Chances are, your sales or marketing team asks you about how to set up a “single source of truth” for customer data at least once a quarter. In your product organization, you’re probably using a tool specifically built for product analytics.

So why doesn’t your sales and marketing team consider your product analytics tools a single source of truth? Well, it’s because analytics tools alone simply can’t do that. We’ll dive into this and more in the post below.
So what exactly is a “single source of truth” for customer data? The simplest way to explain it is that it’s the place you go to that stores ALL the data about your customers. This includes product analytics of course, but also includes CRM data, billing data, and much more. All of this data is probably collected and stored in different places, which means that it’s hard for different teams to access data that they don’t own.
For example, as a product manager, you likely have access to LogRocket, but not to Salesforce. If you’re trying to prioritize product feature usage based on the value of a given customer to the company, how will you do that if the data isn’t stored in the same place? You’ll end up having to ask someone with access to your CRM to export data about how much a customer spends on your product and do some magic to join it with data you export from your product analytics tools.
This is where a single source of truth comes in. Data may be collected in different places, but it’s ultimately piped into one place where multiple tools can access it. This data can be used by many teams to make business decisions. A single source of truth doesn’t typically include data that lives solely in the product and engineering arena, like data that actually powers the application or software you’re building.
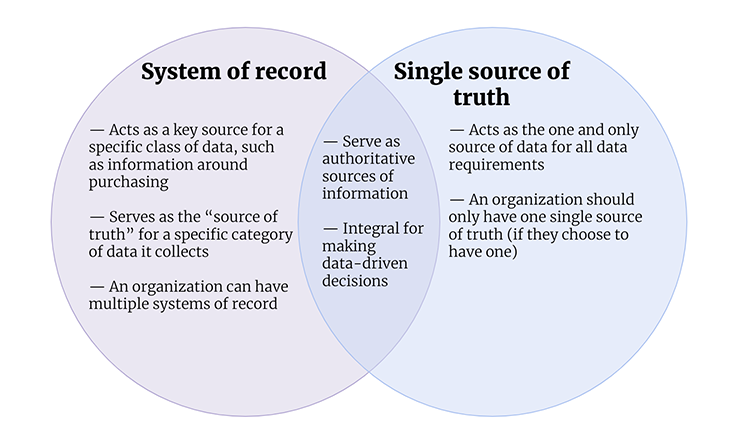
It’s important to note that a single source of truth is not just a carbon copy of data from different sources. It also must aggregate the data in a way that combines data from different sources. If we don’t aggregate data, we’re not really that far off from the data silos created by multiple data sources (or systems of record). Although all the data is now in the same place, product managers still need to figure out the CRM schema and data model to combine that data with product analytics data. So the act of aggregating data from multiple systems of record is what separates a single source of truth from a system of record.
You’re probably wondering what a system of record is at this point, as we’ve been skirting the topic a bit. To explain that, let’s sidetrack briefly to talk about our favorite poster child for systems of record — Salesforce.
When Salesforce came out and completely took over the CRM world, they messaged themselves as the “system of record” for customer data. A system of record is essentially a place where data is collected and stored. It’s the “source of truth” for the class of data it collects — in Salesforce’s case, it collected all sorts of data about customers, whether it was prospects, paying customers, or churned customers for the sales organization. It was the “system of record” and “source of truth” for deal data, ongoing opportunities, and sales activities.
The primary source of collecting this kind of data was via sales reps — of course today, there are a lot of tools that pipe different data automatically into Salesforce, but sales reps manually typing in and updating data is still a key input of data.
Fast forward to now, customer data is being generated not just by sales reps, but also by the actual products being offered to customers. For example, free users of Dropbox are uploading files, sharing files, and downloading files. All of that data is technically customer data as it describes how a potential customer is interacting with your company via the product. This is obviously largely driven by SaaS and the explosion of Web 2.0, where user behavior can be tracked and sent back to “systems of record” for product usage and web traffic.
What you end up with is multiple systems of record that, as mentioned before, collect a certain class of data and store it. You’ll have your product analytics system of record (for example, a CDP like Segment), you’ll have other usage metrics tracked in your own proprietary databases (for example, API calls that aren’t sent to Segment), you’ll have web traffic tracked in Google Analytics, you’ll have billing data stored in a platform like Stripe, customer data stored in Salesforce, more customer data stored in HubSpot or Marketo, and you can see how now you have an uncontrollable number of systems of records with invaluable data.
In summary, the difference between a system of record and a single source of truth is that while there may be many systems of record within an organization, each housing a specific type of data, a single source of truth would consolidate all this information into one universally recognized and trusted source:
In some cases, the data stored in these systems is actually repetitive. An example of when this happens is when companies use both Salesforce and HubSpot. Although HubSpot started out as a marketing solution, it also offers a CRM because most companies want to leverage data in their CRM to send out marketing campaigns. Many companies who adopt Salesforce because of how robust the platform is for sales end up literally syncing HubSpot with Salesforce via bi-directional sync so that both systems look exactly the same.
Now imagine if a marketing person updates a contact in HubSpot at the same time that a sales rep updates the very same contact in Salesforce. You can see how Salesforce is a data silo and has its own version of data, while HubSpot is a data silo with its own version. The two systems may talk to each other, but there is no guarantee which one is actually correct, and trying to ensure correctness is quite literally impossible.
A single source of truth for all this data is a completely different animal than a system of record. It requires you to combine all the data, map it cohesively, and then store it in a single place. A single source of truth for your CRM data would then require you to essentially choose which system to trust and map that data to other systems. For example, for repetitive fields that live in Salesforce and HubSpot, you might choose to use Salesforce as your source of truth. Then, you use domain names or emails to join contacts and companies across the two systems in cases where HubSpot stores data that Salesforce doesn’t have.
You can see how a single source of truth requires you to map data and aggregate it. There are a ton of technical complexities with how to do this accurately. There are also a ton of operational complexities related to how data is modeled so that it can actually be used by the company. Suffice to say that a single source of truth is a combination of many systems of record.
We discussed what a single source of truth is and why it’s different from a system of record, but what does it tactically look like? Before we dig in on the technologies people use today, let’s talk about what a single source of truth needs to be able to do.
First, it needs to be able to store many types of data — product usage data, website traffic data, CRM data, and much more. In fact, some companies even throw support tickets and community engagement metrics in their single sources of truth.
Second, it needs to be easily accessible across the entire company. And third, it needs to be easy to integrate with multiple systems so that data can feasibly be piped from a system of record into a single source of truth.
All of these requirements are well met by cloud data warehouses, and it is for this reason that most companies consider a cloud data warehouse as their single source of truth. Common solutions include Snowflake, Redshift, and BigQuery. These solutions are provided in the cloud by large vendors, speak SQL (which is easy to access and integrate with), and are compatible with most tools in the market.
In addition to a cloud data warehouse, many companies opt to use a platform to help them build out data models that can be used across the organization — dbt is a well-adopted tool in this space. If you’re wondering how to get data in a cloud data warehouse in the first place, there are many ETL tools that can help there. Fivetran is a popular one that people use to pipe data from applications into cloud data warehouses.
But how can you ensure that your single source of truth is easily accessible to everyone who needs it? There are several layers to this. First, you might want to simply make the data in your source of truth available in downstream applications. Reverse ETL is a newer field of tools that exist for this reason — Hightouch and Census are big players here. Second, you might want to make the actual raw data explorable so that different teams can query and analyze this data on their own. Business intelligence tools like Mode, Looker, and Tableau are common options here.
By combining all these tools, you end up with a data stack that enables you to get closer to a single source of truth. This stack combines data from multiple sources, aggregates it, models it, and then exposes this modeled data back to the entire organization. But this sounds like a lot of work doesn’t it?
Now that we know what a single source of truth is, and understand how powerful it is to have one, why doesn’t everyone do this? Well, it’s actually quite difficult to get this right:
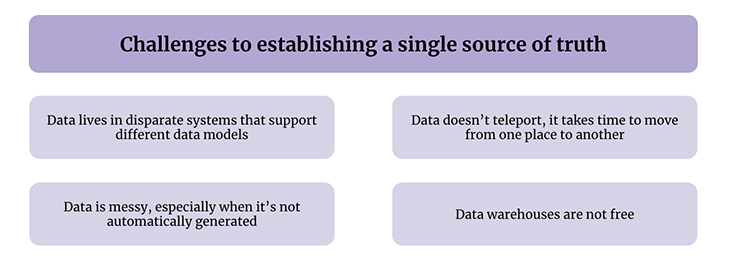
First of all, as we discussed earlier, data typically lives in systems of records prior to being piped into a single source of truth. These systems of record are where the data is generated, and often have their own opinionated data models that enable them to provide a best-in-class viewing experience for their users.
Data models describe how data is stored in the platform. For example, Salesforce is considered a system of record for customer data built for the sales persona. Their data model includes accounts, contacts, leads, and opportunities. LogRocket is a system of record for event data — covering product usage events and website views. Their data model includes users and events, with additional customizations. When you build a single source of truth, you have to figure out how to meld these models together.
Many companies start with mirroring (a technical term for copying) data sets from systems of records into data warehouses as tables, but you ultimately need to figure out how you want to join things. Do you want to use emails or a unique ID? How do you handle duplicate accounts in Salesforce? What happens if a user exists in LogRocket but not in Salesforce? How will you merge that data then? These are just some of the many questions that you need to deal with.
On top of this is the question of data ownership. Different teams own the different systems of records that you are trying to combine, and they might have used workarounds to make their systems work for them that you now need to transfer over to match how the entire company works. For example, your sales team might not have wanted to add another “sales” stage, so they put all prospects in the “prospect” bucket even if some are already qualified leads but are “cold.”
Or perhaps in your product analytics system, you only track feature usage when someone clicks a button, but not when they hit the API for the same exact feature. As you transfer data from one place to another, this transfer of ownership will ultimately result in a mess of data if you’re not careful.
Another challenge is that it takes time to pipe data from a system of record into a single source of truth. Different systems have different limitations — some don’t allow bulk exports and others limit how often you can do an export. So data that was collected at a point in time will land in your data warehouse later than you might expect. This causes issues for people who consume data from your single source of truth because the query results may be delayed or out of sync.
You have to make sure that you’re using the timestamp of the data itself, not when it landed in your data warehouse. For example, let’s say your sign-in events are near real-time, but your Salesforce data only uploads once a week. You’ll see that customers are using premium paid features even when the customer status field is unpaid. This causes confusion and diminishes the trust that your team has in the data.
To further complicate things, data can be extremely messy when it comes from systems of record, particularly those that collect data through human intervention. Again returning to Salesforce, opportunities are often updated manually as your sales reps work deals. Accounts are created by hand when sales reps reach out. This results in duplicate entries that are hard to de-duplicate at the data warehouse level.
Obviously, you need to pay for a cloud data warehouse, but on top of it, you need a team to manage it. The data stored in a cloud data warehouse is incredibly important, so you’ll need a team to ensure that it’s not only correct and aggregated correctly, but that permissions are appropriately set up. If you look through all the things you have to do to create a single source of truth, you’ll realize that it’s truly a company-wide commitment, not just something you can accomplish within a week or two.
The issues discussed above might seem insurmountable, but the benefits of building out a single source of truth are well worth it. Your entire team will be able to use data collected throughout the organization to make decisions that will drive your business forward. They won’t be constrained to data they collect on their own — they’ll be able to leverage data that other teams collect as well.
During the process of collecting all this data, you’ll also identify areas where you aren’t collecting data correctly or important KPIs are not defined consistently. With a single source of truth, everyone will have access to the same data and work towards improving the same KPIs. Ultimately, by giving everyone access to a single source of truth, you’re driving alignment across the entire organization. If you get your single source of truth implementation right, you’ll be able to provide an accurate, consistent view of how your business is functioning.
On a more tactical level, every team will truly benefit from having better data. Your sales team will be able to get a more holistic picture of which customers to go after when they reach out to potential customers. Your marketing team will be able to iterate more quickly, running experiments on different market segments and targeting customers with the right messaging. Your engineering and product team will be able to see how their work impacts other areas of the company, particularly around revenue-driving functions.
Hopefully, you’re convinced at this point that having a single source of truth is a powerful concept, but you might be worried about how to even get started. First of all, it’s important to note that a single source of truth isn’t the answer for every company. If you’re a startup with five people, it’s unlikely that building out a single source of truth should be on your priority list.
However, if you’re starting to build out teams who need to leverage a consistent, correct data set to make decisions, that’s when you should start considering building out a single source of truth. If you’ve decided that a single source of truth is what you need, what are some best practices that you should follow?
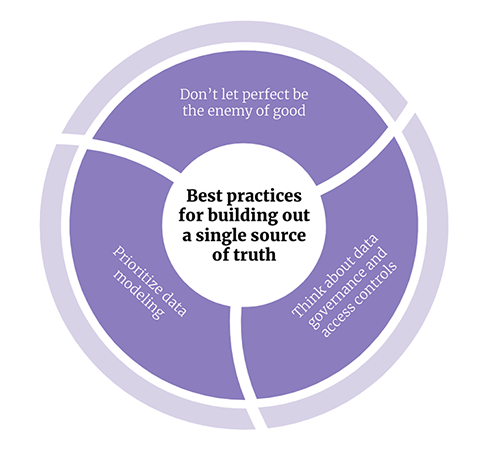
You could try to include every single data source under the sun, but rather than doing that, you should prioritize which data sources you want to include in your single source of truth. Although you might want to choose a tech stack that supports all your sources of truth, start with your most important ones first. This allows you to figure out some of the basics and build the right foundation you’ll need to add more data sources.
Don’t forget that permissions and who has access to what data is important. This is particularly important for companies that are SOC II compliant. Connecting best-in-class tools can help address data governance issues — only certain members of the data team have direct access to the cloud data warehouse, others might access the data warehouse via a BI solution or other tool that only exposes specific schemas or models.
Don’t just copy data from one system of record to another, make sure to think through how you want to model data. This is a critical step to making sure everyone is working off the same data. A common data modeling issue companies encounter is how to join accounts within the product with accounts in a CRM. This is important because if you want to know what features a paid account uses, you need to correctly tag product usage accounts and map them to CRM accounts. If you do this right, your business and product teams can work off the same data.
We covered a lot of ground in this blog post — from what a single source of truth is all the way to how you should think about implementing a single source of truth. Although it’s a lot of work, building out a single source of truth will truly allow your company to be more data-driven. It will also superpower the investments you’ve already made in downstream tools by allowing you to expose better, more accurate data to those tools.
With the current growth of adoption in cloud data warehouses, you’re well-equipped with the infrastructure you need to get started.
Featured image source: IconScout

LogRocket identifies friction points in the user experience so you can make informed decisions about product and design changes that must happen to hit your goals.
With LogRocket, you can understand the scope of the issues affecting your product and prioritize the changes that need to be made. LogRocket simplifies workflows by allowing Engineering, Product, UX, and Design teams to work from the same data as you, eliminating any confusion about what needs to be done.
Get your teams on the same page — try LogRocket today.

Learn how to choose and adapt product management frameworks based on your product stage, constraints, problem type, and business context.

Learn when streaks improve retention, when they create fragile engagement, and how PMs can design healthier systems around user progress.

A technical debt register brings transparency and clarity as to what type and how much debt you have and can be used to monitor and review your debt ratio.

Memos don’t have to be complicated. Just keep them clear, concise, and focused on actionable items. More on that in this blog.


