“Coding against interfaces, not implementations” is the practice of invoking a functionality not directly, but through a contract that enumerates the required inputs and expected outputs, as well as hides how the implementation is done. This strategy helps to decouple the application from a specific implementation, provider, or stack and enables you to swap among them without having to change the application code.

We can execute this strategy with GraphQL by using source plugins, as exemplified by Gatsby. A source plugin retrieves the required data for a specific GraphQL server, allowing us to swap the GraphQL server feeding data into the application with another one after installing a different source plugin.

The source plugin approach produces a sound and scalable architecture, but it is very time-consuming because we need to know all the ins and outs of the GraphQL server. It works well for universal applications such as Gatsby but may be overkill for our own custom applications built from scratch, which we may want to reuse for different clients who have slightly different requirements.
For this situation, there is a simpler strategy: we can use the GraphQL query as the intermediary between the application and the server and execute any needed modifications on the GraphQL queries only, keeping the business logic untouched.
In this article, we will explore this approach.
A GraphQL query acts as an interface between the client and the server. When executing a query, the GraphQL server will process it and return the required data to the client. But where does the data come from? How was it obtained? The client doesn’t know and doesn’t care.
The response to the query will have the same shape as the query. For this GraphQL query:
{
post(id: 1) {
id
title
}
}
…the response will be:
{
"data": {
"post": {
"id": 1,
"title": "Hello world!"
}
}
}
Given the same query with different parameters, the returned data will be different, but the shape will be constant. This means that as long as the query doesn’t change, the application does not need to change the logic it uses to read and process the data.
The GraphQL query can then assume the role of the source plugin, and serve as the intermediary between the application and the GraphQL server. As long as the query doesn’t change, it doesn’t matter which GraphQL server is executing the query, and we can seamlessly swap one GraphQL server with another one.
Now, the last paragraph is a bit too hopeful, because the GraphQL query may need to change depending on the GraphQL server. To be more precise, the query is based on the GraphQL schema, and if different servers expose different schemas, then the queries will be different too.
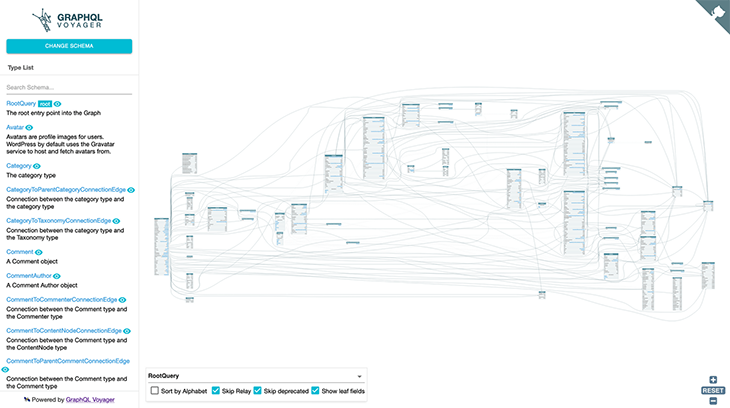
Consider how the two GraphQL servers for WordPress expose the data model for the CMS. This image shows the GraphQL schema by WPGraphQL:
This other image shows the GraphQL schema by the GraphQL API for WordPress:
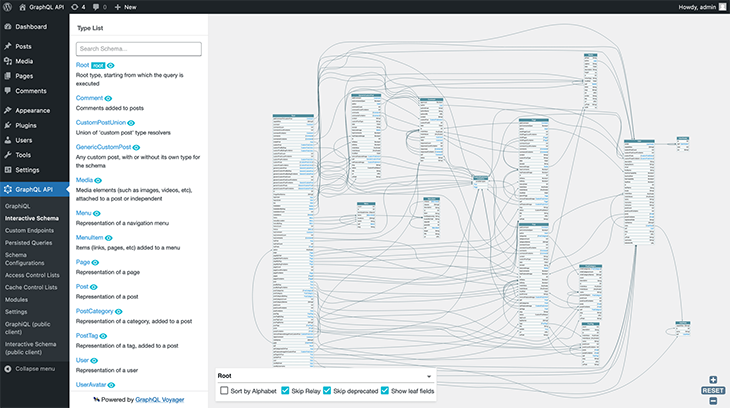
In these two schemas, the same fields have different names and different types are exposed, partly because WPGraphQL uses the GraphQL Cursor Connections Specification, but the GraphQL API for WP does not. As a result, a query that works in WPGraphQL will most likely not work in the GraphQL API for WP, and vice versa.
For instance, the WPGraphQL-based Next.js WordPress starter contains this query:
{
categories(first: 10000) {
edges {
node {
categoryId
description
id
name
slug
}
}
}
}
The equivalent query that works for the GraphQL API for WP is this one:
{
postCategories(limit: 10000) {
id
description
globalID
name
slug
}
}
We can appreciate the differences between the two queries:

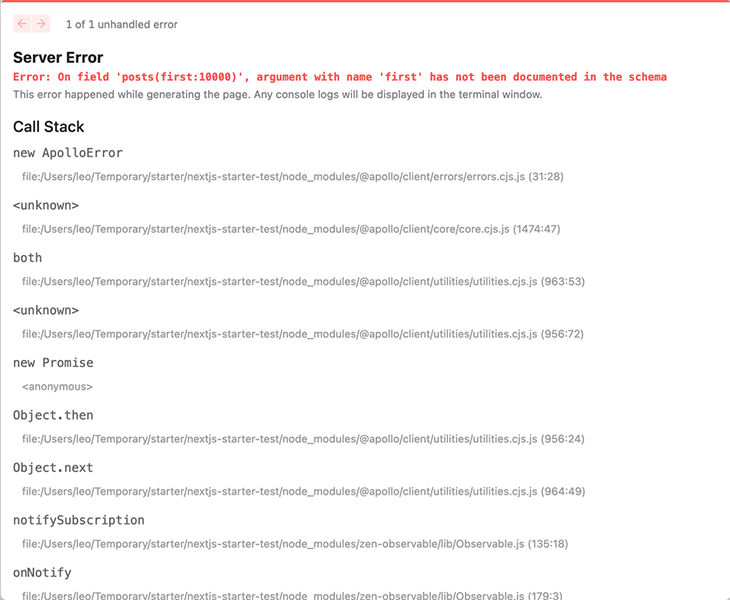
Replacing the WPGraphQL query in the Next.js WordPress starter with the equivalent one from the GraphQL API for WP will not work on its own. That’s because the logic will still access the data from the response according to the shape and fields from the original query. Running the starter unsurprisingly fails:
One possible solution is to also replace the logic used to retrieve the data. For instance, the following logic:
const categories = data?.data.categories.edges.map(({ node = {} }) => node);
…can be replaced like this:
const categories = data?.data.postCategories;
But that is exactly what we want to avoid. We want to keep the changes to the bare minimum, modifying only the GraphQL query “interface,” and keeping the business logic unmodified.
Fortunately, it is possible to bridge these differences by modifying the GraphQL queries only, following these steps:
self fieldLet’s see how, via these three steps, the Next.js WordPress starter can be made to work with the GraphQL API for WP.
Detaching the GraphQL queries from the application logic involves:
The Next.js WordPress starter already has such a layout in place. All queries are placed on separate files under src/data (with a few exceptions), and they are exported:
export const QUERY_ALL_CATEGORIES = gql`
{
categories(first: 10000) {
edges {
node {
databaseId
description
id
name
slug
}
}
}
}
`;
The application can then import and use the GraphQL query:
import { QUERY_ALL_CATEGORIES } from 'data/categories';
export async function getAllCategories() {
const apolloClient = getApolloClient();
const data = await apolloClient.query({
query: QUERY_ALL_CATEGORIES,
});
const categories = data?.data.categories.edges.map(({ node = {} }) => node);
return {
categories,
};
}
Thanks to this setup, all the modifications must only be carried out on the files under src/data.
A field alias can be used to rename a field in the response to the one exposed by the WPGraphQL schema.
This way, fields postCategories, id, and globalID can be retrieved using the names expected by the application: categories, categoryId, and id respectively:
{
categories: postCategories(limit: 10000) {
categoryId: id
description
id: globalID
name
slug
}
}
Please notice that field categories in WPGraphQL has the argument first, while its corresponding field postCategories uses the argument limit. However, because the field arguments are not reflected in the name of the field in the response, we do not need to worry about them.
self fieldThe final challenge is a bit trickier: we need to modify the shape of the response, appending the extra levels for edges and node coming from the Cursor Connections spec.
To achieve this, we will introduce a self field to all types in the GraphQL schema, which echoes the object where it is applied:
type QueryRoot {
self: QueryRoot!
}
type Post {
self: Post!
}
type User {
self: User!
}
The self field allows you to append extra levels to the query without leaving the queried object. Running this query:
{
__typename
self {
__typename
}
post(id: 1) {
self {
id
__typename
}
}
user(id: 1) {
self {
id
__typename
}
}
}
…produces this response:
{
"data": {
"__typename": "QueryRoot",
"self": {
"__typename": "QueryRoot"
},
"post": {
"self": {
"id": 1,
"__typename": "Post"
}
},
"user": {
"self": {
"id": 1,
"__typename": "User"
}
}
}
}
Now, we can use self to artificially append the node and edges levels:
{
categories: self {
edges: postCategories(limit: 10000) {
node: self {
categoryId: id
description
id: globalID
name
slug
}
}
}
}
The type of the object in the GraphQL schema for edges and for self is obviously different. But that doesn’t matter to the application because it doesn’t interact with the actual object modeled in the GraphQL server.
Instead, it receives the data as a JSON object, and that piece of data for a field coming from either a PostConnection or a Post object will be the same.
Please notice that the categories field is resolved via self, and edges is resolved via postCategories — and not the other way around. This is to ensure the cardinality of the returned elements matches the one defined by the WPGraphQL schema:
type RootQuery {
categories: RootQueryToCategoryConnection
}
type RootQueryToCategoryConnection {
edges: [RootQueryToCategoryConnectionEdge]
}
type RootQueryToCategoryConnectionEdge {
node: Category
}
If the adapted GraphQL query were the other way around (i.e., querying categories: postCategories and edges: self), accessing the data would fail, because data.categories would be an array, so data.categories.edges would throw an error when executing:
const categories = data?.data.categories.edges.map(({ node = {} }) => node);
This is the final adapted query that works with the GraphQL API for WP:
{
categories: self {
edges: postCategories(limit: 10000) {
node: self {
databaseId: id
description
id
name
slug
}
}
}
}
After applying the same strategy to all the GraphQL queries in src/data, running the starter against the GraphQL API for WP endpoint works perfectly:
In this article, we explored how an application that relies on a specific GraphQL server can be adapted to use a different GraphQL server, with the least amount of effort.
The solution involves making the GraphQL query the intermediary between the application and the server, and carrying out all required changes on the queries only, as to avoid modifying the business logic.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

