We’ve seen quite a lot of movement on the editor front in recent years. First, Sublime Text came to conquer the world. It’s novel design elements (preview bar, go to anything, instant command prompt) paired with ultra strong extensibility proved too much for the competition. Later, when GitHub started the Atom project, it seemed a natural successor.
However, performance issues and general limitations prevented an immediate success. The door for web technologies in the editing space seemed to be open and Microsoft happily stepped in. VSCode is nothing more than the same idea as GitHub’s Atom with Monaco as code editor and TypeScript in its extensibility core.
This combination is both elegant and powerful. There is also one more thing that makes VSCode as appealing as it seems to be: The Language Server Protocol.
The language server protocol (LSP) is Microsoft’s answer to the old n * m problem: Consider n languages and m editors — how many implementations are needed to make these languages available on all editors?
By using the LSP we can reduce the number to the number of languages (or even further if some languages are similar and may be aggregated). How is this possible? Well, all we need is a generic specification for common editing tasks within a communication pattern. This specification is called the language server protocol.
In this post we will investigate how to use the language server protocol for actually extending any client understanding the LSP.
Language server history
It all started when Microsoft played around with use cases of C# (and VBs) new and shiny compiler, codenamed Roslyn. What makes Roslyn special is that it was developed with reusability and extensibility in mind. Instead of being a black box, developers could easily hack (or extend) the fundamentals that C# was standing upon.
Furthermore, it should be easy to use the created basis for future projects. Microsoft created a few external tools (and some of these even made it outside of the company), but wanted to created something that not only shows the greatness of this new piece of tech, but also increases the adaption of C# / .NET as a whole.
As a result of Microsoft’s efforts to increase the C# adaption outside of the usual circles, the OmniSharp project was born. It was a simple server that leverages the cross-platform aspect of .NET and it’s new compiler platform Roslyn.
The idea was simple: A small server layer makes all the greatness of Roslyn easily accessible. Any editor with advanced capabilities (i.e. extensibility) could therefore access Roslyn’s information on C# files without having to re-implement these details. Only the integration of such a server into the editor needs to be done.
The idea made sense. Instead of developing an advanced C# language extension in N editors (thus duplicating a lot of the features with risk of unequal implementations and risk of the maintenance hell) only a couple of lines had to be written; enough lines to connect to a small server. The server itself could purely use Roslyn and would be implemented in C# itself.
The OmniSharp project was fairly successful. Integrations for all known editors exist such as vim, Sublime Text, Emacs, etc. They all provide a great experience that comes already quite close to using C# inside Microsoft’s own flagship IDE Visual Studio.
But, while OmniSharp did a great showcase for Roslyn and .NET it did not provide any new infrastructure or language integration basis in general. It just showcased that such a standard is totally missing and would definitely solve a problem that the OmniSharp team faced: The missing integration in the client (i.e., the various editors) results in many redundant plugins, which will eventually end up in maintenance hell.
If this integration could be standardized the OmniSharp team would only have to deal with the server part, instead of having also to deal with all the different extensions.
Language server basics
Fast forward into 2018 — we realize that progress has been made and such a standard exists, even though the standard was artificially born and has yet to reach full coverage. The initial work on the standard commenced by three companies: Microsoft, Red Hat, and Codenvy.
Today, many clients are already out there and the LSP working group contributors are keen on working together to improve the existing specification. At its core, the LSP only defines a server for JSON-based remote procedure calls (RPC), known as JSON-RPC. JSON-RPC is already quite old, established, and fairly simple.
There are multiple ways to use JSON-RPC, but you see these two ways in most implementations:
- Communication is done via the standard input / output, i.e., the command line interface
- Communication is performed via TCP/IP, i.e., network messages similar to HTTP
The protocol is independent of the communication format. We could use telnet or similar to establish a connection. As long as we can send in strings and receive strings we are good. The format of the strings, of course, needs to follow the JSON-RPC specification, which can look such as
// standard input --> sent to server
{ "jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": 1 }
// standard output <-- sent to client
{ "jsonrpc": "2.0", "result": 19, "id": 1 }
All in all it is just a format for RPC which is based on JSON with some special rules and restrictions. An important observation is that the JSON-RPC protocol is fully asynchronous. Responses to clients can be send out-of-order and without time restriction. This motivates the correct use of the id parameter, which can be used to map previously done requests with incoming responses.

The question now: How is JSON-RPC used in the LSP?
Well, JSON-RPC provides the abstraction over the used communication and programming language. Thus, even though the client (e.g., VSCode) would use one technology (e.g., Node.js), a language service could be a completely different technology (e.g., C#) and does not even require to be run locally.
In theory, such language services could be also in the cloud, even though it seems impractical to include such high latency times in an IDE. Another limitation that prevents such implementations is that we have a one-to-one relationship between client and server.
To quote the spec:
The protocol currently assumes that one server serves one tool. There is currently no support in the protocol to share one server between different tools.
In short: LSP specifies a couple of well-defined methods including their parameter and result (types). All these methods are supposed to be accessible via the JSON-RPC protocol and are therefore naturally decoupled from a specific technology or communication format.
Protocol essentials
Now that we roughly know the fundamentals of the LSP, it is time to actually look at the protocol. By default, the protocol assumes that the server is started and closed by the client. Hence, the lifetime of a language server is fully determined by its user.
Multiple instances are, of course, possible and should not conflict with each other. In its core the protocol distinguishes between three kinds of messages being send by the two parties:
- Requests from the client, which are supposed to have a response
- Responses from the server, which are replies to earlier requests
- Notifications, which are messages without response expectations (originator: client), or without prior requests (originator: server)
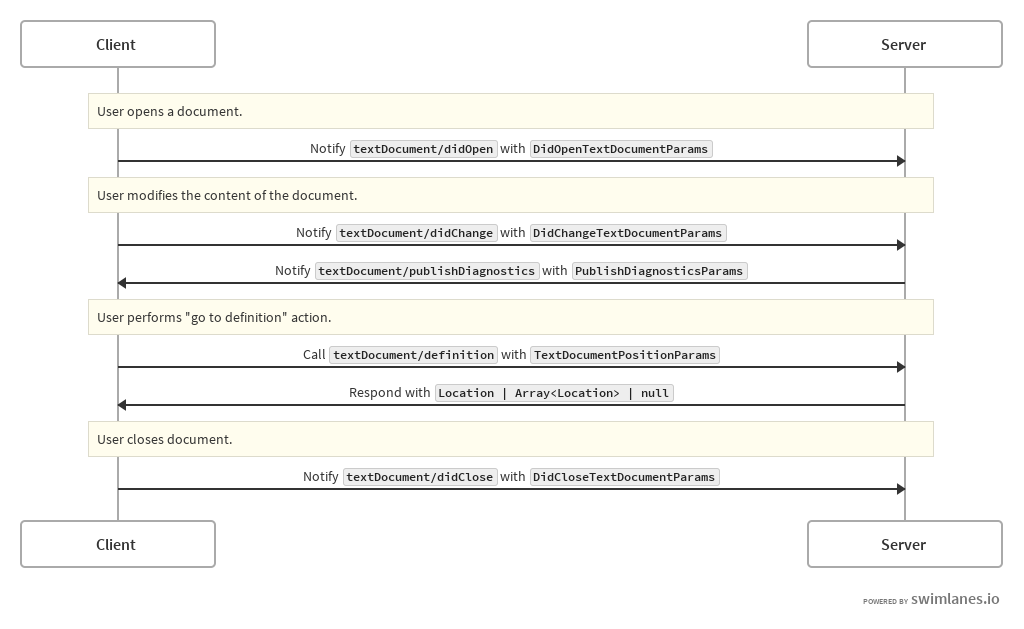
Right after the server started the client will send an initialization request. The client will then wait for a response, which will be acknowledged with a notification. Then standard notifications and requests / responses are exchanged until the client sends a shutdown request. The server, however, will not fully shutdown until it gets an Exit notification.
The following sequence diagram illustrates this base layer:

For the initialize request the interesting part is the exchange of capabilities. There are two good reasons:
- As the server we get to know what the client supports and how the client is configured; this influences how the server should handle things
- For the client we need to know what the server can do to avoid unnecessary calls without (successful) responses
One of the pieces of information the request information contains is the root path of the current project (if any). This will then help to determine the correct absolute paths when relative paths need to be resolved.
The delivered client capabilities are divided into two groups, namely single text document capabilities and full workspace capabilities. Experimental client capabilities (not further specified) can also be delivered. In this post we will only cover the text document capabilities.
One question that will arise at some point: Since LSP works mostly with text documents how is the support for binary documents given? Which binary encoding is used?
Well, the LSP answers these (and similar) questions quite simple and straight forward:
There is currently no support for binary documents.
So, we can only use the LSP with text-based files. Hence the name text documents.
More great articles from LogRocket:
- Don't miss a moment with The Replay, a curated newsletter from LogRocket
- Learn how LogRocket's Galileo AI watches sessions for you and proactively surfaces the highest-impact things you should work on
- Use React's useEffect to optimize your application's performance
- Switch between multiple versions of Node
- Discover how to use the React children prop with TypeScript
- Explore creating a custom mouse cursor with CSS
- Advisory boards aren’t just for executives. Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag
Coming back to the response we introduced earlier we may be now interested to see how simple the interface for the initialize response may look like:
interface InitializeResult {
capabilities: ServerCapabilities;
}
Here ServerCapabilities is really just an object with some (optional) pre-defined keys. Each key resolves to a known capability.
Here, we will only implement a single one. Let’s just assume we implement the hoverProvider capability, which gives clients the possibility of getting information at hover on parts of the open text document (e.g., documentation or symbol details).
As such the result snippet of the JSON-RPC response could look as follows:
{
"capabilities": {
"hoverProvider": true
}
}
How can an interaction look like where this capability is used? It all boils down to the textDocument/hover method, which is specified in the standard.
To demonstrate visually:

Here, the Hover inferface is specified to contain (optionally) the range to illustrate and the content(s) to show. Each content fragment is either a simple string or specifies a language (e.g., HTML) for rendering. The TextDocumentPositionParams is an interface that is used quite often.
It only contains two properties:
- A reference to the document in question (standard, is part of any
textDocument/*method), the reference is transported as a simple{ uri: string }object - The position of interest, which is the column / row position of the mouse pointer in case of hover
The position contains two properties, line (0-based) and character. The latter is tricky as it is really the cursor, which is always between two positions in a string. Thus a character value of 0 is right before the first character, while 1 is between the first and second character.
In fact, with the flow earlier shown a full (single document) flow looks more close to:
Armed with this knowledge secure in the back of our mind, let’s look at a sample server and its integration into a real client.
A sample server
For now, we’ll write a simple server for plain text files that has just a single capability: handling hover actions. For the sample we want to display a nicely formatted message with the actually hovered word. This should also give us some insights into the basic language server API or workflow.
For the following to work we need to install the vscode-languageserver NPM package. This package is (despite its name) not tightly bound to VSCode and can be easily used for general language servers. As I’ll explain in the next section, we will still need a dedicated extension for VSCode (mostly for the metadata information, but also for a couple of other reasons).
There are a couple of reasons for using the formerly mentioned NPM package. Obviously, it is a battle tested implementation of the language server protocol. It gives us nice syntax sugar to get going fast. Most notably, we don’t have to worry so much about:
- using the correct capability names (TS support is fully given),
- receiving (and using) the capabilities (again mostly TS),
- the whole initialization handshake incl. capability exchange,
- correctness to the LSP (and lower-level specifications such as JSON-RPC), and
- handling the whole connection
At last, let’s start with some basic functionality. For getting some text, we can use the following simple implementation. Note: the algorithm is obviously just a crude approximation and does not handle any edge case except line boundaries.
function getWord(text: string, at: number) {
const first = text.lastIndexOf(' ', index);
const last = text.indexOf(' ', index);
return text.substring(first !== -1 ? first : 0, last !== -1 ? last : text.length - 1);
}
The function will be used from our onHover handler. Before we can reach that, however, we need to establish the connection. So let’s define how this looks:
import {
IPCMessageReader,
IPCMessageWriter,
createConnection,
IConnection,
TextDocuments,
InitializeResult,
Hover,
} from 'vscode-languageserver';
const reader = new IPCMessageReader(process);
const writer = new IPCMessageWriter(process);
const connection: IConnection = createConnection(reader, writer);
const documents: TextDocuments = new TextDocuments();
documents.listen(connection);
connection.onInitialize((_params): InitializeResult => {
return {
capabilities: {
textDocumentSync: documents.syncKind,
hoverProvider: true
}
}
});
The connection is the vscode-languageserver abstraction over the LSP and the underlying JSON-RPC. It supports multiple kinds of connections, which are abstracted via the reader and writer. This even allows mixed combinations such as IPC readers and console writers.
Now we can implement the onHover method returning a Hover object in case we have something to respond. Otherwise, we just return undefined for simplicity. The connection.listen() at the end starts the actual connection.
// ...
connection.onHover(({ textDocument, position }): Hover => {
const document = documents.get(textDocument.uri);
const start = {
line: position.line,
character: 0,
};
const end = {
line: position.line + 1,
character: 0,
};
const text = document.getText({ start, end });
const index = document.offsetAt(position) - document.offsetAt(start);
const word = getWord(text, index);
if (word !== '') {
return {
contents: {
kind: 'markdown',
value: `Current word: **${word}**.`,
},
};
}
return undefined;
});
connection.listen();
Most importantly, we get the document via its identifier (unique through the uri) from the connected documents. The documents are a nice abstraction layer to take care of the otherwise repetitive task of managing the documents via didOpen and didClose like notifications. Nevertheless, it is important to realize that a document consists only of a few functions. Most of the functions just deal with position resolution to indices or vice versa.
Finally, we need a way to tell clients about our server. This is the point where we need to dive into writing VSCode extensions.
Extending the client
Several client implementations of the protocol exist. There are, as usual, some big players in the field. Important, as already stated beforehand clients also transport capabilities. Like servers, clients may also not support all capabilities of the LSP. Mostly, due to implementation time / focus, but sometimes also due to technical challenges, e.g., limitations in the plugin layer to integrate the LSP. The most known implementations exist for:
- Atom
- Emacs
- IntelliJ IDEs
- Sublime Text 3
- vim/neovim
- VSCode
It is no coincidence that this reads a bit like the “who’s who” of text editors and / or IDEs (with the exception of Visual Studio missing, which may be soon changed). The LSP really fulfills its promise to bring language services without less effort to more platforms, which is something any texteditor (or IDE) can profit from.
One reason why existing IDEs may be resistant to change is lack of profiling/debugging. Another may be required core architecture changes to allow using LSP-conform servers or extensions.
One of the unique selling points of a product like Visual Studio is that it comes with integrated language support that just feels native and the same for all supported languages. Using an open-source technology that will bring in a lot of different providers with different grades (and mindsets) of implementation will certainly degrade the standard user experience.
Also, since debugging is not part of the LSP, a huge fraction of the whole development process would still be missing, which makes it difficult for the marketing folks at Microsoft to sell this product.
Nevertheless, I think its fair to say that the advantages of supporting the LSP are much bigger than the unwanted side-effects. Once a standardized debugging server protocol (known as Debug Adapter Protocol, short DAP) is released a dynamic duo consisting of DAP and LSP would be here to stay.
Most clients could theoretically work with a language server nearly out of the box, however, there are some restrictions that still demand us writing some kind of glue layer (called a plugin):
- It makes it possible for users to actively decide if they want the server
- It actively transports data beyond the LSP (metadata relevant for the client)
- It enables creators of plugins to use multiple technologies, e.g., DAP and LSP integration with different sub-systems
- It allows the plugin to use more of the specific client, e.g., custom notifications, binding to commands, etc.
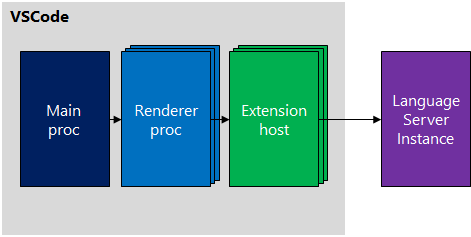
Now, we’ll look at a very simple plugin for VSCode. We will not go into many details, but rather follow KISS to just achieve the one thing we desire — integrate our sample server.
This diagram illustrates how extensions enable the different renderers to go beyond the Electron shell of VSCode; right to the external process via JSON-RPC.
The easiest way to get started with extensions in VSCode is to install the Yeoman generator (generator-code). We can then go ahead and create a new project using yo code. Not only will the basic boilerplate be available, but also interesting tooling aspects such as a valid launch.json that enables debugging the extension by just pressing F5. This command will open a new instance of VSCode with the extension in development being enabled and ready to be debugged.
In VSCode extensions the package.json contains the basic metadata to describe the extension. The metadata is used to, e.g., decide when to activate the extension. The activation is quite important as VSCode tries to be conservative about its resources and does not want to carry to full load of all extensions into every file.
For simplicity, we can just activate when a certain language is chosen. Here, let’s say our target is a plain text file (remember: in the end our simple language server will just repeat the currently highlighted word on hover).
{
// ...
"activationEvents": [
"onLanguage:plaintext"
]
}
As we started with the (empty) boilerplate our package.json only contains the bare minimum. To integrate a language server we should also add the vscode-languageclient NPM package. Let’s just add this to the devDependencies of our extension.
How does the actual extension look like? As specified in the main property of the package.json we have our root module (e.g., in src/extension.ts) of the VSCode extension. This one needs to export the activate function.
Activating a LSP compliant server is easily done via the previously mentioned vscode-languageclient package. It allows us to focus on what really matters; identifying the right application and setting up the different channels plus defining the VSCode related metadata.
The code is mostly self explanatory.
import { join } from 'path';
import { ExtensionContext } from 'vscode';
import { LanguageClient, LanguageClientOptions, ServerOptions, TransportKind } from 'vscode-languageclient';
export function activate(context: ExtensionContext) {
const serverModule = context.asAbsolutePath(join('server', 'server.js'));
const serverOptions: ServerOptions = {
run: {
module: serverModule,
transport: TransportKind.ipc,
},
debug: {
module: serverModule,
transport: TransportKind.ipc,
options: {
execArgv: ['--nolazy', '--inspect=6009'],
},
},
};
const clientOptions: LanguageClientOptions = {
documentSelector: [{
scheme: 'file',
language: 'plaintext',
}],
};
const client = new LanguageClient('hoverExample', 'Language Server Hover Example', serverOptions, clientOptions);
const disposable = client.start();
context.subscriptions.push(disposable);
}
The provided execution context is the only relevant part here. We use this one to tell VSCode about the created subscription, such that the resource is managed properly. VSCode will then send the necessary commands to ensure well-defined behavior.
Debugging the server can be done via a simple task in the launch.json (such a file is specific for VSCode and needs to be stored in the .vscode directory).
{
"name": "Attach to Server",
"type": "node",
"request": "attach",
"port": 6009,
"sourceMaps": true,
"outFiles": [
"${workspaceRoot}/out/**/*.js"
],
"preLaunchTask": "watch"
}
One important note: The “installation” of the server into our extension (if we want to create it within a single repository) is necessary and potentially (depending on the situation) not straight forward. The VSCode team has written a little helper installServerIntoExtension, which is part of the general language server tooling and thus already available if we have installed the prior packages.
A command such as the following will install the server from the current directory using its metadata and TypeScript configuration (for the build process) into the client-dir directory.
installServerIntoExtension ../client-dir ./package.json ./tsconfig.json
Alternatively, install the server via NPM or make a more proficient disk search. The crucial point is that the server is started in isolation and thus needs its own node_modules structure (among other things).

Having done all that VSCode can now blend in the information on hover that we provided. Time to integrate the language server also in another editor?
Conclusion
Knowledge of the LSP is not valuable simply in an academic sense. It can give us an edge in many different scenarios. Not only is the language server protocol a nice piece of technology, but it also uses other standards and technologies which are worth knowing about. Finally, using LSP gives us a great deal of potential reusability.
Obviously, we will not write our own IDE on a regular basis. However, tasks that involve some kind of language processing are quite standard. If all compilers / parsers would be (also) available in form of a LSP compliant tool, we can easily connect and use the functionality provided.
Where have you been in touch with LSP yet? What values do you like the most about LSP and its implementations? Any use cases we did not mention here? Please tell us in the comments!
References
- Languages
- LSP Specification
- JSON-RPC Specification
- Reference Implementation
- Docker LangServer
- A common interface for building developer tools
- Microsoft introduces open-source Language Server Protocol
- Debug Adapter Protocol Schema
- Debug Adapter Protocol Issue / Progress
- Example Language Server
- Writing VSCode Extensions





