As a frontend developer and a long-time Jamstacker, I’ve had more than enough time to be frustrated with how we use APIs. The REST protocol seemed like a step in the right direction (and it was), but I still ungratefully complained about its limitations despite the improvement.

So when I heard about GraphQL, I was blown away.
The idea is simple: the API itself defines what kind of data it can understand and exposes a single endpoint to the user. Then the user provides a query to that endpoint that looks similar to JSON without all the pesky values, quotes, and commas.
The API returns a JSON version of that query with the values filled out with all the data you asked for. It’s an incredibly simple idea, but it solves practically every problem that I’ve ever had with APIs.
Usually, GraphQL APIs are created with JavaScript, but my first love is Python, which is why I looked at Ariadne. Ariadne is a Python library that helps you create a GraphQL API without the extra weight.
In this article, I’ll document the process of making an Ariadne GraphQL API in Python 3.8, which will give the user access to a single simple array/dictionary structure.
I’m going to assume that you already have Python set up on your computer and that you’ve already installed Ariadne with pip3 install ariadne.
I want to give you a little notice here, though: stick with a single data source (like one database, one layer of business logic, or one Python dict). When I first heard about GraphQL, my first thought was that I could use it to combine all the other APIs I’m using into a single endpoint — that I could get rid of all the inconsistencies of REST and SOAP APIs and get all the data and functionality I needed without any trouble.
This is possible, but it’s way more trouble than it’s worth to roll your own. This concept is called an API Mesh, and it was pioneered by the folks at TakeShape.io. If you’re interested in learning more about TakeShape, feel free to check out their new docs page, but I’m going to stick with exposing a single data source here for simplicity.
Now that the boilerplate is out of the way, let’s see how Ariadne works. You can follow along with their quick-start guide, but I’m going to simplify it. It goes something like this:
First, use GraphQL’s special schema definition language to define a type. It’s similar to a TypeScript interface, where you define the keys of an object and the types of the values of each key.
Every app in Ariadne needs a type called Query, as that’s going to be compared against the input of the program, so let’s make that now. It’ll look something like this:
type Query {
hello: String!
}
That’s a really basic definition. Simply put, we define a type called Query. It has one key, called hello, which will always be a string. And here’s a bonus: the !at the end of that line means that hello will always be in an object if the object conforms to this type. If you left out the exclamation point, then hello would be optional.
Now, in our Python file (I’m going to call it endpoint.py), we’re going to stick that type definition into a string and pass it into the gql function of Ariadne. So far, our file looks like this:
from ariadne import gql
typedefs = """
type Query {
hello: String!
}
"""
typedefs = gql(type_defs)
That’s going to validate our type definition and throw an error if we didn’t write it correctly.
Next, Ariadne wants us to create an instance of the ObjectType class and pass in the name of our type. In short, this will be the Python representation of the type we’re making.
We’re also going to add some boilerplate at the end and move our type definition in there. Now endpoint.py looks like this:
from ariadne import ObjectType, gql, make_executable_schema
from ariadne.asgi import GraphQL
basetype = ObjectType("Query") # there is a shortcut for this, but explicit is better than implicit
type_defs = """
type Query {
hello: String!
}
"""
app = GraphQL(
make_executable_schema(
gql(type_defs),
basetype
),
debug=True
)
Ariadne’s main purpose is to scan over the input query, and, for each key, run a resolver function to get the value of that key. It does this with decorators, a cool Pythonic way of giving your function to Ariadne without more boilerplate. Here’s our endpoint.py with a resolver function for our hello key:
from ariadne import ObjectType, gql, makeexecutableschema
from ariadne.asgi import GraphQL
basetype = ObjectType("Query")
type_defs = """
type Query {
hello: String!
}
"""
@basetype.field("hello")
def resolve_hello(obj, info):
return "Hello world!"
app = GraphQL(
makeexecutableschema(
gql(type_defs),
basetype
),
debug=True
)
That’s pretty much it. Ariadne has many fascinating and useful features (seriously, ruffle through their docs), but that’s all you need to get started and to understand how it works. If you’re interested in testing this, though, it needs to go on a server.
You can temporarily make your local machine into one using Uvicorn. In short, you’d want to install with pip install uvicorn, cd to the folder where your endpoint.py is, and run uvicorn endpoint:app. Then, visit 127.0.0.1:8000, where you’ll see Ariadne’s GraphQL interface. It looks cool:
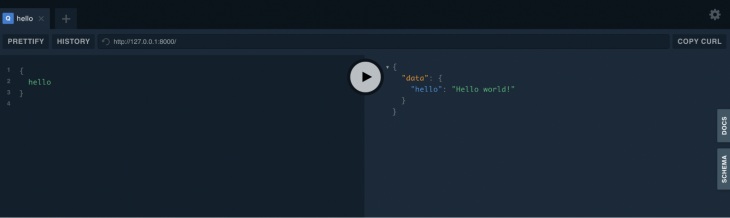
There’s just one caveat: the intro doc page that I roughly followed here makes a good point about halfway through. “Real-world resolvers are rarely that simple: they usually read data from some source such as a database, process inputs, or resolve value (sic) in the context of a parent object.”
Translation into simple English? “Our API does absolutely nothing useful. You give it a query and it tells you, Hello world!, which is neither funny nor helpful. The resolver function we created needs to take input, get data from somewhere, and return a result to be worth much.”
Well, now that we’ve got our boilerplate, let’s try to make this API worth its weight in salt by accessing a rudimentary database made out of Python arrays and dictionaries.
Hmm… what shall we build? Here’s what I’m thinking:
Sitcom type, which should have fields for the name (which would be a string), number_of_seasons (Int), and characters (an array of characters)first_name, last_name, and actor_name fields, all of them stringsThis sounds doable! We’ll only have two types (sitcom and character), and the data that we’re exposing can easily be stored in a Python dictionary structure. Here are the dicts I’ll be using:
characters = {
"jeff-winger": {
"first_name": "Jeffrey",
"last_name": "Winger",
"actor_name": "Joel McHale"
},
"michael-scott": {
"first_name": "Michael",
"last_name": "Scott",
"actor_name": "Steve Carell"
},
...
}
sitcoms = {
"office": {
"name": "The Office (US)",
"number_of_seasons": 9, # but let's be real, 7
"characters": [
"michael-scott",
"jim-halpert",
"pam-beesly",
"dwight-schrute",
...
]
},
"community": {
"name": "Community",
"number_of_seasons": 6, #sixseasonsandamovie
"characters": [
"jeff-winger",
"britta-perry",
"abed-nadir",
"ben-chang",
...
]
},
...
}
We’ll want to define our types just like we did earlier with our query type. Let’s try this:
query = ObjectType("Query")
sitcom = ObjectType("Sitcom")
character = ObjectType("Character")
type_defs = """
type Query {
result(name: String!): Sitcom
}
type Sitcom {
name: String!
number_of_seasons: Int!
characters: [Character!]!
}
type Character {
first_name: String!
last_name: String!
actor_name: String!
}
"""
app = GraphQL(
make_executable_schema(
gql(type_defs),
query,
sitcom,
character
),
debug=True
)
In parentheses is the query type, which is an argument. We’re passing in a name (which will always be a string) to theresult key of the query type, and that’s going to be sent to our resolver. I’ll jump into this a bit more in a second.
In case you’re wondering about that [Character!]! bit, that just means that the array is required, as well as the characters inside of it. In practice, the array must be present and must have characters in it.
Also, in the boilerplate at the end, we’re passing in all three types to the make_executable_schema function. That tells Ariadne that it can start using them both. In fact, we could add as many types as we want there.
So, here’s how this will work. The client will send a request that looks something like this:
<code>{
result(name:"community")
}</code>
The server is going to take that, send "community" to the resolver for the result field, and return not just any sitcom, but the right sitcom. Let’s build those resolvers now.
Here’s our full endpoint.py:
from ariadne import ObjectType, gql, make_executable_schema
from ariadne.asgi import GraphQL
import json
with open('sitcoms.json') as sitcom_file:
sitcom_list = json.loads(sitcom_file.read())
with open('characters.json') as character_file:
character_list = json.loads(character_file.read())
query = ObjectType("Query")
sitcom = ObjectType("Sitcom")
character = ObjectType("Character")
type_defs = """
type Query {
result(name: String!): Sitcom
}
type Sitcom {
name: String!
number_of_seasons: Int!
characters: [Character!]!
}
type Character {
first_name: String!
last_name: String!
actor_name: String!
}
"""
@query.field("result")
def getSitcom(*_, name):
return sitcom_list[name] if name in sitcom_list else None
@sitcom.field("characters")
def getCharacters(sitcom, _):
characters = []
for name in sitcom["characters"]:
characters.append(character_list[name] if name in character_list else None)
return characters
app = GraphQL(
make_executable_schema(
gql(type_defs),
query,
sitcom,
character
),
debug=True
)
That’s the whole program! We’re using the data in the JSON files to fill out responses to the input GraphQL queries.
We don’t have to be done though! Here are some ideas off the top of my head about what to do next.
We were just using a rudimentary JSON data storage structure, which is bad practice but reasonable for a sample application like this one. For anything larger than this toy app, we’d want to use a more rugged data source like a proper database.
We could have a MySQL database with a table each for sitcoms and characters, and fetch that data in the resolver functions. Also, queries themselves are only half of what we can do with GraphQL and Ariadne. Mutations are the other half. They let you update existing records, add new ones, or potentially delete rows. These are fairly easy to set up in Ariadne.
Of course, creating an API to keep track of sitcoms and characters is a bit pointless, but it’s a fun experiment. This all could be used more productively if we built a GraphQL service like this around more useful data. Say you’re running an existing REST API — why not serve that data with GraphQL?
Finally, when we create a GraphQL API, it’s often tempting to try to fetch data from a database of our own and merge in data from an external source, such as some third-party API. You can do this by making requests to those external APIs over HTTP in the resolvers, but that’ll significantly reduce your program and leave you to worry about edge cases and error handling yourself.
Believe me, it’s more trouble than it’s worth. However, to take this project further, you could make your Ariadne app fetch data from your internal database, plug the API you just created into an API mesh (like TakeShape), and then combine it with some other third-party service there.
That way, all the difficult merging stuff is the mesh’s problem, not yours. I’ve done this several times and it’s gratifying to see it all come together.
There’s not much to this. I tried to explain as much detail as I could just in case you want to branch off and explore any of those points more, but the technique is rather simple.
You can build pretty much anything you can dream up. You’ll probably run into some roadblocks, but Ariadne has a wonderful community on GitHub ready to help. I wish you the very best on your Ariadne adventures!
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

