A message broker is a computer program that allows software, systems, and services to communicate with each other and exchange data, taking incoming messages from applications and performing actions on them.

By using message brokers, producers and consumers can communicate with the broker using a standard protocol for communication, with the broker handling all the data’s state management and tracking.
This means all consumer applications do not need to take on the responsibility of managing state, tracking, and the message delivery complexity of the message broker itself. Message brokers rely on a component called message queues that store messages until a consumer service can process them.
In this article, we’ll compare two Node.js message brokers: Apache Kafka and RabbitMQ. We’ll review the basics of message broker patterns, what each message broker provides, associated use cases, and more, including:
Message brokers have two forms of communication, which we will discuss:
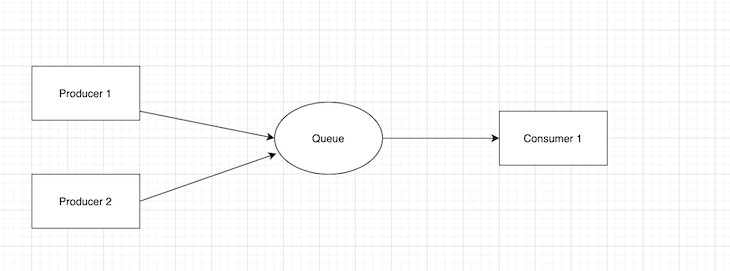
The point-to-point messaging method of communication in message brokers uses a distribution pattern utilized in message queues with a one-to-one relationship between the message’s sender and receiver.
Here, messages in the queue are sent to only one recipient and consumed once.
The publish/subscribe messaging method of communication means any message published to a topic by a producer is immediately received by all of the subscribers to the topic.
Here, all messages publish to a topic and distribute to all applications subscribed to the topic.
Apache Kafka is an open source, distributed streaming platform that gives users the ability to develop real-time, event-driven applications. This broker-based solution operates by maintaining streams of data as it records within a cluster of servers.
Because it runs as a cluster that can span multiple servers or even multiple data centers, Kafka provides data persistence by storing streams of records (messages) across multiple server instances in topics. In Kafka, a topic is a group of one or more partitions across a Kafka broker.
Kafka’s producer API allows an application to produce streams of data, including creating records and producing them to topics where topics are an ordered list of events.
The Kafka consumer API subscribes to one or more topics and listens to the data in real time. It can also solely consume old data saved to a topic.
The streams API consumes from a topic or topics and then analyses or transforms the data in real time. It then produces the resulting streams to a topic.
The connector API enables developers to write connectors, which are reusable producers and consumers. The connector API also allows implementing connectors or nodes that continually pull from a source system or application into Kafka or push from Kafka into an application.
Using Kafka is best for messaging, processing streams of records in real time, and publishing/subscribing to streams of event records.
It’s also great for event sourcing and commit logs. Event sourcing is an application style where data state changes are logged in a time-order sequence of records. These data changes are an immutable sequence or log of events.
Commit logs, on the other hand, use Kafka as an external commit log for distributed systems.
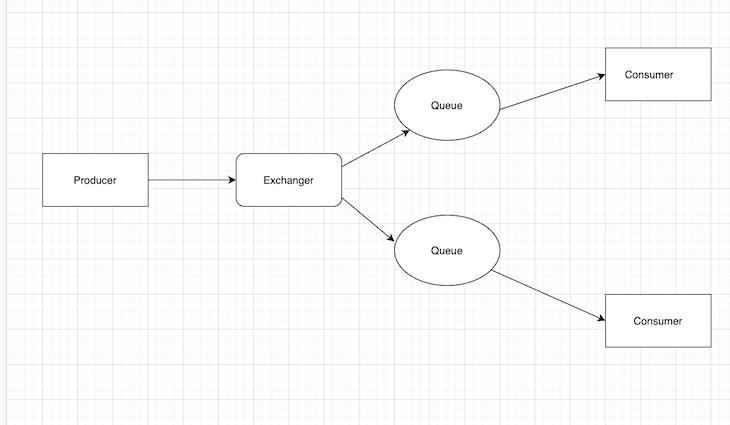
RabbitMQ implements the advanced message queuing protocol (AMQP) model. This means RabbitMQ accepts messages from a producer and then delivers them to consumers, acting as a middleman to reduce the workload taken in by web application servers.
In RabbitMQ, the producer’s messages do not publish directly to the queues but to an exchange. An exchange delivers messages to queues based on the exchange types, and the consumer service gets the data from the queues.
This means that when publishing messages, producers must specify the type of exchange to use.
There are four types of exchanges that RabbitMQ offers: fanout, direct, topic, and header.
The fanout exchange duplicates a message and sends it to every available queue.
The direct exchange sends messages to queues whose binding key matches the routing key of a message.
RabbitMQ’s topic exchange provides a partial match between a routing key and a binding key. The messages then publish with routing keys containing a series of words separated by a period.
RabbitMQ’s header exchange provides a routing key that is completely ignored and messages move through the system according to the header.
Some of RabbitMQ’s use cases include the following:
RabbitMQ can also be used for applications that support legacy protocols. RabbitMQ allows clients to connect over a range of different open and standardized protocols such as STOMP and MQTT.
RabbitMQ also enables communication between two or multiple microservices. Most users use RabbitMQ for microservices where it acts as a middleman for passing data between different services, avoiding bottlenecks when passing messages.
The major difference between Apache Kafka and RabbitMQ is that RabbitMQ is a message broker, while Kafka is a distributed streaming platform.
In terms of architecture, Kafka uses a large amount of publish/subscription messages and a flow platform that is fast. Because messages use server clusters, Kafka can store various records in a topic or topics.
It also consists of multiple brokers, topics, and partitions while providing durable and scalable high-volume publish/subscription messages.
For RabbitMQ, the message broker involves point-to-point messaging and publish/subscription communication designs. It consists of queues and its communication can be synchronous or asynchronous.
By ensuring a constant delivery of messages from the exchanger to the consumer, there is no direct communication between the producer and the consumer.
In terms of performance, Kafka offers higher performance than RabbitMQ because it uses a sequential disk I/O to boost its performance, thus making it the best option to form implementing queues.
This doesn’t mean that RabbitMQ is slow, as RabbitMQ can also process over a million messages per second. However, it does require more system resources for processing.
Most times RabbitMQ is combined with tools like Apache Cassandra to increase its performance and credibility.
RabbitMQ ejects messages as soon as the consumer acknowledges the message. This particular behavior cannot be changed because it is a part of the message broker.
Kafka, on the other hand, retains messages based on the configured timeout per topic. It is not concerned if the consumer acknowledges a message or not since it serves as a message log. Additionally, retention can be configured.
RabbitMQ ensures messages get to the consumer once they are requested. However, all messages are lost as soon as the consumer successfully consumes the message. Also, the behavior of evicting all messages as soon as they are consumed cannot be changed.
The only downside of using Kafka for message retention is that messages are lost immediately once the configured time finishes.
In terms of routing, RabbitMQ routes messages to subscribers of the message exchange according to the subscriber-based routing rules. Message routing in RabbitMQ can vary from being a fanout, topic, direct, or header type of exchange.
Kafka doesn’t permit any consumer to filter messages in the topic before querying them. In Kafka, any subscribed consumer gets all the messages in a division without error, and messages are pushed to topics with consumers subscribing to the topic.
RabbitMQ routes messages to subscribers based on a defined routing rule, and routing keys are used for message routing. However, only consumers with the same routing keys or headers have access to a message.
On the other hand, Kafka does not allow consumers to filter messages in a topic before polling them. And, Kafka requires an extra service called Kafka Stream Jobs that helps read messages from a topic and sends it to another topic the consumer can subscribe to.
RabbitMQ provides a user-friendly user interface for monitoring activities directly on a web browser. Activities like queues, connections, channels, exchanges, users, and user permissions can be handled (created, deleted, and listed) and monitored in the browser, providing flexibility.
Kafka has a number of open source tools for monitoring activities and administrative functionality, such as the Yahoo Kafka manager and KafDrop.
RabbitMQ comes with a built-in management UI that exposes a number of metrics. However, too many metrics are disclosed on the first screen, thus making it difficult to maintain and keep track of data changes.
You can install different management tools for different kinds of metrics in Kafka, such as, if you want to monitor the rate of consumers for lags, the best tool for this would be Burrow.
However, you must also install other open source tools for monitoring activities, leading to different monitoring tools for monitoring different activities.
RabbitMQ uses the smart broker/dumb consumer model, meaning the message broker delivers messages to the consumer and consistently keeps track of their status.
RabbitMQ also manages the distribution of the messages to the consumers and the removal of the messages from queues once they are acknowledged.
Conversely, Kafka uses the dumb broker/smart consumer model, meaning it doesn’t monitor the messages each consumer reads or acknowledges. Rather, it retains unread messages only, preserving all messages for a set amount of time provided in the config.
RabbitMQ ensures consumer nodes acknowledge data before it is evicted and it keeps track of each consumer status.
However, data is evicted once the consumer acknowledges the data and is only consumed by the consumer with the same routing key.
With Kafka, messages are retained even when a consumer node has the data and Kafka does not care about data acknowledgment.
Conversely, messages are lost once the configured time is reached.
RabbitMQ sends all messages to an exchanger where they are routed to various queue bindings for the consumer’s use.
Kafka, on the other hand, uses the publish/subscription topology sending messages across the streams to the correct topics.
Although RabbitMQ and Kafka are often used interchangeably, both technologies are implemented differently. Kafka tends to be the best option for larger distributed systems while RabbitMQ is best for systems with very low latency requirements.
In terms of engineering, both tools have completely different designs, which doesn’t make it a good match for comparison.
If you are looking at working with distributed systems, Kafka is the best fit, while RabbitMQ is the best fit for a traditional message broker service.
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Learn how to use Fallow to analyze AI-generated code, detect dead code, duplicate logic, and complexity issues, and integrate automated code quality checks into your AI-assisted development workflow.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

