Editor’s note: This article was last updated by Oyinkansola Awosan on 14 August 2024 to address common errors in file downloads and their solutions, as well as security concerns that arise when downloading files.

File downloading is a core aspect of what we do on the internet. Tons of files get downloaded from the internet every day — from binary files like images, videos, and audio files, to plain text files, application files, and much more. Because of the importance of downloading files from the internet, it’s important to know how these files are downloaded, as well as the different methods for doing so.
In this article, I will demonstrate how to download files from the internet, both by enforcing the download from the website, as well as with a manual click. After that, we will review content generation in various forms, how to download the generated contents, and how the download attribute works. Lastly, we will go over the usage of blobs and object URLs:
Programmatic file downloads in the browser
Introduction – 00:00 Review of traditional client/server communication — 01:18 Programmatic content generation with HTML5 and Web APIs – 04:18 Codepen link: https://codepen.io/RealToughCandy/pen/yLNMorm Try LogRocket for free: https://logrocket.com/?yt29 LogRocket is a frontend application monitoring solution that lets you replay problems as if they happened in your own browser.
Traditionally, the file to be downloaded is first requested from a server by a client, such as a user’s web browser. The server then returns a response containing the contents of the file, as well as some instructional headers specifying how the client should download the file:
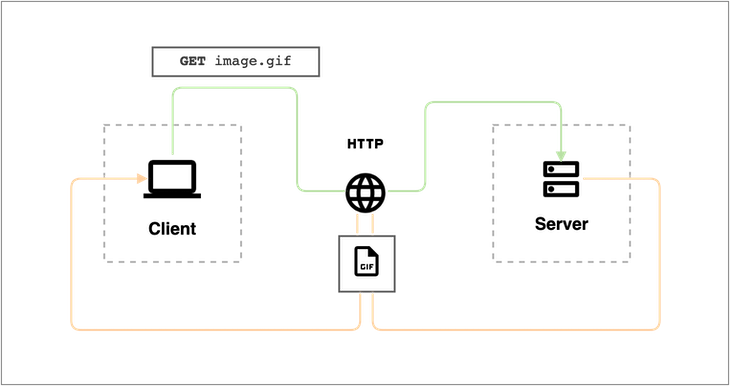
In this diagram, the green line shows the flow of the request from the client to the server over HTTP. The orange line shows the flow of the response from the server back to the client.
Though the diagram indicates the communication flow, it does not explicitly show what the request from the client looks like or what the response from the server looks like. Here is what the response from the server could possibly look like:
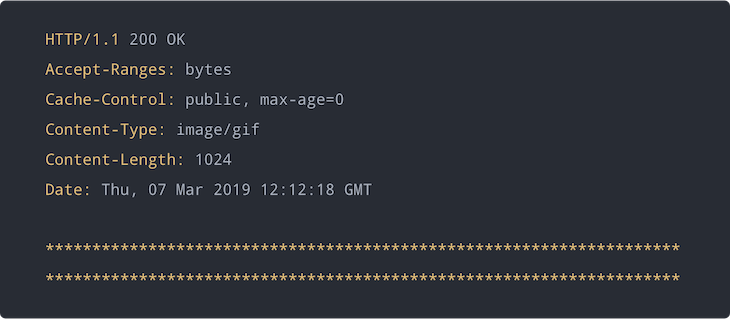
In this response, the server simply serves the raw contents of the resource (represented with the final two rows of asterisks), which the client will receive.
The response also contains headers that give the client some information about the nature of the contents that it receives. For this example response, the Content-Type and Content-Length headers provide that information.
Given the example HTTP response from above, our web browser client would simply display or render the GIF image instead of downloading it. For the purposes of this writing, we would actually want the GIF or image to be downloaded instead of displayed. For this, an extra header will be needed to tell the client to download the contents of the file automatically.
The server must include an additional header in the response to inform the client that the resource’s contents are not meant to be displayed. The Content-Disposition header is the right header for specifying this kind of information.
The Content-Disposition header was originally intended for mail user agents, because emails are multipart documents that may contain several file attachments. However, it can be interpreted by several HTTP clients, including web browsers. This header provides information on the disposition type and disposition parameters.
The disposition type is usually one of the following:
The disposition parameters are additional parameters that specify information about the body part or file, such as filename, creation date, modification date, read date, size, etc.
Here is what the HTTP response for the GIF image should look like to enforce file download:
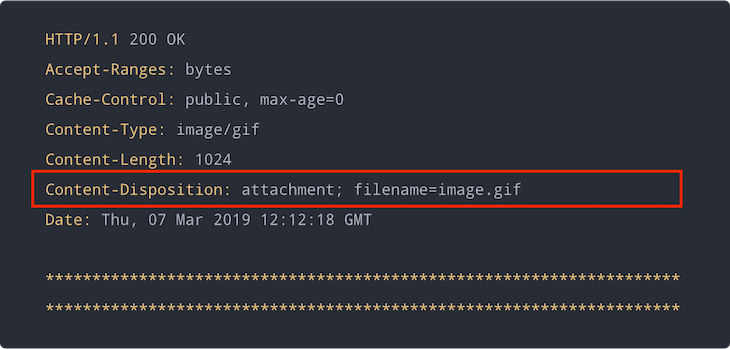
Now the server enforces a download of the GIF image. Most HTTP clients will prompt the user to download the resource contents when they receive a response from a server like the one above.
Let’s say you have the URL to a downloadable resource. When you try accessing that URL on your web browser, it prompts you to download the resource file — whatever the file is.
The scenario described above is not feasible in web applications. For web apps, the desired behavior would be more akin to downloading a file in response to a user interaction. For example, this could mean the user clicks a button that reads “Download.”
Achieving such a behavior in the browser is possible with HTML anchor elements: <a></a>. Anchor elements are useful for adding hyperlinks to other resources and documents directly from an HTML file. The URL of the linked resource is specified in the href attribute of the anchor element.
Here is an example of a conventional HTML anchor element linking to a PDF document:

download attributeIn HTML 5, a download attribute was added to the anchor element. The download attribute is used to inform the browser to download the URL instead of navigating to it — hence, a prompt shows up, requesting that the user saves the file.
The download attribute can be given a valid filename as its value. However, the user can still modify the filename in the save prompt that pops up.
There are a few noteworthy facts about the behavior of the download attribute:
blob: and data: URLs , which makes it very useful for downloading contents generated programmatically with JavaScriptContent-Disposition header that specifies a filename, the header filename has a higher priority than the value of the download attributeHere is the updated HTML anchor element for downloading the PDF document:

With the advent of HTML5 and new Web APIs, it has become possible to achieve many complex tasks in the browser using JavaScript without ever having to communicate with a server.
There are now Web APIs that can be used to programmatically:
In this section, we will examine how we can programmatically generate content using Web APIs on the browser. Let’s consider two common examples.
In this example, we will use the Fetch API to asynchronously fetch JSON data from a web service and transform the data to form a string of comma-separated values that can be written to a CSV file. Here is a breakdown of what we are about to do:
Here is what the CSV generation script can look like:
function squareImages({ width = 1, height = width } = {}) {
return width / height === 1;
}
function collectionToCSV(keys = []) {
return (collection = []) => {
const headers = keys.map(key => `"${key}"`).join(',');
const extractKeyValues = record => keys.map(key => `"${record[key]}"`).join(',');
return collection.reduce((csv, record) => {
return (`${csv}\n${extractKeyValues(record)}`).trim();
}, headers);
}
}
const exportFields = [ 'id', 'author', 'filename', 'format', 'width', 'height' ];
fetch('https://picsum.photos/list')
.then(response => response.json())
.then(data => data.filter(squareImages))
.then(collectionToCSV(exportFields))
.then(console.log, console.error);
Here, we are fetching a collection of photos from the Picsum Photos API. We are using the global fetch() function provided by the Fetch API, filtering the collection, and converting the collection array to a CSV string. The code snippet simply logs the resulting CSV string to the console.
First, we define a squareImages filter function for filtering images in the collection with equal width and height.
Next, we define a collectionToCSV higher-order function. This takes an array of keys and returns a function that takes an array collection of objects and converts it to a CSV string, extracting only the specified keys from each object.
Finally, we specify the fields we want to extract from each photo object in the collection in the exportFields array.
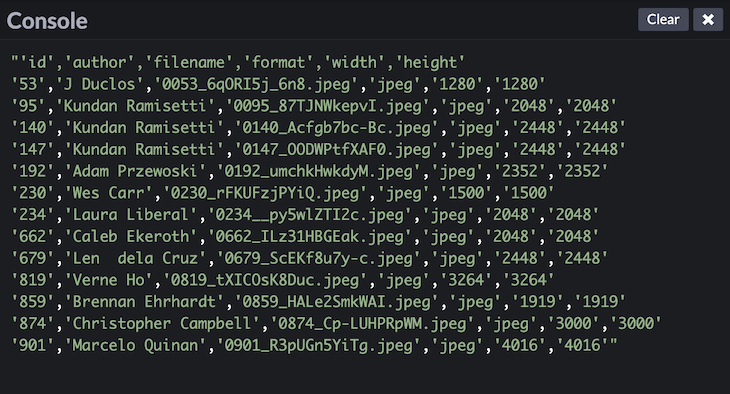
Here is what the output could look like on the console:
In this example, we will use the Canvas API to manipulate the pixels of an image, making it appear in grayscale. Here is a breakdown of what we are about to do:
Let’s say we have a markup that looks like this:
<div id="image-wrapper"> <canvas></canvas> <img src="https://example.com/imgs/random.jpg" alt="Random Image"> </div>
Here is what the image manipulation script could look like:
const wrapper = document.getElementById('image-wrapper');
const img = wrapper.querySelector('img');
const canvas = wrapper.querySelector('canvas');
img.addEventListener('load', () => {
canvas.width = img.width;
canvas.height = img.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0, width, height);
const imageData = ctx.getImageData(0, 0, width, height);
const data = imageData.data;
for (let i = 0, len = data.length; i < len; i += 4) {
const avg = (data[i] + data[i + 1] + data[i + 2]) / 3;
data[i] = avg; // red
data[i + 1] = avg; // green
data[i + 2] = avg; // blue
}
ctx.putImageData(imageData, 0, 0);
}, false);
Below is a comparison between an actual image and the corresponding grayscale canvas image:

Before we learn how we can download content generated programmatically in the browser, let’s look at a special kind of object interface called Blob, which has already been implemented by most major web browsers.
Blobs are objects that are used to represent raw immutable data. Blob objects store information about the type and size of the data they contain, making them very useful for storing and working with file contents on the browser. In fact, the File object is a special extension of the Blob interface.
Blob objects can be obtained from a few different sources. They can be:
Blob constructorBlob.slice() methodHere are some code samples for the aforementioned blob object sources:
const data = {
name: 'Glad Chinda',
country: 'Nigeria',
role: 'Web Developer'
};
// SOURCE 1:
// Creating a blob object from non-blob data using the Blob constructor
const blob = new Blob([ JSON.stringify(data) ], { type: 'application/json' });
const paragraphs = [
'First paragraph.\r\n',
'Second paragraph.\r\n',
'Third paragraph.'
];
const blob = new Blob(paragraphs, { type: 'text/plain' });
// SOURCE 2:
// Creating a new blob by slicing part of an already existing blob object
const slicedBlob = blob.slice(0, 100);
// SOURCE 3:
// Generating a blob object from a Web API like the Fetch API
// Notice that Response.blob() returns a promise that is fulfilled with a blob object
fetch('https://picsum.photos/id/6/100')
.then(response => response.blob())
.then(blob => {
// use blob here...
});
It is one thing to obtain a blob object and another thing altogether to work with it. One thing you want to be able to do is to read the contents of the blob. That sounds like a good opportunity to use a FileReader object.
A FileReader object provides some helpful methods for asynchronously reading the contents of blob objects or files in different ways. The FileReader interface has pretty good browser support. At the time of writing, FileReader supports reading blob data as follows:
FileReader.readAsText()FileReader.readAsBinaryString()FileReader.readAsDataURL()FileReader.readAsArrayBuffer()Building on the Fetch API example we had before, we can use a FileReader object to read the blob as follows:
fetch('https://picsum.photos/id/6/240')
.then(response => response.blob())
.then(blob => {
// Create a new FileReader innstance
const reader = new FileReader;
// Add a listener to handle successful reading of the blob
reader.addEventListener('load', () => {
const image = new Image;
// Set the src attribute of the image to be the resulting data URL
// obtained after reading the content of the blob
image.src = reader.result;
document.body.appendChild(image);
});
// Start reading the content of the blob
// The result should be a base64 data URL
reader.readAsDataURL(blob);
});
The URL interface allows for the creation of special kinds of URLs called object URLs, which are used for representing blob objects or files in a very concise format. Here is what a typical object URL looks like:
blob:https://cdpn.io/de82a84f-35e8-499d-88c7-1a4ed64402eb
The URL.createObjectURL() static method makes it possible to create an object URL that represents a blob object or file. It takes a blob object as its argument and returns a DOMString, which is the URL representing the passed blob object. Here is what it looks like:
const url = URL.createObjectURL(blob);
It is important to note that this method will always return a new object URL each time it is called, even if it is called with the same blob object.
Whenever an object URL is created, it stays around for the lifetime of the document on which it was created. Usually, the browser will release all object URLs when the document is being unloaded. However, it is important that you release object URLs whenever they are no longer needed in order to improve performance and minimize memory usage.
The URL.revokeObjectURL() static method can be used to release an object URL. It takes the object URL to be released as its argument. Here is what it looks like:
const url = URL.createObjectURL(blob); URL.revokeObjectURL(url);
Object URLs can be used wherever a URL can be supplied programmatically. For example:
src property of an Image elementhref attribute of an <a></a> element, making it possible to download content that was extracted or generated programmaticallySo far, we have looked at how we can download files that are served from a server and sent to the client over HTTP , which is essentially the traditional flow. We have also seen how we can programmatically extract or generate content in the browser using Web APIs.
In this section, we will examine how we can download programmatically generated content in the browser, leveraging all we have learned from the beginning of the article and what we already know about blobs and object URLs.
First, let’s say we have a blob object by some means. We want to create a helper function that allows us to create a download link (<a></a> element) that can be clicked in order to download the contents of the blob, just like a regular file download.
The logic of our helper function can be broken down as follows:
<a></a>)href attribute of the anchor element to the created object URLdownload attribute to the filename of the file to be downloaded. This forces the anchor element to trigger a file download when it is clickedHere is what an implementation of this helper function will look like:
function downloadBlob(blob, filename) {
// Create an object URL for the blob object
const url = URL.createObjectURL(blob);
// Create a new anchor element
const a = document.createElement('a');
// Set the href and download attributes for the anchor element
// You can optionally set other attributes like `title`, etc
// Especially, if the anchor element will be attached to the DOM
a.href = url;
a.download = filename || 'download';
// Click handler that releases the object URL after the element has been clicked
// This is required for one-off downloads of the blob content
const clickHandler = () => {
setTimeout(() => {
URL.revokeObjectURL(url);
removeEventListener('click', clickHandler);
}, 150);
};
// Add the click event listener on the anchor element
// Comment out this line if you don't want a one-off download of the blob content
a.addEventListener('click', clickHandler, false);
// Programmatically trigger a click on the anchor element
// Useful if you want the download to happen automatically
// Without attaching the anchor element to the DOM
// Comment out this line if you don't want an automatic download of the blob content
//a.click();
// Return the anchor element
// Useful if you want a reference to the element
// in order to attach it to the DOM or use it in some other way
return a;
}
Notice that the helper function contains a function call that is commented out. This function may trigger an automatic download if we want to force the download of the file as soon as you access the website. In order to force the file download to happen automatically, uncomment from the script above to achieve that.
Also notice that the helper function takes a filename as its second argument, which is very useful for setting the default filename for the downloaded file.
The helper function returns a reference to the created anchor element (<a></a>), which is very useful if you want to attach it to the DOM or use it in some other way.
Here is a simple example:
// Blob object for the content to be download
const blob = new Blob(
[ /* CSV string content here */ ],
{ type: 'text/csv' }
);
// Create a download link for the blob content
const downloadLink = downloadBlob(blob, 'records.csv');
// Set the title and classnames of the link
downloadLink.title = 'Export Records as CSV';
downloadLink.classList.add('btn-link', 'download-link');
// Set the text content of the download link
downloadLink.textContent = 'Export Records';
// Attach the link to the DOM
document.body.appendChild(downloadLink);
Now that we have our download helper function in place, we can revisit our previous examples and modify them to trigger a download for the generated contents.
We will update the final promise .then handler to create a download link for the generated CSV string and automatically click it to trigger a file download using the downloadBlob helper function we created in the previous section.
Here is what the modification should look like:
fetch('https://picsum.photos/list')
.then(response => response.json())
.then(data => data.filter(squareImages))
.then(collectionToCSV(exportFields))
.then(csv => {
const blob = new Blob([csv], { type: 'text/csv' });
downloadBlob(blob, 'photos.csv');
})
.catch(console.error);
Here, we updated the final promise .then handler as follows. First, we created a new blob object for the CSV string, setting the correct type using this:
{ type: 'text/csv' }
Then, we call the downloadBlob helper function to trigger an automatic download for the CSV file, specifying the default filename as “photos.csv”. Next, we move the promise rejection handler to a separate .catch() block:
.catch(console.error)
Here is a working and more advanced example of this application on Codepen:
See the Pen
JSON Collection to CSV by Glad Chinda (@gladchinda)
on CodePen.
We will add some code to the end of the load event listener of the img object to:
canvas using the Canvas.toBlob() methoddownloadBlob helper function from beforeHere is what the update should look like:
img.addEventListener('load', () => {
/* ... some code have been truncated here ... */
ctx.putImageData(imageData, 0, 0);
// Canvas.toBlob() creates a blob object representing the image contained in the canvas
// It takes a callback function as its argument whose first parameter is the
canvas.toBlob(blob => {
// Create a download link for the blob object
// containing the grayscale image
const downloadLink = downloadBlob(blob);
// Set the title and classnames of the link
downloadLink.title = 'Download Grayscale Photo';
downloadLink.classList.add('btn-link', 'download-link');
// Set the visible text content of the download link
downloadLink.textContent = 'Download Grayscale';
// Attach the link to the DOM
document.body.appendChild(downloadLink);
});
}, false);
Here is a working example of this application on CodePen:
See the Pen
Image Pixel Manipulation — Grayscale by Glad Chinda (@gladchinda)
on CodePen.
Errors are quite common when downloading files, and they occur for various reasons. In this section, we will explore some common errors and their solutions.
Network failures happen often, even beyond file downloads. They could be caused by a bad connection or simply, a really slow network, which then causes downloads to fail or become slow.
The solution to this is to set up a retry mechanism with exponential backoff. This will handle temporary network issues or errors and enable the download to continue after any interruption happens.
An incomplete download may occur for many reasons, including insufficient space if the file size is large or if the file is corrupted.
In order to handle incomplete downloads:
A Cross-Origin Resource Sharing (CORS) error typically occurs when the server hosting the file cannot allow requests from your domain. This is typically a security feature, but it could also be due to an incorrect or missing CORS header.
While workarounds like using a proxy server or browser extensions can work, they don’t exactly solve the problem. In fact, these workarounds have some security risks and limitations. More often than not, the website’s owner(s) must implement a permanent and proper solution.
Read more about implementing CORS here.
Also known as XSS, cross-site scripting is a security vulnerability in which an attacker adds or injects malicious scripts or executable code. Different types of XSS attacks affect different parts of a website. XSS can occur in programmatic file downloads if a download link or file contents are dynamically generated based on user input.
The solution to this security risk is to:
Man-in-the-middle attacks are fairly common and can happen when programmatically downloading files, particularly if certain security measures are not taken. In this type of attack, an attacker could intercept the download request or data during download, thus exposing possibly sensitive information. The attacker could also change the expected response/file with a malicious one, putting security at risk.
To avoid these attacks:
This tutorial explored the basics of the client-server relationship and how the former requests a file from the latter to download files using HTML. We also generated our own content and explored blobs and object URLs.
The importance of downloading files through the internet browser or a web application remains a central topic of web development in general. This is why it is crucial to understand the different methods of downloading while keeping in mind some of the security risks and issues you may encounter.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
This guide explores how to use Anthropic’s Claude 4 models, including Opus 4 and Sonnet 4, to build AI-powered applications.

Which AI frontend dev tool reigns supreme in July 2025? Check out our power rankings and use our interactive comparison tool to find out.

Learn how OpenAPI can automate API client generation to save time, reduce bugs, and streamline how your frontend app talks to backend APIs.

Discover how the Interface Segregation Principle (ISP) keeps your code lean, modular, and maintainable using real-world analogies and practical examples.



5 Replies to "Programmatically downloading files in the browser"
This is so great yet practical
Awesome article — this technique is total magic.
Hello. Great article! One comment though: in the function `downloadBlob` you declare a `clickHandler` that gets a value of an arrow function, which uses the `this` keyword. Since arrow functions do not have `this`, and you use `this` in a `setTimeout` callback function — it ends up being `undefined`, which throws when you perform the `.` operator on it (to call the `removeEventListener` method).
Thanks for the article!
Eran
Hi Eran, thanks for pointing that out. That was an error on my part.
The `clickHandler` function is supposed to be a regular JS function as opposed to an arrow function — that way, it would have the correct `this` binding internally (the target element) when it is eventually used as an event listener callback. If you notice in the subsequent Codepen snippets, you’d observe that the `clickHandler` function was defined as a regular function instead of as an arrow function.
Thanks again for spotting that out.
Good work