When you think about Node.js, XML probably isn’t the first thing that comes to mind. But there are cases where you may find you need to read or write XML from a Node.js application. It is no coincidence that a search for “XML” on npm returns 3,400+ results; there is a considerable collection of XML-related packages that specialize in different ways of working with XML.

In this article, we will explore some real-world XML use cases using some of the most popular npm packages available, including:
Note that the code examples in this article are for demonstration purposes. Elaborate, working sample code is available at briandesousa/node-xml-demo.
If you want to follow along with the instructions in this article, you may want to start by generating an Express app with express-generator. Select the Pug view engine (view code examples are written as Pug templates).
XML-RPC and SOAP web services used to be the standard for exchanging data between applications, but JSON APIs (i.e., REST, GraphQL) have all but dethroned XML services.
Be that as it may, there are still cases where you might need to expose an XML-based API to allow other applications to feed XML data into your application. Luckily, there are plenty of packages on npm that make it easy to consume XML data.
One of the more popular XML packages is xml2js, and one of the more popular application frameworks for Node.js is Express. Naturally, there is an Express middleware package, express-xml-bodyparser, that ties these two together. Let’s build an Express route that can receive XML.
First, we need to install the express-xml-bodyparser package:
npm install express-xml-bodyparser
Then add the express-xml-bodyparser middleware to the Express app. By default, the middleware will parse any incoming requests where if the request’s Content-Type header is set to text/xml.
// app.js
var express = require('express');
var xmlparser = require('express-xml-bodyparser');
var app = express();
app.use(xmlparser());
// other Express middleware and configurations
Add a /xml2js/customer route that receives an XML request:
// routes/xml2js.js
router.post('/xml2js/customer', function(req, res, next) {
console.log('Raw XML: ' + req.rawBody);
console.log('Parsed XML: ' + JSON.stringify(req.body));
if (req.body.retrievecustomer) {
var id = req.body.retrievecustomer.id;
res.send(`<customer><id>${id}</id><fullName>Bob Smith</fullName></customer>`);
} else {
res.status(400).send('Unexpected XML received, missing <retrieveCustomer>');
}
});
To test our route, we can write some client-side JavaScript that sends an XML request:
// views/xml2js.pug
fetch('/xml2js/customer', {
method: 'POST',
headers: {
'Content-Type': 'text/xml'
},
body: '<retrieveCustomer><id>39399444</id></retrieveCustomer>'
})
.then(response => {
console.log('Response status: ' + response.status);
return response.text();
})
.then(responseText => console.log('Response text: ' + responseText)
.catch(error => console.log('Error caught: ' + error));
The route returns an XML response. If you take a look at the server console output, you can see the request body that the server received:
Raw XML: <retrieveCustomer><id>39399444</id></retrieveCustomer>
Parsed XML: {"retrievecustomer":{"id":["39399444"]}}
Wait a minute — do you notice something different between the raw XML that was received and the object that the express-xml-bodyparser middleware returned?
The raw XML has the retrieveCustomer XML tag in camel case, but the retrievecustomer key on the JSON object is lowercase. This is happening because the express-xml-bodyparser middleware is configuring the xml2js parser, including setting an option to convert all XML tags to lowercase.
We want the JSON object’s properties to exactly match the XML tags in the original request. Luckily, we can specify our own xml2js options and override the defaults provided by the middleware.
Modify the xmlparser middleware that was added to the Express app earlier to include a configuration object with the normalizeTags option set to false:
// app.js
app.use(xmlparser({
normalizeTags: false
}));
Rerun the client-side code and view the server console log. The tag names should now match between the raw XML and parsed JSON object:
Raw XML: <retrieveCustomer><id>39399444</id></retrieveCustomer>
Parsed XML: {"retrieveCustomer":{"id":["39399444"]}}
The xml2js package exposes several other options that allow you to customize how XML is parsed. See xml2js on npm for a full list of options.
Another common use of XML is as a format for exchanging data between different applications, sometimes between different organizations. Usually, an XML schema (XSD) is used to define the XML message structure that each application should expect to send and receive. Each application validates the incoming XML data against the schema.
The XML data may be transmitted between applications in various ways. For example, applications may receive XML over an HTTP connection or via a flat file saved to a file system over an SFTP connection.
While there are quite a few npm packages available for working with XML, the options are a little more limited when you also require XML schema validation. Let’s take a look at the libxmljs2 package, which supports XML schema validation. We will write some code to load an XML schema from the server’s file system and use it to validate some incoming XML data.
Start by creating the XML schema in a schemas directory in the root directory of your application:
<!-- schemas/session-info.xsd -->
<xs:schema attributeFormDefault="unqualified" elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="sessionInfo">
<xs:complexType>
<xs:sequence>
<xs:element type="xs:int" name="customerId"/>
<xs:element type="xs:string" name="customerName"/>
<xs:element type="xs:string" name="token"/>
</xs:sequence>
<xs:attribute type="xs:long" name="id"/>
</xs:complexType>
</xs:element>
</xs:schema>
Install the libxmljs2 package:
npm install libxmljs2
Create a new /libxmljs2/validateSessionXml route:
// routes/libxmljs2.js
var express = require('express');
var router = express.Router();
var libxmljs = require('libxmljs2');
var fs = require('fs');
var path = require('path');
var router = express.Router();
router.post('/libxmljs2/validateSessionXml', (req, res, next) => {
var xmlData = req.body;
// parse incoming XML data
var xmlDoc = libxmljs.parseXml(xmlData);
// load XML schema from file system
var xmlSchemaDoc = loadXmlSchema('session-info.xsd');
// validate XML data against schema
var validationResult = xmlDoc.validate(xmlSchemaDoc);
// return success or failure with validation errors
if (validationResult) {
res.status(200).send('validation successful');
} else {
res.status(400).send(`${xmlDoc.validationErrors}`);
}
});
function loadXmlSchema(filename) {
var schemaPath = path.join(__dirname, '..', 'schemas', filename);
var schemaText = fs.readFileSync(schemaPath, 'utf8');
return libxmljs.parseXml(xmlSchema);
}
Tip: If you are still using the express-xml-bodyparser middleware from the previous example, you may need to change line 2 to use
req.rawBodyinstead ofreq.bodyto by pass thexlm2jsand access the raw request string instead.
On line 14, libxmljs2’s parseXml() function parses the XML in the request. It returns a libxmljs.Document object, which exposes a validate() function that accepts another libxmljs.Document containing an XML schema. The validate function will return either true or a string containing a list of validation errors. On lines 23–27, we return an appropriate response based on the validation result.
The loadXmlSchema() function on line 30 loads an XML schema from the server’s file system using standard Node.js path and fs modules. Once again, we are using the parseXml() function to parse the schema file’s contents into a libxmljs.Document object. XML schemas are just XML documents at the end of the day.
Now that we have implemented a route, we can write some simple client-side JavaScript to test our route with a valid XML request:
// views/libxmljs2.pug
fetch('/libxmljs2/validateSessionXml', {
method: 'POST',
headers: { 'Content-Type': 'text/xml' },
body: `<?xml version="1.0"?>
<sessionInfo id="45664434343">
<customerId>39399444</customerId>
<customerName>Bob Smith</customerName>
<token>343ldf0bk343bz43lddd</token>
</sessionInfo>`
})
.then(response => response.text())
.then(response => console.log(response))
.catch(error => console.log('Error caught: ' + error));
// console output: validation successful
We can also send an invalid XML request and observe the validation errors that are returned:
// views/libxmljs2.pug
fetch('/libxmljs2/validateSessionXml', {
method: 'POST',
headers: { 'Content-Type': 'text/xml' },
body: `<?xml version="1.0"?>
<sessionInfo id="45664434343a">
<customerName>Bob Smith</customerName>
<token>343ldf0bk343bz43lddd</token>
</sessionInfo>`
})
.then(response => response.text())
.then(response => console.log(response))
.catch(error => console.log('Error caught: ' + error));
// console output: Error: Element 'customerName': This element is not expected. Expected is ( customerId ).
The error messages returned from libxmljs2’s validate() function are quite detailed; however, the error message format makes it difficult to parse individual error messages and map them to end user-friendly text. Other than that, there is very little code required to validate XML against a schema.
What if your application needs to manipulate HTML? Unlike the examples we covered so far, HTML is technically not compliant with the XML specification.
There are several npm packages that that specialize in dealing with the nuances of HTML compared to XML. One of those is Cheerio. Let’s take a look at how we can use Cheerio to read, manipulate, and return an HTML fragment.
Start by installing the Cheerio package:
npm install cheerio
Create a new /cheerio/highlightTable route:
// routes/cheerio.js
var cheerio = require('cheerio');
var express = require('express');
var router = express.Router();
router.post('/cheerio/highlightTable', (req, res, next) => {
// decode HTML framgent in request body
var decodedHtml = decodeURI(req.body.encodedHtml);
try {
// parse HTML fragment
var $ = cheerio.load(decodedHtml);
// use the cheerio selector to locate all table cells in the HTML
$('td').each(function() {
tableCellText = $(this).text();
tableCellNumber = parseFloat(tableCellText);
if (tableCellNumber) {
// highlight cells based on their numeric value
if (tableCellNumber >= 0) {
$(this).prop('style', 'background-color: #90ee90');
} else {
$(this).prop('style', 'background-color: #fa8072');
}
}
} catch(err) {
return res.status(500).send({ error: err});
}
// only return the HTML fragment that was received in the request
updatedHtml = $('body').html();
res.status(200).send({ encodedHtml: encodeURI(updatedHtml) });
});
On line 8, the encodedHtml request property is decoded using the built-in decodeURI function. We have to encode the HTML string when sending and receiving it within a JSON request in order to avoid special characters, like double quotes, conflicting with the JSON syntax.
On line 12, Cheerio’s load() function is used to parse the HTML fragment. This function returns a selector object with an API that is nearly identical to the jQuery core API.
The selector is then used on lines 15–25 to locate and extract the text within all table cells in the HTML fragment. The prop() function provided by the selector is used on lines 21 and 23 to modify the HTML fragment by adding new style attributes.
On line 31, the selector is used to extract the body element from the HTML fragment and return it as an HTML string. Even if the HTML fragment that was passed in the request did not contain outer <html> or <body> tags, Cheerio automatically wraps the HTML fragment into a properly structured HTML document. This happens when the load() function is called.
Finally, the HTML string is encoded and sent back to the client on line 32.
Let’s write some client-side JavaScript to test the route:
// views/cheerio.pug
var sampleHtml =
'<table border="1" cellpadding="5px" cellspacing="0">\n' +
' <tr>\n' +
' <td>Sammy Steakhouse Inc.</td>\n' +
' <td>-130.33</td>\n' +
' </tr>\n' +
' <tr>\n' +
' <td>ATM deposit</td>\n' +
' <td>500.00</td>\n' +
' </tr>\n' +
' <tr>\n' +
' <td>Government cheque deposit</td>\n' +
' <td>150.00</td>\n' +
' </tr>\n' +
'</table>';
fetch('/cheerio/highlightTable', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
encodedHtml: encodeURI(sampleHtml)
})
})
.then(response => response.json())
.then(response => {
if (response.error) {
console.log('Error received: ' + response.error);
} else {
decodedHtml = decodeURI(response.encodedHtml);
console.log('Received HTML: ' + decodedHtml);
// console output:
// <table border="1" cellpadding="5px" cellspacing="0">
// <tbody><tr>
// <td>Sammy Steakhouse Inc.</td>
// <td style="background-color: #fa8072">-130.33</td>
// </tr>
// <tr>
// <td>ATM deposit</td>
// <td style="background-color: #90ee90">500.00</td>
// </tr>
// <tr>
// <td>Government cheque deposit</td>
// <td style="background-color: #90ee90">150.00</td>
// </tr>
// </tbody></table>
}
})
.catch(error => console.log('Error caught: ' + ${error}));
On line 22, the HTML fragment is encoded using the browser’s built-in encodeURI function, similar to how we decoded it on the server side in the previous example.
You will notice a few differences between the original HTML fragment that is being sent (lines 3–16) and the modified HTML fragment that is returned (demonstrated in the comments on lines 32–46):
<tbody> were added to the HTML that was returned. These tags were automatically added by the Cheerio load() function. Cheerio is very forgiving when it comes to loading HTML: it will add additional tags to ensure the HTML is a standards-complaint HTML documentstyle attributes were added to each <td> tag as expectedThis example is a bit more visual and fun compared to the others. Let’s manipulate some SVG images by modifying their XML source code.
First, a quick primer on Scalable Vector Graphics (SVG). SVG is an XML-based image format supported by all major browsers. SVG XML is composed of a series of elements that define different types of shapes. CSS styles can be included with each shape to define its appearance. Typically you would use a tool to generate SVG XML rather than hand-code it, but given that SVG images are just XML, image manipulation via JavaScript is possible.
We are going to create a route that accepts three colors, loads an SVG image from the server’s file system, applies the colors to certain shapes in the image, and returns it to the client to be rendered. We are going to use the svgson package to convert between SVG XML and JSON to simplify the code we need to write to manipulate the image.
Start by installing the svgson package:
npm install svgson
Create a new /svgson/updateSVGImageColors route:
// routes/svgson.js
var express = require('express');
var fs = require('fs');
var path = require('path');
var {
parse: svgsonParse,
stringify: svgsonStringify
} = require('svgson')
var router = express.Router();
router.post('/svgson/updateSVGImageColors', function(req, res, next) {
// 3 colors provided to stylize the SVG image
var { color1, color2, color3 } = req.body;
// load the original SVG image from the server's file system
var svgImageXML = loadSVGImageXML('paint.svg');
// use svgson to convert the SVG XML to a JSON object
svgsonParse(svgImageXML).then(json => {
// get the shape container that contains the paths to be manipulated
gElement = json.children.find(elem => elem.name == 'g'
&& elem.attributes.id == 'g1727');
// update styles on specific path shapes
updatePathStyleById(gElement, 'path995', 'fill:#000000', 'fill:' + color1);
updatePathStyleById(gElement, 'path996', 'fill:#ffffff', 'fill:' + color2);
updatePathStyleById(gElement, 'path997', 'fill:#ffffff', 'fill:' + color3);
// convert JSON object back to SVG XML
svgImageXML = svgsonStringify(json);
// return SVG XML
res.status(200).send(svgImageXML);
});
});
function updatePathStyleById(containerElem, pathId, oldStyle, newStyle) {
pathElem = containerElem.children.find(elem => elem.attributes.id == pathId);
pathElem.attributes.style = pathElem.attributes.style.replace(oldStyle,
newStyle);
}
function loadSVGImageXML(filename) {
var svgImagePath = path.join(__dirname, '..', 'public', 'images', filename);
return fs.readFileSync(svgImagePath, 'utf8');
}
There is quite a bit going on in this code. Let’s break it down a bit and highlight a few key concepts.
On lines 5–8, the parse and stringify modules are imported from the svgson package. These module names are quite generic, but we can use object destructuring to give them more succinct names like svgsonParse and svgsonStingify.
On line 17, the loadSVGImageXML() function is used to load the contents of a predefined SVG image from the server’s file system using native Node.js modules. The image being used is paint.svg. This is what it looks like to begin with:

Lines 20–36 are where the image manipulation magic happens. The SVG XML is converted to a JSON object. Standard JavaScript is used to navigate the object tree to locate three path shapes that we want to manipulate. Here is a comparison of the JSON object tree (left-hand side) to the SVG XML (right-hand side) to help visualize it. Note that some elements have been removed for brevity.
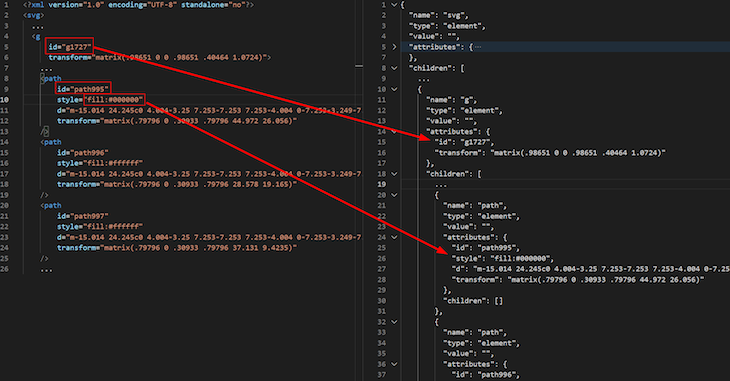
The updatePathStyleById() helper function called on lines 27–29 locates a path shape by its ID and replaces its fill style with a new fill style constructed using the colors provided in the request.
The SVG JSON object is converted back to an SVG XML string on line 32 and returned to the client on line 35.
Let’s write some client-side JavaScript to test the route:
// views/svgson.pug
fetch('/svgson/updateSVGImageColors', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
color1: '#FF0000',
color2: '#00FF00',
color3: '#0000FF'
})
})
.then(response => response.text())
.then(svgImageXml => console.log(svgImageXml))
.catch(error => console.log('Error caught: ' + error));
If we were to render the SVG XML this returned, this is what it would look like:
We covered a few common uses of XML, ranging from boring old XML-based data exchanges to SVG image manipulation. Here is a summary of the npm packages we looked at and the key features that differentiate them.
| npm package | Key features |
|---|---|
| xml2js |
|
| libxmljs2 |
|
| Cheerio |
|
| svgson |
|
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

