The AI stack has become increasingly confusing and complex. We’ve gone from two major players (OpenAI and Anthropic) in 2023 to over 200 providers, dozens of vector databases, and a constant stream of new “AI-native” tools launching weekly. AI applications are no longer in the experimental phase. These technologies have now matured to production-ready applications that enterprises can deploy at scale.

The good news is that the chaos can be simplified. Underneath the hype, every production-grade AI application is built on the same foundation: a stack of layers that work together.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it’s your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
In this article, we’ll break down those layers, show how today’s tools fit into each, and outline what matters when moving from a prototype to a production-ready AI system. You’ll walk away with a clear mental model for:
Think of this as a map of the AI landscape. Through this article, you’ll understand how everything fits together and what you actually need to build.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.

This is the core of the modern AI stack, and contains the foundational models, or the “brain” of the AI system. It provides the essential infrastructure for model training, fine-tuning, and deployment.
This is the data and memory layer of the modern AI stack. While LLMs are trained on massive but static datasets, they cannot stay up to date or context-aware on their own. This layer ensures that models can connect to real-world, enterprise, and application-specific data, so their responses remain accurate, relevant, and trustworthy.
It involves collecting, cleaning, structuring, storing, and retrieving data in ways that make it useful for AI systems. Without this layer, models risk hallucinating, pulling from stale information, or introducing compliance/security risks.
This is the execution layer of the AI stack. While Layer 1 provides models and compute, and Layer 2 handles data, this layer focuses on making AI systems production-ready. Raw API calls aren’t enough — you need orchestration for prompt management, retries, caching, routing, and agent workflows to turn a single model call into a reliable application.
This is the monitoring and improvement layer of the AI stack. Once applications are in production, teams need visibility into model performance, safety, and cost. Without observability, it’s impossible to detect regressions, track drift, or optimize reliably.
These layers can feel confusing, so let’s break down how you go from interacting with an AI application, like ChatGPT, to integrating with an LLM model.
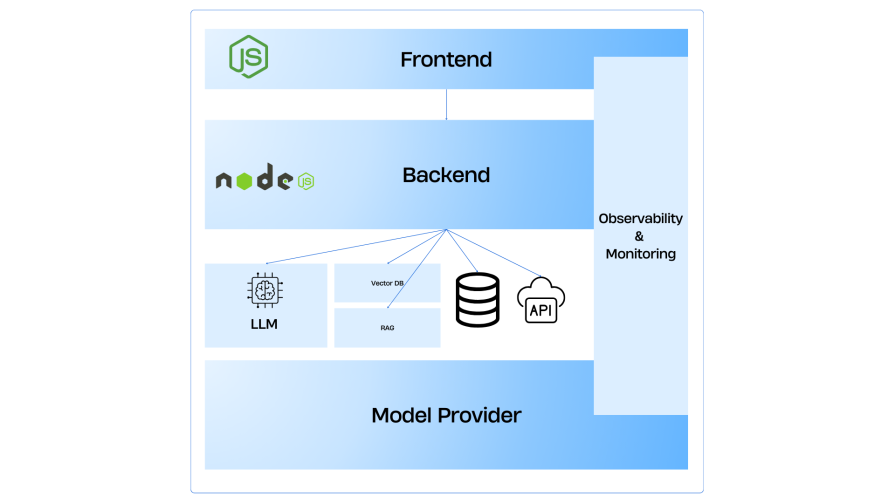 A production-grade AI application is more than a simple model call. Here’s a breakdown of the core building blocks of a typical AI app:
A production-grade AI application is more than a simple model call. Here’s a breakdown of the core building blocks of a typical AI app:
The user interacts with an LLM application typically through a chatbot-like interface. LLM models often return streaming inputs, aka continuous output of information such as in ChatGPT.
Therefore, a frontend application must be able to handle streaming input and applications. Frameworks such as Next.js and SvelteKit make it easier to receive streaming inputs. The user types a query into a responsive interface such as a chatbot, and the UI sends the query to the backend while rendering a loading state. As the output starts streaming in, the UI updates and shows the real-time, streamed-in output.
Options: React, Next.js, SvelteKit, Vue, SolidJS, Vercel AI SDK, Angular
The backend layer receives the query from the frontend and applies business logic. It then decides whether it needs to connect to an LLM to generate output or get extra context from a vector store. The backend application may also manage user data and business data through a database. This layer orchestrates the entire AI workflow, handling request processing, context management for conversations, model selection, and response formatting.
It integrates with external APIs, manages user sessions, and implements complex business rules. Modern AI backends often use event-driven architectures with message queues for handling long-running AI tasks and microservice patterns for different AI capabilities.
Options: Powered by serverless functions or APIs written in Python (FastAPI, Django, Flask), JavaScript/TypeScript (Node.js, Express), Go (Gin, Echo), Rust (Axum, Warp), Java (Spring Boot), C# (.NET Core) orPHP (Laravel)
If more context is needed, the backend queries the vector database for similar data. An example is a recommendation flow in Netflix where the user sees similar movies also available on Netflix. These movies are fetched from a vector database that contains embeddings or vector representations of the data.
The RAG pipeline enables AI applications to work with custom knowledge bases, such as enterprise data about customers, and provide accurate, up-to-date information beyond the model’s training data.
Options: Pinecone, Convex, Weaviate, Qdrant.
This orchestration layer is the interface between the actual LLM model and the web application. This layer manages complex AI workflows, including prompt engineering with templates and few-shot examples, multi-agent coordination for complex tasks, tool integration enabling AI to use APIs and external services, and memory management for conversations.
Options: LangChain, LlamaIndex, CrewAI, Haystack
This is the brain of the AI application. The LLM layer has pretrained data and merges the user’s input with the retrieved context. It then sends an enriched prompt to the model provider. The model generates a response, which could be partial (streaming) or complete. The output is sent back to the orchestration layer for final formatting.
Options: OpenAI, Hugging Face, Anthropic, Google Gemini
Having observability is key to maintaining a production-grade application, especially in AI applications. Every step is logged – input size, latency, errors, and user feedback.
Frontend observability tracks user interactions, streaming response performance, UI errors, and client-side AI features like voice input failures or multimodal content rendering issues.
Options: DataDog, New Relic, LogRocket.
AI-specific monitoring includes model performance tracking, hallucination detection, bias monitoring, cost tracking for token usage, user interaction analytics, and A/B testing for different prompts or models.
Options: LangSmith (LangChain), Humanloop, Helicone
| Frontend | React / NextJS, Tailwind / shadcn/ui, Server-Sent Events (SSE) for streaming response |
|---|---|
| Backend | Vercel Edge functions, NextJS API routes, TypeScript, Convex / Supabase, Clerk auth |
| Vector Store | Convex, Pinecone Starter, OpenAI embeddings |
| Orchestration | Vercel AI SDK, LangChain |
| Models | OpenAI GPT, Anthropic Claude |
| Observability | Vercel Analytics |
| Hosting | Vercel / Netlify |
| Cost | $0 – 200 / month |
| Frontend | Next.js with SSR, ISR & Edge caching, TanStack Query, RadixUI/ChakraUI + Design System, Websockets + SSE hybrid |
|---|---|
| Backend | Kubernetes with microservices, Supabase Pro / Neon Pro, Auth0 / Clerk |
| Vector Store | Pinecone, Qdrant, Weaviate, Unstructured.io, Databricks for large-scale processing |
| Orchestration | LangGraph, Vellum, Temporal for custom workflows |
| Models | OpenAI, Anthropic, Deepmind, Llama |
| Observability | Datadog, New Relic, LangSmith + Weights & Biases, Grafana |
| Eval / Guardrails | promptfoo |
| Hosting | AWS, GCP, Azure |
| Caching | Redis / Upstash Redis |
| File Storage | Cloudflare |
Start with Starter Stack – Next.js + Vercel AI SDK + Convex + 1 model. Focus on validating the use case and gathering user feedback.
Add an additional model, upgrade database, implement proper monitoring (Sentry + LangSmith), and optimize performance.
Migrate to microservices, implement enterprise authentication, add data governance, establish redundancy and backup strategies.
Custom fine-tuned models, complex agent workflows, multi-region deployment, advanced optimization, and cost management.
Upgrade when you have:
A modality refers to a type of data, such as text, images, audio, video, code, mathematical equations, or radar data.
Single-modal AI focuses on one modality at a time. For example, a language model trained only on text, or an image recognition model trained only on pictures. These systems often achieve high accuracy and efficiency within their specific domain because they are specialized.
Multimodal AI can process and combine multiple modalities such as text, images, audio, and video to generate a more holistic understanding of information.
Single-modality systems are ideal when deep expertise in a narrow field is required. Examples include natural language processing for chatbots and translation, or image recognition for medical imaging and facial recognition. These models tend to be lighter, faster, and less expensive to build and run.
Multimodal systems shine when context comes from different data streams at once. Autonomous vehicles rely on visual input from cameras, auditory input from sensors, and radar or LiDAR data. AI assistants benefit from the ability to see, hear, and respond to users naturally.
However, multimodal AI is resource-intensive, demanding more data, compute power, and longer development times, which means higher costs.
In short, single-modal AI gives you depth in one domain, while multimodal AI gives you breadth across domains.
In real-time processing, data is continuously processed as it arrives, and immediate output is provided. This works well for time-sensitive applications such as fraud detection or recommendation engines. The tradeoff is that streaming systems are high-maintenance and require intensive resources to manage.
Batch processing, on the other hand, is an efficient way of handling large amounts of data in predefined chunks. Data is collected, entered, and processed at regular intervals, and results are produced in bulk.
Since data is processed in batches, it is less resource-intensive and generally lower in cost. This approach is common for large-scale tasks such as log analysis, credit card statement generation, or test data generation.
Batch processing typically has higher latency because results depend on the batch cycle, which could range from minutes to days. Real-time or streaming systems, by contrast, provide instantaneous output with low latency.
It’s important to note that real-time data requires less storage since it is consumed immediately, while batch processing often demands larger storage capacity to hold the accumulated data before processing.
Real-time is best for chats, copilots, and interactive search. Batch processing is best for nightly enrichment, summarization, and indexing.
As a rule of thumb: if a user is waiting, stream.
When you make a request to an API, the model can generate the entire output before sending it back as a single complete response. This works fine for shorter outputs, but when the response is long, the latency can become very high.
An alternative is streaming. With streaming, responses are delivered in parts as they are generated, allowing the user interface to display content progressively or enabling systems to begin processing data immediately. This creates a faster, more interactive experience.
However, streaming introduces architectural complexity. It requires careful handling of partial outputs, error states, and synchronization across the system. In cases where responses can be kept short, using a smaller and faster model is often preferred because it simplifies development and reduces the overhead of managing a streaming pipeline.
Caching helps reduce both response time and cost by storing and reusing AI-generated outputs instead of calling the API repeatedly.
There are two common approaches:
In practice, exact caching is fast and cheap, while semantic caching is more flexible but requires additional compute to generate and compare embeddings.
The difference between a working prototype and a production-ready AI app lies in its ability to scale reliably, securely, and cost-effectively. Beyond building the core functionality, teams must account for:
Building an AI application when you are just getting started can feel overwhelming, but here are some steps that will make it manageable:
The AI stack is moving fast, but the principles stay the same: clean data, strong orchestration, observability, and security. Whether you’re hacking together a prototype or deploying at enterprise scale, the key is balancing creativity with engineering rigor. The winners won’t just be those with the best models or coolest apps, but those who know how to ship reliable, secure, and scalable AI applications.

Within roughly the same six-month window, Anthropic shipped Agent Teams for Claude Code, OpenAI published Swarm and the production-ready Agents […]

Compare the top AI development tools and models of March 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 11th issue.

Buying AI tools isn’t enough. Engineering teams need AI literacy programs to unlock real productivity gains and avoid uneven adoption.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now


One Reply to "What you actually need to build and ship AI-powered apps in 2025"
great