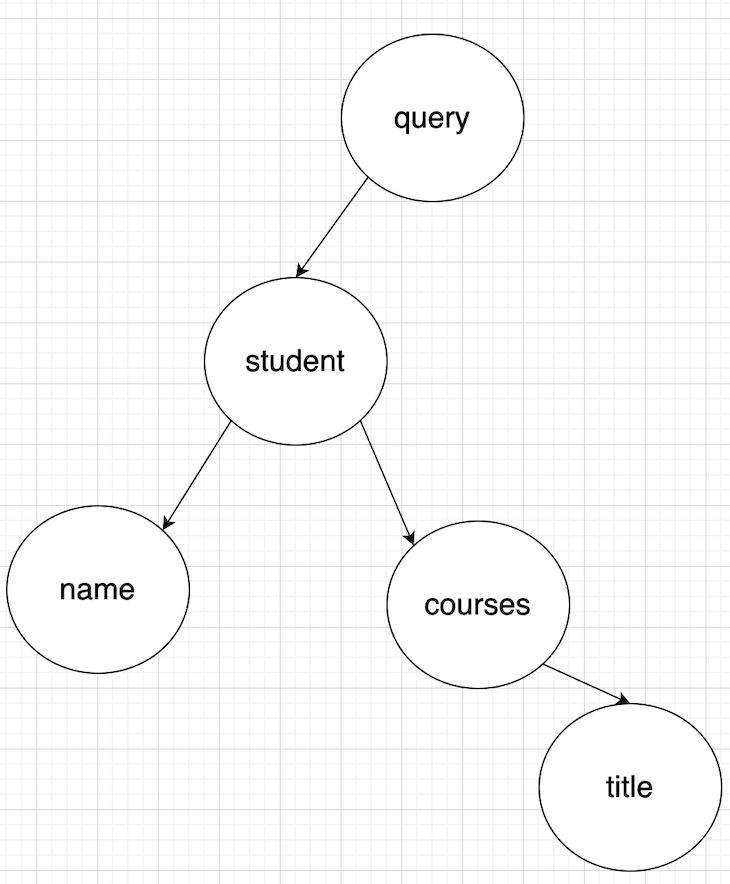
As you can see, query is the root node, and student, name, courses, and title are the children. The GraphQL query is parsed into a tree like this before hitting the resolvers. It’s useful to visualize your queries this way because efficient resolvers are designed based on the actual structure of the queries.
Moving on! Now that we know how to visualize queries as trees, let’s go ahead and write resolvers. A resolver in GraphQL has the following structure:
const resolvers = {
Query: {
student: (root, args, context, info) => { return students[args['id']] }
}
}
root – signifies the result from the parent typeargs – arguments passed to the resolvercontext – a mutable object that can be used for storing/passing common configs like session data, req (in Express), etc.info – contains field information like fieldName, fieldNodes, returnType, etc.Like I mentioned before, resolvers can be written for every type and every field. Let’s go ahead and write a resolver for the Student type. Our schema file looks like this:
type Query {
student(id: String!): Student
}
type Course {
id: String!
title: String
}
type Student {
id: String!
name: String
courses: [Course]
}
I like to keep the resolvers in a separate file. For the sake of this example, I am storing the data in global variables. My resolvers.js file looks like this:
var students = {
'student1': {
id: 'student1',
name: 'karthik',
courses: ['math101', 'geography201']
},
'student2': {
id: 'student2',
name: 'john',
courses: ['physics201', 'chemistry103']
},
};
var courses = {
'math101': {
id: 'math101',
title: 'Intro to algebra',
},
'geography201': {
id: 'geography201',
title: 'Intro to maps',
},
'physics201': {
id: 'physics201',
title: 'Intro to physics',
},
'chemistry103': {
id: 'chemistry103',
title: 'Intro to organic chemistry',
},
};
const resolvers = {
Query: {
student: (root, args, context, info) => {
return students[args['id']]
}
}
}
module.exports = resolvers
As we can see, the resolver for student takes an id in its args and returns the corresponding student from the students object:
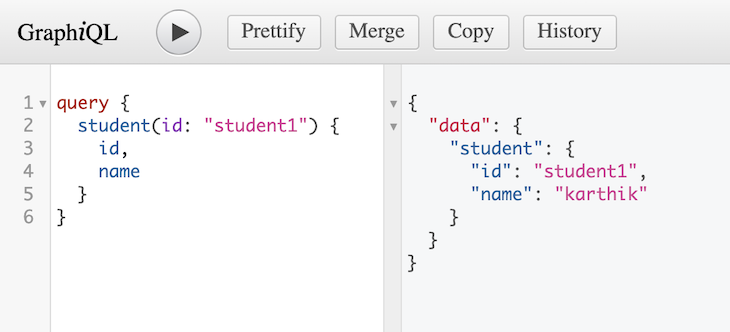
OK, we just saw how the passed argument ID, "student1", hit the resolver through the resolver’s argument, "args". Let’s explore the other arguments.
rootEvery graphQL type has a default resolver. When you don’t write a resolver for a type or a field, GraphQL automatically looks into the root for a property with the same name as the field or a type. The default resolver will look something like this:
const resolvers = {
Query: {
student: (root, args, context, info) => {
return students[args['id']]
},
},
Student: {
name: (root, args, context, info) => {
return root.name;
}
}
}
module.exports = resolvers
On lines 8–9, I have basically implemented what the default resolver for the name field does. If you want to test the theory, return a static string instead of root.name. You will notice that it returns the static string for all queries to student(id).
contextThe context can be used for passing information between resolvers. For instance, if you want to pass the req object down to all fields, you can simply mutate context by adding the req to it.
OK! Basics out of the way. Let’s look at some potential problems we may unknowingly face with the design of resolvers and how we can overcome them.
Yes! You read that right. Isn’t this exactly the reason why we moved away from REST? Absolutely! But there are scenarios in which we could experience overfetching because of the way we have designed our resolvers.
For instance, if you want to write a resolver for "courses" in the student type and fetch the courses along with the student query, we can do something like this:
const resolvers = {
Query: {
student: (root, args, context, info) => {
const studentCourses = students[args['id']]['courses'].map(id => {return courses[id]})
return {
...students[args['id']],
"courses": studentCourses
}
},
},
Student: {
name: (root, args, context, info) => {
return root.name;
}
}
}
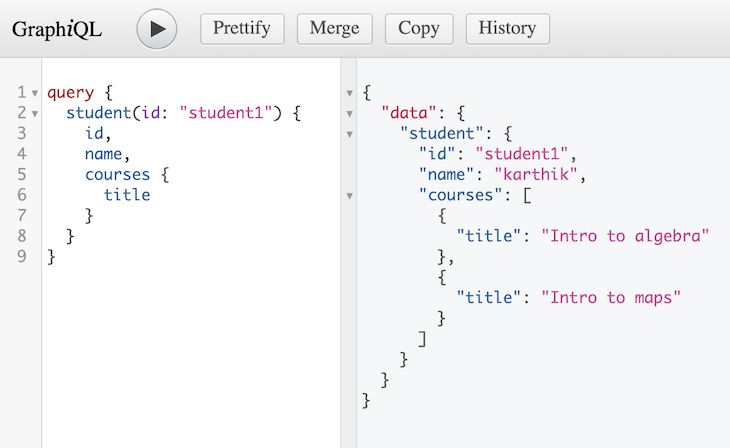
id and name?We would still be unnecessarily doing the operation in line 4. In a real-world scenario, this could even be an expensive API call. But when GraphQL resolves the query, it would drop the extra data on the floor.
On the surface, it still seems like we are getting only what we asked for. But behind the scenes, we have forced our server to overfetch because of the way we designed our resolver.
Solution: Move the courses resolver to the courses field.
const resolvers = {
Query: {
student: (root, args, context, info) => {
return students[args['id']];
},
},
Student: {
name: (root, args, context, info) => {
return root.name;
},
courses: (root, args, context, info) => {
return root.courses.map(id => courses[id]);
}
}
}
Notice how I am leveraging the root argument to my advantage. This is the exact reason why it’s useful to visualize the query as a tree and understand the root node and how you can use it. Now, if we just query for id and name, we are not at risk of resolving the courses unnecessarily.
Great! So does adopting this pattern solve all our problems? Unfortunately not!
You might think it is going to resolve only the courses resolver. But, again, think about the tree — what gets resolved first? The student resolver!
The student node is the parent of the courses node, and GraphQL resolves in a breadth-first search fashion, which means the student node gets resolved before the courses node so that the courses node’s root argument is populated.
Again, we run into overfetching. What to do now?
Let’s move the student resolver down to its fields and resolve the fields separately.
const resolvers = {
Query: {
student: (root, args, context, info) => {
return args['id'];
},
},
Student: {
id: (root, args, context, info) => {
return students[root]['id'];
},
name: (root, args, context, info) => {
return students[root]['name'];
},
courses: (root, args, context, info) => {
return students[root]['courses'].map(id => courses[id]);
}
}
}
Notice how I just returned the id from the student resolver and transferred the concern down to the individual fields. The individual fields are now responsible for resolving its value.
OK, great! So does this solve our problem of overfetching now? It does, but with a caveat.
id, name, and courses?The student object is fetched twice, once each for id and name. But the courses object is fetched only one. This duplication of request is a problem that is much easier to work with if we have the code written in a cleaner and more testable fashion like this.
We can clearly see how many times a particular API will be called by simply looking at the number of fields for a type that uses this API in its resolver. Fortunately, there are a few solutions that can help solve the request duplication problem:
This issue is also known as the N + 1 problem in GraphQL because we make one call to resolve the student and N calls to resolve each of the N types nested in the root type (student).
It depends! If you already have a rich codebase of database APIs (or ORMs) for talking to your underlying database — and if you suspect that some of these calls will be reused to resolve different fields in your GraphQL schema — it is a good practice to adopt a data deduplication solution like those above to fully realize GraphQL’s performance benefits.
You might have noticed that we are repeatedly doing similar operations on lines 9 and 12. In a real-world project, this could be an API call, and calling APIs multiple times to resolve different fields may look bad on the surface and tempt you to refactor it.
But having an understanding of the problem it solves is much more important. When you have a data deduplication solution set up, it’s possible that the API call is made only once and cached for reuse.
So far we have seen how to avoid some of the common problems while writing resolvers. Now let’s take a look at how we can structure the database calls and what options are available to us.
If you are using a SQL database, chances are you already use an ORM like sequelize or sqlalchemy for fetching data from your database. If that’s the case, it’s ideal to call the sequelize APIs inside the resolver functions. This way you can scope the calls specific to that particular field.
It’s also a generally good idea to pass the db configs using resolvers’ context field.
In the case of MongoDB, you can directly use the Mongo CRUD APIs inside the resolvers.
I hope you enjoyed reading this post about GraphQL resolvers, and hopefully you found it useful. Feel free to leave any questions or feedback. 🙂
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how Storybook MCP enables AI agents to understand your component library, generate accurate UI, and validate code using documentation, stories, and automated tests.

Debug RSC hydration mismatches in production with Next.js instrumentation, Suspense isolation, HTML diffing, and CI smoke tests.

Explore why npm dependencies are a major supply chain security risk and how to protect JavaScript apps from compromised packages and transitive threats.

Enabled React Compiler v1.0 on a production Next.js app. Here’s every warning, breakage, and silent opt-out I documented — and what actually worked.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

