“Monolith” is a term to describe a software architecture where an application is constructed as a single, indivisible unit. In this architecture, all components are tightly coupled and interdependent.

The monolithic approach has been foundational in application development since the early 1960s when it was initially employed in batch processing software for mainframe computers. Its significance persisted into the late 90s, particularly in enterprise software where server-side code often remained monolithic despite client-server computing that separated the interface from business logic. Frameworks like Ruby on Rails, which prioritizes convention over configuration, have further popularized monolithic architecture.
However, as codebases and user bases expand, significant challenges have emerged with monoliths. Issues such as scalability, code complexity, and deployment bottlenecks have increasingly hampered the efficient delivery and maintenance of software, prompting the exploration of alternative architectures.
Microservices architecture has emerged as a solution to many of these challenges, offering enhanced scalability and easing deployment bottlenecks. Despite its advantages, transitioning from monolithic to microservices architecture presents substantial challenges, primarily the complexity of decoupling a tightly integrated application.
In this article, we will explore how to effectively break down a monolithic application into microservices using feature flags and Flagsmith as the feature flagging tool. We will demonstrate building a monolithic Node.js backend, decoupling it into microservices, and transitioning API requests from the monolith to microservices using feature flagging in a local environment.
Usually, the first question in the quest to convert a monolith application into microservices is…
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
The difficulty of decoupling a monolith application depends upon multiple factors, such as the codebase size, complexity of the code, programming language, business logic, and major functionalities that an application performs. The impact of these criteria will vary across applications, so it must be considered on a case-by-case basis.
To better understand this, let’s create a demo for a monolith application we want to convert into divisible units based on the decoupling criteria.
Let’s assume the basic functionalities of a monolith application representing a bookshop where users can register themselves, search for books, add books to a cart, and buy audiobook subscriptions.
Due to their successful business and the audiobook feature, bookshop sales have started to increase and the shop’s user base is increasing weekly. Due to the increased traffic, the shop has started to face downtimes that might affect its sales. Therefore, the platform has decided to migrate to microservices to keep things stable. This will take time, effort, and most importantly, a plan for how to migrate their application to microservices.
Step 1: Identify bounded contexts
First, we need to understand and define the different “zones” or bounded contexts within the bookshop. Let’s break it down:
Step 2: Create microservice boundaries
Next, we’ll create a separate microservice for each bounded context:
Step 3: Database decoupling
Each microservice will have its own database, which will ensure service independence and bring clarity to data ownership.
Step 4: Develop APIs for communication
Each microservice will have its own REST APIs for inter-service communication, making the services loosely coupled.
Step 5: Gradual revamping and migration
The monolith application will be revamped gradually and deployed in parallel to the monolith application, starting from the less critical services to minimize the risk and blast radius if something crashes.
Example: Decoupling the Product Catalog
Repeat this process for each microservice.
Step 6: Implement inter-service communication
In this step, we’ll use REST APIs and, where necessary, messaging queues (like RabbitMQ) for inter-service communication.
Example: Order Service and Product Service interaction
As you can see, a generalized plan can be very useful for application migrations from old architectures to new ones, but the challenges continue to emerge after converting a monolith to a microservice.
And that is…
One of the great challenges with converting a monolith to a microservice is initiating the re-routing of API requests to the new application in production. This comes with the risk of disruption to existing services and a bad user experience that might increase the bounce rate for an application, so it must be handled very efficiently with minimal downtime. To achieve this, there are many strategies that we can employ, such as Blue/Green or canary deployments, and feature flagging.
In the following sections, we will explore how feature flagging can help us re-route API requests.
When transitioning from monolithic architectures to microservices, feature flagging is a critical tool. It allows developers to toggle features on or off in a live application without deploying new code, enhancing flexibility and control over the release process. This method supports risk mitigation, and gradual migration, and facilitates continuous integration and delivery, making it essential for modern software development practices.
Feature flagging offers benefits such as:
Now that we have a holistic view of feature flags’ capabilities, let’s use them in the coming section.
In this lab, you will first create a sample Node.js backend in a monolith manner that has endpoints for managing users and orders. Next, you will create an api-gateway and integrate the Flagsmith SDK with it, decouple the monolith functionality into microservices, and finally dockerize the whole application to run and test it.
To follow along, you will need an understanding of the following:
First, we need to create a project on Flagsmith. Create a (free) account and sign in to Flagsmith here, which should only take a couple of minutes. After signing in, create a new project as shown below:
I have named it “mono-to-micro,” but you can use whatever name you like.
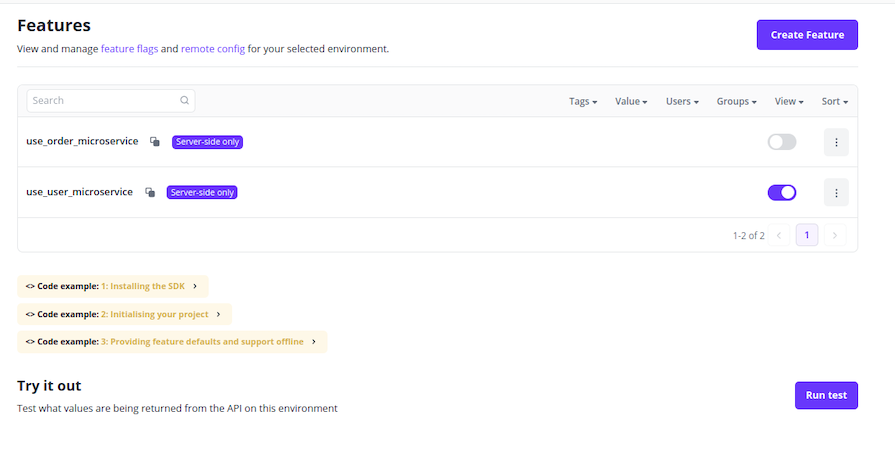
Next, create two feature flags for your microservices as follows:
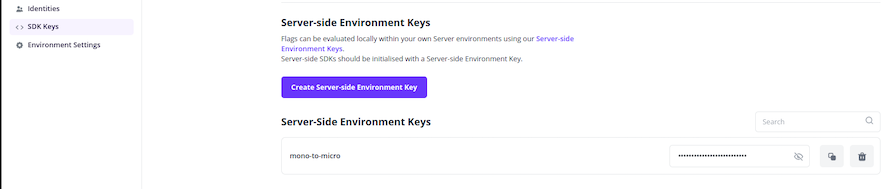
Fetch the Environment Key for SDK integration from the SDK Keys section in the left menu bar. You will have to generate a server-side environment key and keep it safe:
Now we have everything we need to start working…
Create a folder and name it monolith with the following command:
mkdir monolith
├── docker-compose.yml ├── microservices/ │ ├── api-gateway/ │ ├── order-service/ │ └── user-service/ └── monolith/
N.B., when initializing the projects below, remember to input app.js in the entry point field to override the default name index.js, because we are using app.js in this guide.
Next, create a Node project and run the following command:
yarn init
In the package.json file, add a scripts object as follows:
"scripts": {
"start": "node app.js",
"test": "nodemon app.js"
}
Create an app.js file in the root of the directory and add the following code:
// app.js
const express = require("express");
const app = express();
const port = 3000;
// Hardcoded data
const users = [
{ id: 1, name: "Alice" },
{ id: 2, name: "Bob" },
{ id: 3, name: "Charlie" },
];
const orders = [
{ id: 1, item: "Laptop", quantity: 1, userId: 1 },
{ id: 2, item: "Phone", quantity: 2, userId: 2 },
{ id: 3, item: "Book", quantity: 3, userId: 3 },
];
// Routes
app.get("/users", (req, res) => {
console.log("User list from monolith app", users);
res.json(users);
});
app.get("/orders", (req, res) => {
console.log("Order list from monolith app", orders);
res.json(orders);
});
app.listen(port, () => {
console.log(`Monolith listening at http://localhost:${port}`);
});
Then, run the following command to install some essential dependencies:
yarn add express nodemon
In the same directory, create a Dockerfile and add the following code:
FROM node:18-alpine
RUN apk --no-cache add \
bash \
g++ \
python3
WORKDIR /usr/app
COPY package.json .
RUN yarn install
COPY . .
Now that your sample monolith application has been built with some endpoints and hardcoded data, you can test the application endpoint by running the following command:
yarn test
This is the expected output:

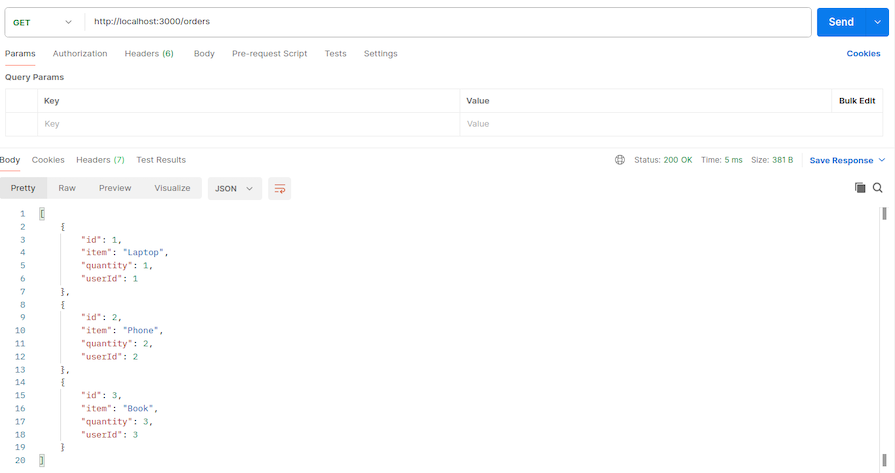
To test the endpoints, open Postman and hit the following endpoints:
orders-endpoint: http://localhost:3000/orders
users-endpoint: http://localhost:3000/users
This is the expected output for user-service:
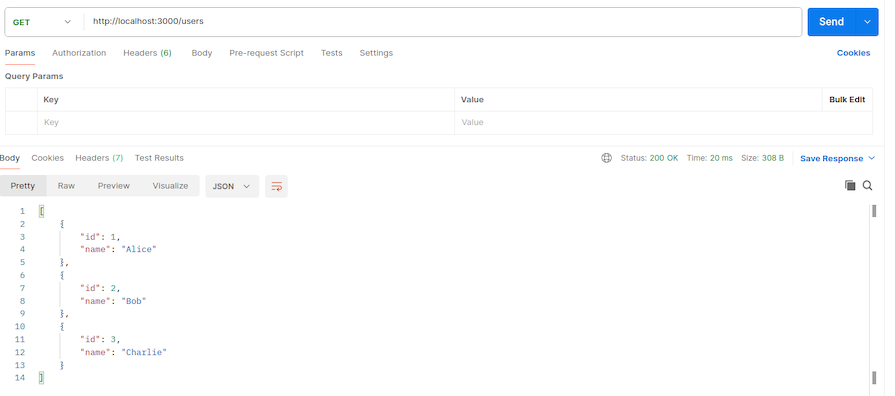
And this is the expected outcome for order-service:
We have successfully tested the monolith application, so now it is time to convert it into microservices. We will be decoupling the application based on functionalities. Currently, the monolith application can be divided into two distinct functionalities: first, the order service, which will handle orders and provide hardcoded data for orders, and second, the user service, which will provide hardcoded user data.
As you can see, the microservices we are building will each be responsible for a single task (this is one of the core principles of decoupling a monolith application).
Let’s continue coding…
Alongside the monolith directory, create a new directory named microservices and inside it, create a Node.js order-service project by running the following commands:
mkdir order-service cd order-service yarn init
Run the following command to install some essential dependencies:
yarn add express nodemon
In the package.json file, add a scripts object as follows:
"scripts": {
"start": "node app.js",
"test": "nodemon app.js"
}
Create an app.js file in the root of the directory and add the following code:
// app.js
const express = require("express");
const app = express();
const port = 3002;
const orders = [
{ id: 1, item: "Laptop", quantity: 1, userId: 1 },
{ id: 2, item: "Phone", quantity: 2, userId: 2 },
{ id: 3, item: "Book", quantity: 3, userId: 3 },
];
app.get("/orders", (req, res) => {
console.log("Order list from microservice app", orders);
res.json(orders);
});
app.listen(port, () => {
console.log(`Order Microservice listening at http://localhost:${port}`);
});
In the same directory, create a Dockerfile and add the following code:
FROM node:18-alpine
RUN apk --no-cache add \
bash \
g++ \
python3
WORKDIR /usr/app
COPY package.json .
RUN yarn install
COPY . .
Now let’s create the user-service. It will be created in the same directory as the order-service, with nearly everything being the same except for the endpoints. Therefore, replicate the previous steps used to create the order-service and replace the app.js file with the following code:
// app.js
const express = require("express");
const app = express();
const port = 3001;
// Hardcoded data
const users = [
{ id: 1, name: "Alice" },
{ id: 2, name: "Bob" },
{ id: 3, name: "Charlie" },
];
// Routes
app.get("/users", (req, res) => {
console.log("User list from microservice app", users);
res.json(users);
});
app.listen(port, () => {
console.log(`User microservice listening at http://localhost:${port}`);
});
api-gateway serviceIn this last step, our api-gateway will act as an interface to interact with our microservices and will be integrated with the Flagsmith SDK.
Because this will be a Node.js application, replicate the previous steps taken to create the microservices and replace the entry-point file (app.js) with the following code. Remember to Dockerize it because we will be running all our services from docker-compose:
// app.js
const express = require("express");
const axios = require("axios");
const Flagsmith = require("flagsmith-nodejs");
const app = express();
const port = 8080;
const flagsmith = new Flagsmith({
environmentKey: "",
});
// Users route
app.get("/users", async (req, res) => {
const flags = await flagsmith.getEnvironmentFlags();
var isEnabled = flags.isFeatureEnabled("use_user_microservice");
if (isEnabled) {
const response = await axios.get("http://user-service:3001/users");
console.log("Response from user microservice", response.data);
res.status(200).json(response.data);
}
else {
const response = await axios.get("http://monolith-service:3000/users");
console.log("Response from monolith service", response.data);
res.status(200).json(response.data);
}
});
// Orders route
app.get("/orders", async (req, res) => {
const flags = await flagsmith.getEnvironmentFlags();
var isEnabled = flags.isFeatureEnabled("use_order_microservice");
if (isEnabled) {
const response = await axios.get("http://order-service:3002/orders");
console.log("Response from order microservice", response.data);
res.status(200).json(response.data);
} else {
const response = await axios.get("http://monolith-service:3000/orders");
console.log("Response from monolith service", response.data);
res.status(200).json(response.data);
}
});
app.listen(port, () => {
console.log(`API Gateway listening at http://localhost:${port}`);
});
api-gatewayThe above code has two GET functions: one fetches the user data and the other fetches the order data. The routing decisions are based on the flag value fetched from Flagsmith. If the flag returns true, the traffic will be routed toward microservices. Otherwise, it will continue to hit the monolith application.
The flags I created in my account for both services were as follows:
use_user_microservices
use_order_microservices
For Flagsmith SDK to work, you must add the SDK key created from your account and use it in the code.
To run both the monolith and microservices in parallel, we will need to write a docker-compose file for better visibility and control. We’ll run all four services as Docker containers and then shift our API requests using the Flagsmith SDK, which we integrated in the previous step.
Create a docker-compose file where the directories, monolith, and microservices are located, and copy the following code:
version: "3"
services:
api-gateway:
build: ./microservices/api-gateway
container_name: api-gateway
command: yarn start
hostname: api-gateway
restart: always
ports:
- 8080:8080
monolith-service:
build: ./monolith
container_name: monolith-service
command: yarn start
hostname: monolith-service
restart: always
user-service:
build: ./microservices/user-service/
container_name: user-service
command: yarn start
hostname: user-service
restart: always
order-service:
build: ./microservices/order-service/
container_name: order-service
command: yarn start
hostname: order-service
restart: always
Now, run the following command and all the containers will start:
docker compose up -d –build
This is the expected output:

All the servers are running and now we can see the feature flagging of Flagsmith in action.
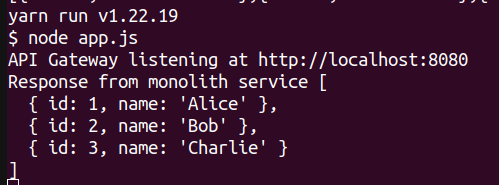
Currently, both our flags are off, so if you hit an API, the gateway will forward the request to the monolith application. To quickly test it, run a curl command on the api-gateway endpoint like this:
curl http://localhost:8080/users
The request will be routed to the monolith container as seen in the output below:
Verify it, open the container logs of api-gateway, and you will see a similar response to the one shown above.
Now let’s go to Flagsmith and turn on the feature flag for user-service:
We’re testing the same endpoint again, but this time if you open the api-gateway container logs, you will see a different prompt showing that the request was forwarded to the microservice instead of the monolith app:
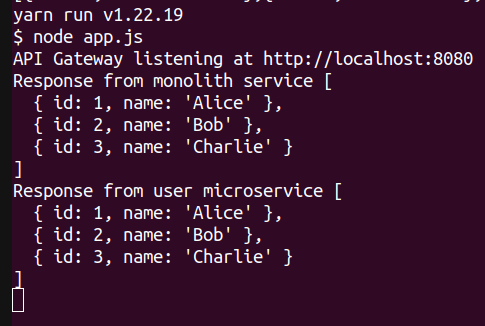
As you can see, the feature flagging is in action; we just routed endpoint traffic from monolith to microservice in a flash.
Currently, the flag for order-service is turned off, which means that if we hit the orders endpoint from our api-gateway, we should get a response from the monolith application instead of the microservice. Try hitting the following endpoint and observing the output in the api-gateway logs:
curl http://localhost:8080/orders
Here is the expected output:
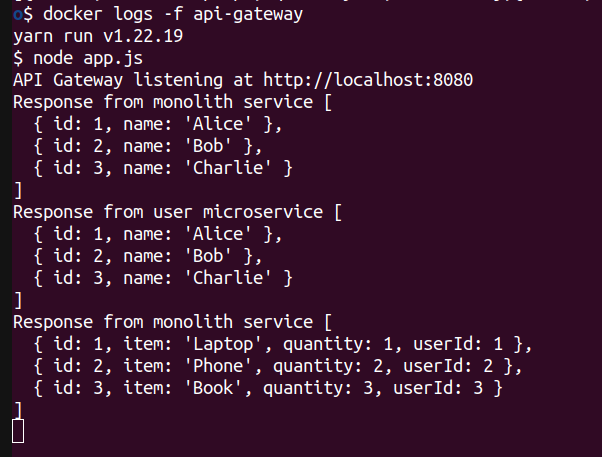
As you can see, we have successfully used Flagsmith’s feature flagging functionality to migrate an API request from the monolith to the microservices. Although this is a small-scale representation, the concept can be replicated and used in production environments, such as in Kubernetes to expose endpoints and services to the user base that have recently been revamped to microservices.
Flagsmith’s feature flagging can be very helpful in mitigating downtime during migrations, performing A/B testing, and facilitating canary deployments.
In this article, we covered a brief history of application architectures and explored the emergence of microservice architecture. We also created a bookshop web app to demonstrate the practical application of these concepts.
Throughout the demonstration, we covered the issue of rerouting traffic and how Flagsmith can help solve this problem. Finally, we implemented a demo application in which we saw how Flagsmith’s feature flagging can come in handy to reroute traffic from a monolith to microservices in a local environment, which can act as a reference for similar implementations in a production environment.
To read more about Flagsmith, check out the official documentation to get started.
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

useEffect breaks AI streaming responses in ReactSee why useEffect breaks AI streaming in React, and how moving stream state outside React fixes flicker and stale updates.

A real-world debugging session using Claude to solve a tricky Next.js UI bug, exploring how AI helps, where it struggles, and what actually fixed the issue.

CSS wasn’t built for dynamic UIs. Pretext flips the model by measuring text before rendering, enabling accurate layouts, faster performance, and better control in React apps.

Why do real-time frontends break at scale? Learn how event-driven patterns reduce drift, race conditions, and inconsistent UI state.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

