Choosing between proprietary and open source LLMs can feel overwhelming when you’re building AI-powered applications. OpenAI’s models like GPT-4 and GPT-3.5 are battle-tested and deliver cutting-edge performance, while open source alternatives like Llama 3, Mistral, and others give you more control and customization options.

This choice affects everything in your frontend applications — from development speed to long-term costs and compliance requirements. It becomes even more critical when you’re working in regulated industries or handling sensitive data.
In this article, we’ll evaluate OpenAI versus open source LLMs from a frontend developer’s perspective. We’ll compare integration complexity, performance characteristics, and practical implementation approaches to help you make the right choice for your next project.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Proprietary LLMs like OpenAI’s GPT models are closed-source, cloud-hosted services you access through APIs. You pay per token and have limited control over the underlying model, but you get state-of-the-art performance and a polished developer experience.
Open source LLMs like Meta’s Llama 3, Mistral’s models, or other available models can be downloaded, modified, and hosted on your own infrastructure. This gives you complete control over data, customization, and costs, but requires more technical expertise to implement and maintain.
For frontend developers, this choice affects how you integrate AI features into your applications. Proprietary models offer simple API calls and quick prototyping, while open source models require more infrastructure setup but provide greater flexibility for custom use cases.
Here’s a side-by-side comparison to help you quickly orient yourself:
| Factor | OpenAI (Proprietary) | Open Source LLMs |
|---|---|---|
| Setup Time | Minutes (API key + fetch) | Hours to days (infrastructure) |
| Integration Complexity | Low (REST API) | Medium to High (self-hosting) |
| Latency | 1-3 seconds typical | Variable (depends on hardware) |
| Cost Structure | Pay-per-token | Infrastructure + compute |
| Customization | Prompt engineering only | Full fine-tuning possible |
| Developer Experience | Excellent docs, SDKs | Varies by model/tooling |
| Data Privacy | Shared with provider | Complete control |
| Offline Capability | None | Full offline support |
This framework helps you quickly assess which direction makes sense for your project requirements and constraints.
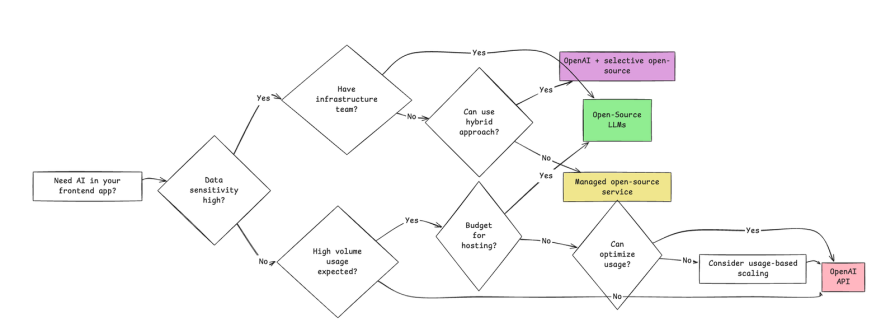
The decision tree below considers the most critical factors: data privacy requirements, infrastructure capabilities, usage volume, and budget constraints.
The choice between OpenAI and open source LLMs significantly impacts how your frontend application performs and feels to users.
OpenAI’s API typically delivers responses in 1-3 seconds for most queries, which translates to a smooth user experience in chat interfaces and AI assistants. The consistent response times make it easier to build predictable UI states and loading indicators.
Open source models running on your infrastructure can vary widely in performance. A well-configured GPU setup might match or exceed OpenAI’s speed, while a CPU-only deployment could take 10+ seconds for the same query. This variability affects how you design loading states and set user expectations.
With OpenAI, costs scale directly with usage through token consumption. A typical chat message might cost $0.002-0.06, depending on the model and response length. This makes budgeting straightforward but can become expensive at scale.
Open source models require upfront infrastructure investment. Running Llama 3 70B might cost $200-500/month in cloud GPU instances, but becomes more economical than OpenAI once you’re processing thousands of requests daily.
OpenAI limits you to prompt engineering and fine-tuning through their API. This works well for general-purpose applications but constrains how deeply you can customize behavior for specific use cases.
Open source models allow full fine-tuning, which enables highly specialized AI features. You can train a model specifically for your application’s domain, leading to more relevant responses and better user experiences in specialized workflows.
Different types of frontend applications benefit from different LLM approaches.
OpenAI excels for rapid prototyping and general-purpose AI features. If you’re building a chatbot for customer support, an AI writing assistant, or adding conversational features to an existing app, OpenAI’s plug-and-play nature accelerates development significantly.
Modern frameworks make OpenAI integration straightforward. You can have a working chat interface in Next.js or React in under an hour, complete with streaming responses and error handling.
OpenAI also works well for applications where the AI feature is supplementary rather than core to the product. Adding AI-powered search suggestions or content generation to an e-commerce site benefits from OpenAI’s reliability and broad knowledge base.
Open source models shine in privacy-first applications where data sovereignty matters. Healthcare apps, financial tools, or enterprise software often require that sensitive data never leaves your infrastructure.
Custom agents and specialized workflows also benefit from open source models. If you’re building a code review tool, legal document analyzer, or domain-specific assistant, fine-tuning an open source model on your specific use case often produces better results than prompting a general-purpose model.
Offline-first applications require open source models by definition. Desktop apps, mobile applications with limited connectivity, or edge computing scenarios need models that run locally without internet dependencies.
The architecture of your LLM integration has significant security implications for frontend applications.
With OpenAI, never expose API keys in client-side code. Instead, create backend endpoints that proxy requests to OpenAI’s API. This prevents key exposure and allows you to implement rate limiting, user authentication, and request filtering.
Here’s a typical secure flow: your frontend sends user input to your backend, your backend validates and forwards the request to OpenAI, then streams the response back to your frontend. This adds latency but provides essential security controls.
Self-hosted open source models eliminate the data sharing concerns inherent in cloud APIs. The entire conversation stays within your infrastructure, making compliance with regulations like HIPAA, GDPR, or SOX more straightforward.
This approach also gives you complete audit trails and the ability to implement custom security measures like input sanitization, output filtering, and conversation logging according to your specific requirements.
Let’s look at practical implementation approaches for both options.
The most common pattern involves a backend proxy to secure your API keys:
// Frontend: Send request to your backend
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message: userInput })
});
// Backend: Proxy to OpenAI with streaming
app.post('/api/chat', async (req, res) => {
const stream = await openai.chat.completions.create({
model: 'gpt-4',
messages: [{ role: 'user', content: req.body.message }],
stream: true
});
for await (const chunk of stream) {
res.write(`data: ${JSON.stringify(chunk)}\n\n`);
}
});
For open source models, tools like Ollama simplify local deployment:
# Install and run Llama 3 locally ollama pull llama3 ollama serve
Then integrate with your frontend through a simple API:
// Direct integration with local Ollama instance
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: 'llama3',
prompt: userInput,
stream: false
})
});
Libraries like LangChain.js and frameworks like CopilotKit abstract away many integration complexities. They provide unified interfaces that work with both OpenAI and open source models, making it easier to switch between providers or implement hybrid approaches.
Understanding where LLM processing happens affects your architecture decisions.
Most production applications run LLMs on backend services (Node.js, Python, serverless functions) and expose them to frontends through APIs. This approach provides security, scalability, and consistent performance regardless of whether you’re using OpenAI or self-hosted models.
Platforms like Vercel Edge Functions and Cloudflare Workers enable LLM processing closer to users. This works well with OpenAI’s API for reduced latency, and some edge platforms are beginning to support lightweight open source models.
Experimental WebAssembly implementations allow running small language models directly in browsers. While promising for privacy and offline use, current limitations in model size and performance make this approach suitable only for specific use cases.
The data flow typically follows this pattern: User input → Frontend validation → Backend/Edge processing → LLM inference → Response streaming → Frontend display.
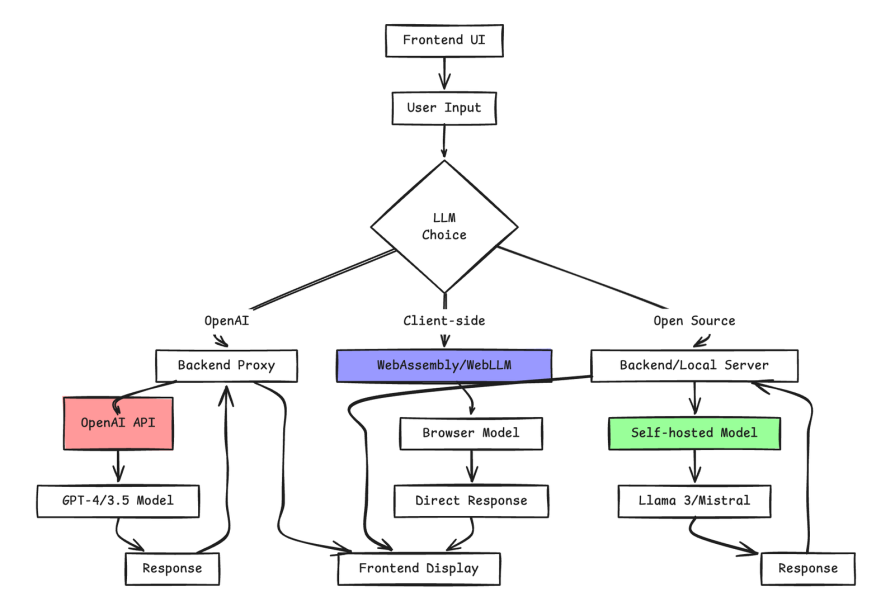
This architecture works regardless of whether your LLM is OpenAI’s cloud service or your self-hosted model. The key architectural differences are that OpenAI requires external API calls through your backend, self-hosted models run on your infrastructure, and experimental client-side approaches process everything in the browser.
Several trends are shaping how developers approach LLM integration in frontend applications.
More applications are implementing hybrid strategies that use OpenAI for general queries and specialized open source models for domain-specific tasks. This balances cost, performance, and customization requirements.
Tooling for open source LLM deployment is rapidly improving. Platforms like Hugging Face Inference Endpoints, Replicate, and cloud-native solutions are making open source models as easy to deploy as calling an API.
Projects like WebLLM are bringing lightweight language models directly to browsers using WebGPU. While still early, this trend could enable privacy-first AI features without backend infrastructure.
Choosing between OpenAI and open source LLMs depends on your specific requirements around cost, control, and compliance.
Choose OpenAI when:
Choose open source models when:
Remember that these aren’t mutually exclusive choices. Many successful applications start with OpenAI for rapid prototyping, then gradually migrate specific use cases to open source models as requirements become clearer and usage scales up.
The key is matching your choice to your application’s specific needs rather than following trends. Both OpenAI and open source models have their place in modern frontend development — the best choice is the one that aligns with your project’s constraints and goals.

Learn what vinext is, how Cloudflare rebuilt Next.js on Vite, and whether this experimental framework is worth watching.

Memory leaks in React don’t crash your app instantly, they quietly slow it down. Learn how to spot them, what causes them, and how to fix them before they impact performance.

Build agent-ready websites with Google Web MCP. Learn how to expose reliable site actions for AI agents with HTML and JavaScript.

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

