While larger back-end systems are usually split up in terms of responsibilities into what we call (micro)services, the client(s) consuming these services are still monoliths. In terms of debugging and coherence this must obviously offer some advantage, otherwise, such a concentration of knowledge seems inefficient and unmaintainable. In this post, I will try to tackle the problem with a solution proposal that works especially great for what I would call “portal-like applications”.
A portal-like application is a client that offers a user access to a set of often unrelated functionality. This set is what I will refer to as modules. The modules share a certain philosophy (e.g., in the workspace domain, UX principles, …) and may offer integration points between each other.
An example of a (frankly, quite massive) portal-like application is Microsoft Office. The modules here are Word, Excel, etc…, which share a common design and are all in the office applications space. The rich text editing experience of Word can be found in many other modules, while Excel’s handling of tables can be easily reused as well.
In general, applications that offer some kind of plugin system (e.g., Visual Studio Code) could be considered a portal-like application. In the end, it all just depends on what kind of functionality is offered by the “base-layer” (the application itself) to the different modules that are integrated at runtime.
The frontend monolith is a common problem especially arising in enterprise applications. While the backend architecture is usually designed to be modular these days, the frontend is still developed in a single codebase. In other words, while the backend is nicely split in terms of responsibility and knowledge, the frontend remains a large monolith, which requires knowledge about the whole backend. Even worse, changes in a single backend service may require a frontend change that comes with a new release.
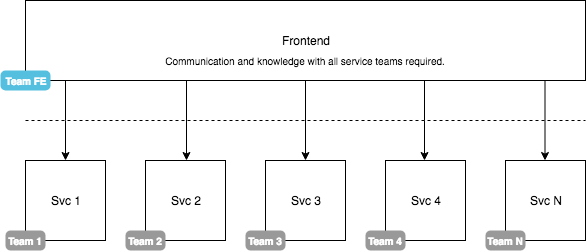
As a consequence the frontend becomes the bottleneck since it eventually becomes too hard to maintain, is too quickly outdated, and has way too many components.
In the diagram shown above, we could easily insert an API gateway or other layers between the frontend and the services. In the end, such details won’t change the big picture.
There are multiple reasons why such an architecture is problematic. For me personally one of the most important reasons why such an architecture is suboptimal is the dependency problem. Any change in the backend propagates directly to the client.
Let’s look at our diagram again to see this problem:
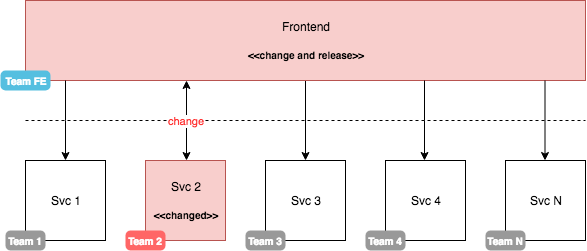
If we have a (breaking) change in one of the backend services we consume, we need to propagate this change up to the client. This means reflecting the same change (potentially in multiple components, which could be more or less tedious) and creating another release. Even worse, in multi-environment development (e.g., having a stage and a production environment) our client may now only be compatible with stage but is blocked for production until the respective backend service goes into production.
Another problem we see with this approach is the concentration of knowledge. The frontend team either needs to be large or consist only of superstars, who can cope with the whole backend knowledge. The last thing this team needs to do is to keep in touch with the various backend teams to ensure that any change is reflected in the client.
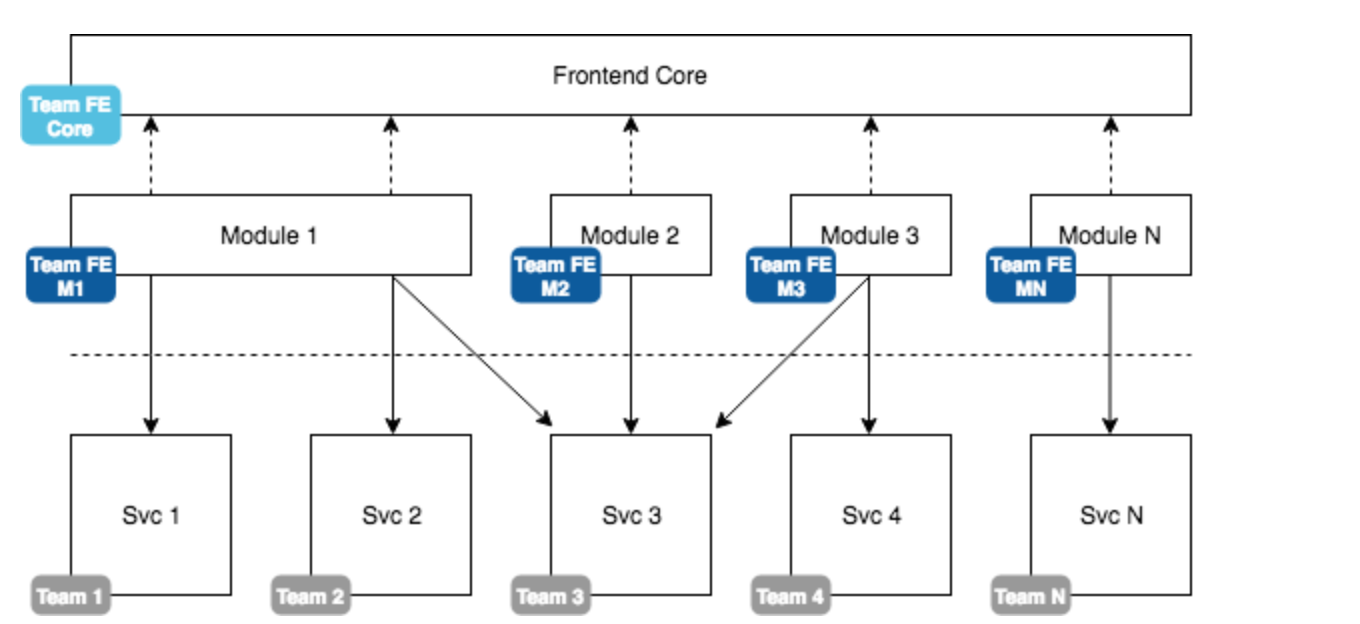
Ideally, our frontend follows a similar approach to our backend. While we split services by their responsibilities we should split the frontend in terms of user functionality. This could look as simple as the following architecture diagram displays:
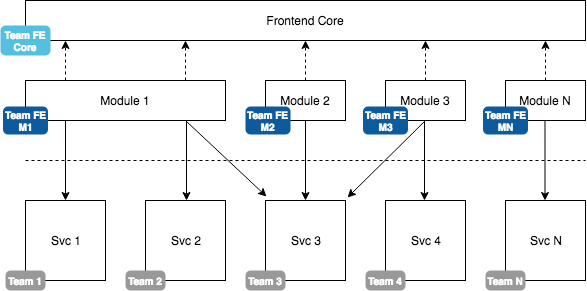
We create frontend modules that may depend on any number of backend services. While there may be an overlap in service consumption, usually we are driven by exposing the capabilities of a particular service in terms of a UI. The frontend modules are consumed by a frontend core (“portal”) at runtime.
As a consequence of this architecture a change of a backend service has a much smaller impact:
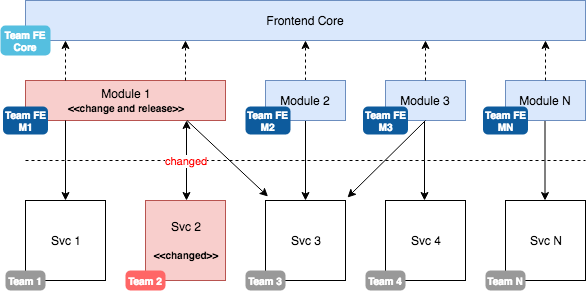
Having multiple environments does not matter much as the core layer and all other modules are not impacted. Thus the service may remain in stage, while all other modules may still see new features and other updates. Once the service is deployed in production we simply deploy the respective frontend module in production. The whole process is boosted by feature flags, which we will see later in this article.
In such an architecture the responsibilities are also quite clear, the frontend core is only responsible for the technical / non-functional aspects of the application. Here, we would take care of authentication, API requests, communication between the modules, notification and dialogue management, websocket connections, caching, and the overall design of the application (aka layout).
The modules take care specifically about functional aspects. One module has the responsibility to allow the user to do a specific thing. Here (using the given layout) we would specify the rendering of a page’s content, or what kind of API / service we need to talk to for getting the domain-specific data.
There are multiple details that we require for such an implementation. There are also other details which may be handy but are not necessary to achieve such an architecture. Let’s first look at what we need for sure:
As far as the first point is concerned we need two specifications, one for the API to be consumed in a client and another one to ensure our backend service can successfully read and expose the modules. We will only focus on the API side of things here.
A natural choice is to assume a declaration per module that can be typed like this:
interface ModuleMetadata {
/**
* The name of the module, i.e., the package id.
*/
name: string;
/**
* The version of the module. Should be semantically versioned.
*/
version: string;
/**
* The functional content of the module.
*/
content: string;
}
There is much more we could include here (e.g., dependencies, hash, …). Most notably, the content field would contain the (JavaScript) code that needs to be evaluated. (For details on how the JavaScript needs to be structured see below.)
In regards to point number two listed above (backend service to allow downloading the available modules) we could write a simple service that consumes, e.g., a feed of NPM packages (like the official npmjs.org feed), and combines found packages by bundling (parts of the) package.json with the JavaScript referenced in the main field.
What we need to keep in mind here:
main, install, setup, …) which is used as the setup point from our core layerA bundled module may be as simple as:
const React = require('react');
// Note: left JSX for readability, normally this already
// uses React.createElement and is properly minified.
const MyPage = props => (
<div>Hello from my page!</div>
);
module.exports = {
setup(app) {
// Sample API, may look completely different
app.registerPage('/my-route', MyPage);
},
};
Evaluating such a module (coming in form of a string) in our application can be done with a function like the following (TypeScript annotations for readability):
function evalModule(name: string, content: string, dependencies: DependencyMap = {}) {
const mod = {
exports: {},
};
const require = (moduleName: string) => dependencies[moduleName] ||
console.error(`Cannot find module "${moduleName}" (required by ${name})`, dependencies);
try {
const importer = new Function('module', 'exports', 'require', content);
importer(mod, mod.exports, require);
} catch (e) {
console.error(`Error while evaluating module "${name}".`, e);
}
return mod.exports;
}
These modules could also be cached or sent in pre-evaluated as outlined earlier. The given evalModule function supports UMD modules, but will not have great support for source maps (i.e., zero). Considering that these source maps would not leak into production we could be fine with that, otherwise, other techniques seem necessary.
In general, the downloading at runtime is quite important. Runtime could mean two things:
These two approaches are not exclusive. Ideally, both approaches are implemented. Nevertheless, for simplicity, we will focus on the SPA approach here.
For a SPA the download of modules could be as simple as making a fetch call to some backend API. That leaves us with requirement number four listed above, which states we should have a proper frontend API. We already saw such an API (in form of the app parameter) in the example module given above. Obviously, there are two ways of creating such an integration point:
The latter is more descriptive and “pure”, however, is limited in the long run. What if a module wants to add (or remove) functionality during its runtime? Depending on a user input, certain things( e.g., some page) could be shown which otherwise should not be part of the routing process. As the former approach is more powerful we will go with this.
For each imported module we simply create an object that holds all functions for the module to access. This is the object we pass on. We create a dedicated object for each module to protect the API and disallow any changes from one module influencing another module.
I’ve mapped out the whole process in React in form of a small library called React Arbiter. It allows “recalling” modules at runtime and provides further tools, e.g., for placing the registered components in “stasis fields” to ensure nothing breaks our application.
One of the advantages a modular frontend offers us is the possibility of feature-flagging the modules. That way only code that can be executed will be downloaded. Furthermore, since our frontend builds up from these modules implicitly, no blocked functionality will be shown. By definition, our frontend is consistent.
A sample project is available at GitHub. The sample shows four things:
Keep in mind that the given repository is for demonstration purposes only. There is no real design, the API is not scalable, and the development process for the different modules is not really smooth.
Nevertheless, the basic ideas of this article are certainly incorporated in this toy project. The feature flags can be toggled by editing the features.json file and we see how data can flow from one module to another. Finally, this project is also a good starting point to experiment with novel APIs or advanced topics such as server-side rendering.
If we like the concept shown here, but we are not willing to (or cannot) invest the time for implementing all the various parts, we could just fall back to an open-source solution that has been released recently: Piral gives us all the described frontend parts of this article.
The stack of Piral is actually quite straight forward. The piral-core library has peer dependencies to some crucial React libraries (DOM, router, and React itself). For state management react-atom is set. The modules management is left to the previously mentioned react-arbiter library.
On top of piral-core other packages may be placed, such as an even more opinionated version that includes a set of API extensions and standard designs (e.g., for the dashboard, error screens and more) in form of piral-ext. The long term vision is to not only provide some layouts to choose from, but also to have plugins that may be helpful for the portal layer (e.g., provide PWA capabilities, authentication providers, …).
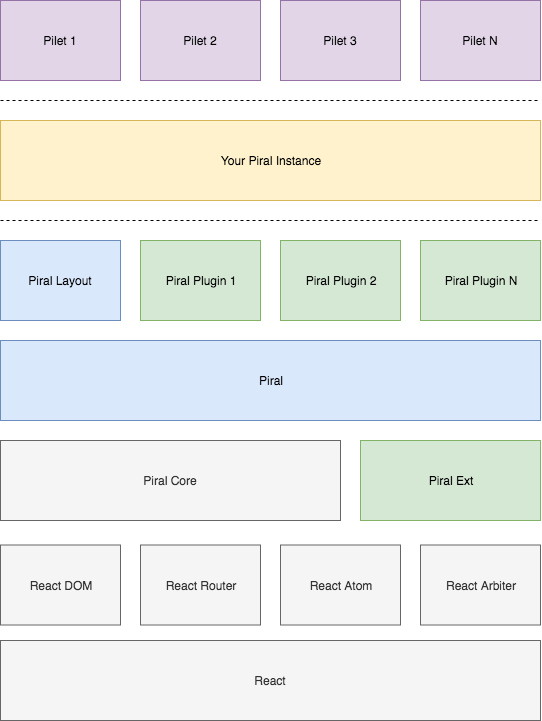
With Piral we are reduced to either take (or create) a standard template or to just roll out our own design for the page. This is as simple as writing something like this:
import * as React from 'react';
import { render } from 'react-dom';
import { createInstance } from 'piral-core';
const App = createInstance({
requestModules: () => fetch('https://feed.piral.io/sample'),
});
const Layout = props => (
// ...
);
render((
<App>
{content => <Layout>{content}</Layout>}
</App>
), document.querySelector('#app'));
Where Layout is a layout component created by us. For any serious implementation, we need to have a proper module feed such as the sample feed seen above. Piral calls these modules pilets.
Using the given code we will end up in a loading process very close to the one shown in the following diagram:
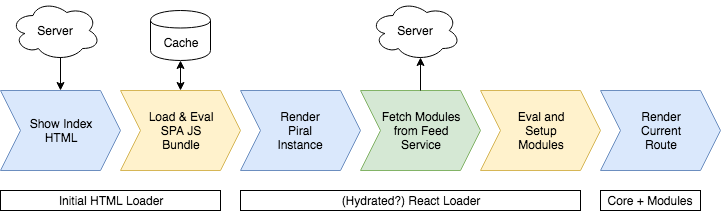
Piral allows us to hydrate the original HTML page to avoid some re-rendering. We can use this to lay out a loader rendering that is persistent between the initial HTML view and the React-based rendering (i.e., nothing will be changed or thrown away).
Besides the previously described requirements, Piral also gives us some nice concepts such as extension slots (essentially a mechanism to render/do something with content coming from one module in another module), shared data, event dispatching, and many more.
Modularizing our client is necessary to keep up with a changing back end and to distribute knowledge to multiple persons or teams efficiently. A modular front end comes with its own challenges (like deployment, tooling, debugging), which is why relying on existing tools and libraries is so important.
In the end, the idea is quite straight forward, write loosely coupled libraries that are loaded/evaluated at runtime without requiring any redeployment of the application itself.
Do you think the given approach can have benefits? Where do you see it shine, what would you make different? Tell us in the comments!
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Debug RSC hydration mismatches in production with Next.js instrumentation, Suspense isolation, HTML diffing, and CI smoke tests.

Explore why npm dependencies are a major supply chain security risk and how to protect JavaScript apps from compromised packages and transitive threats.

Enabled React Compiler v1.0 on a production Next.js app. Here’s every warning, breakage, and silent opt-out I documented — and what actually worked.

We built the same app in TanStack Start RSC and Next.js RSC. TanStack shipped 40% less JS and built 4x faster — but Next.js is still the safer production bet.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

