The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Elasticsearch query body builder is a query DSL (domain-specific language) or client that provides an API layer over raw Elasticsearch queries. It makes full-text search data querying and complex data aggregation easier, more convenient, and cleaner in terms of syntax.

In this tutorial, we will learn how writing queries using the builder syntax offers more advantages over raw Elasticsearch queries. This is because raw queries can quickly become cumbersome, unstructured, less idiomatic, and even error-prone.
fWe are going to achieve this by leveraging elastic-builder, a query builder library. According to its documentation, it is a tool for quickly building request body for complex search queries and aggregation. Additionally, it conforms with the API specification standard of native Elasticsearch queries with no performance bottleneck whatsoever.
Essentially, this means we can write queries using the builder syntax, matching equivalent queries provided by native Elasticsearch. Not to worry — we will learn and understand the builder syntax as we progress with this tutorial.
To begin, let’s examine a simple example of a generic car query to understand why using ES query builder would make querying Elasticsearch data easier, and how it contributes to a faster development lifecycle.
{
"query": {
"bool": {
"must": {
"match": {
"Origin": "USA"
}
},
"filter": {
"range": {
"Cylinders": {
"gte": 4,
"lte": 6
}
}
},
"must_not": {
"range": {
"Horsepower": {
"gte": 75
}
}
},
"should": {
"term": {
"Name": "ford"
}
}
}
}
}
Looking at the above, we are running a query for a car whose origin is the USA, while performing a filter where the engine’s cylinders can be either greater than or equal to 4 or less than or equal to 6. Also, we are running a range query, where the horsepower of the car must not be greater than or equal to 75. Finally, the name of the car should be Ford.
Now, the problem with writing these kinds of queries are:
Now consider an equivalent of the above query using the builder syntax, shown below:
esb.requestBodySearch()
.query(
esb.boolQuery()
.must(esb.matchQuery('Origin', 'USA'))
.filter(esb.rangeQuery('Cylinders').gte(4).lte(6))
.should(esb.termQuery('Name', 'ford'))
.mustNot(esb.rangeQuery('Horsepower').gte(75))
)
The query above does exactly the same thing as the raw ES query we previously reviewed, and as we can see, this is more intuitive and intentional.
Here, we are making use of the requestBodySearch API from elastic-builder. This API helps us build and form queries that verbally represent and explain our intent in an even, smooth, idiomatic way. They are also very readable, and we can decide to add even more fields so as to obtain an entirely different query result, as the case may be.
In order to easily follow along with this tutorial, I would recommend going through this introductory tutorial on getting started with Elasticsearch and Node.js. Note that this action is only necessary if you lack prior experience working with Elasticsearch or if you want a little refresher on it. Otherwise, you should be able to follow this tutorial with ease.
For a start, ensure that you have Node.js and npm installed on your machine. Also, I would recommend that you download the Elasticsearch binaries and install them, just in case you intend to run it locally. However, for the purposes of this tutorial, we will be setting up Elasticsearch with Elastic Cloud, for which you can use a 14-day free trial.
After you’re done with the entire setup (like choosing a cloud provider and region of your choice, since it is a managed service), you should get a username (which most likely would be elastic), a password, a host and a port. Note that we will need these credentials or secrets to connect to our ES cluster later on.
Although the UI is quite intuitive, to have a visual cue of where to locate these parameters, here are some screenshots that point out where to look.
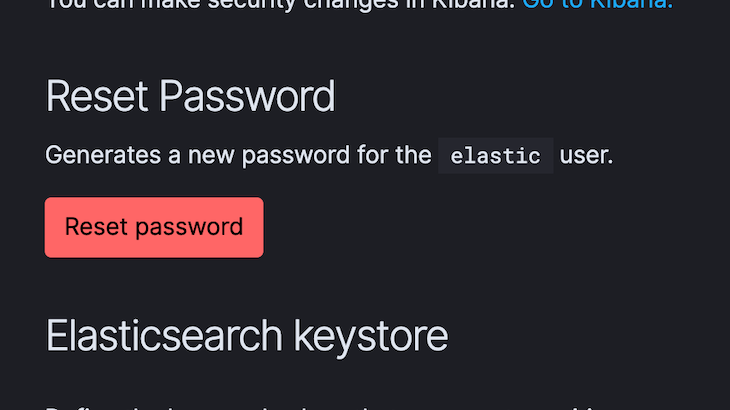
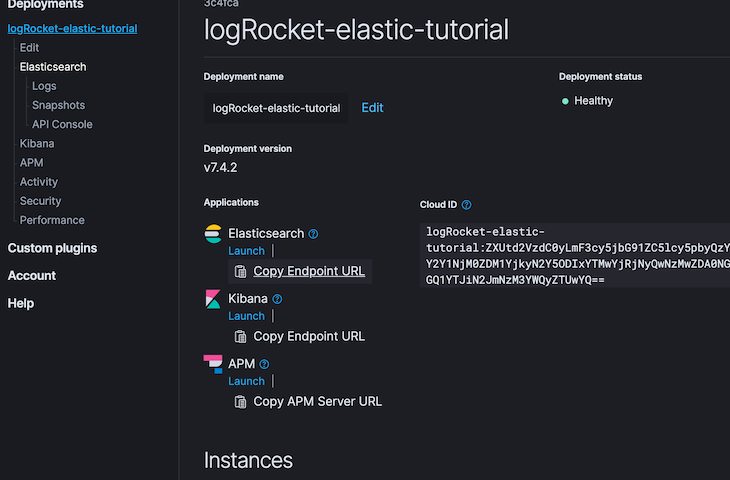
The first screenshot shows the Elasticsearch user and where we can find our password or generate a new password. The second screenshot shows a link where we can easily copy the elasticsearch endpoint url. After this setup, we should be good to go, except we intend to explore other Elasticsearch services in the stack like Kibana.
You can check out more information on Kibana and the entire Elastic stack. To proceed, let’s get a clear context on what we will be building.
In this tutorial, we are going to build a few API endpoints to demonstrate how to perform full-text search queries on data stored in our Elasticsearch cluster. Of course, we will be using the builder syntax to construct our queries and compare them alongside raw ES queries.
We can go ahead and create a new folder for our project and call it any name we want. As usual, before we begin a new Node.js project, we run npm init inside the project directory. This would create a new package.json file for us.
Then, we can go ahead and install our application dependencies. The dependencies we need for this project are the official Elasticsearch client for Node, the elastic-builder library, Express, body-parser, and the dotenv package.
To install them, we can run the following command in our terminal/command prompt:
npm install @elastic/elasticsearch body-parser dotenv elastic-builder express –save
After the installation, our package.json file should look like this:
{
"name": "logrocket_elasticsearch_tutorial",
"version": "1.0.0",
"description": "LogRocket ElasticSearch Tutorial with ES Builder",
"main": "index.js",
"scripts": {
"start": "node ./app/server.js"
},
"author": "Alexander Nnakwue",
"license": "ISC",
"dependencies": {
"@elastic/elasticsearch": "^7.4.0",
"body-parser": "^1.19.0",
"dotenv": "^8.2.0",
"elastic-builder": "^2.4.0",
"express": "^4.17.1"
}
}
Now we’ll proceed to create all the necessary files and folders we require. Note that the start script is based on the relative path of our server.js file. First, make sure you are inside the project directory, then run mkdir app to create a new folder called app.
After creating the app folder, we can then navigate into it and create all the necessary files, as shown in the screenshot below. Also, we can go ahead and create all the other files in the project’s root directory as shown.
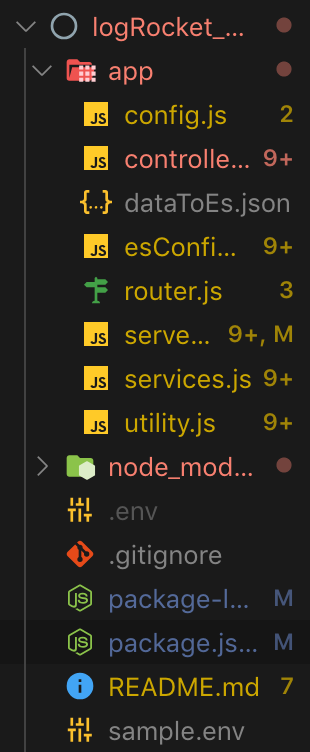
The next step is for us to create a connection to the Elasticsearch cluster. To do so, we will need to create a .env file to store all our environment variables or secrets. The sample.env file exactly mirrors what should be contained in our .env. The contents of the file are as follows:
ELASTICSEARCH_USERNAME=username ELASTICSEARCH_PASSWORD=password ELASTICSEARCH_HOST=host ELASTICSEARCH_PORT=port APP_PORT= 3004 ELASTICSEARCH_INDEX=index ELASTICSEARCH_TYPE=type
We can go ahead and copy these parameters, create a .env file in our project’s root directory, and fill in the real credentials. After that, we should be good to create our config.js file, which should provide access to the variables defined or added in our newly created .env file.
The config.js file should contain the following JSON:
const result = require('dotenv').config();
module.exports= {
es_host: process.env.ELASTICSEARCH_HOST,
es_pass: process.env.ELASTICSEARCH_PASSWORD,
es_port: process.env.ELASTICSEARCH_PORT,
es_user:process.env.ELASTICSEARCH_USERNAME,
es_index:process.env.ELASTICSEARCH_INDEX,
es_type:process.env.ELASTICSEARCH_TYPE,
app_port: process.env.APP_PORT
};
if (result.error) {
console.log(result.error, "[Error Parsing env variables!]");
throw result.error;
};
// console.log(result.parsed, '[Parsed env variables!]');
As we can see, we are getting access to the variables contained in the .env file and storing them with different variable names. Also note that we have added the app_port, es_index, es_type, and other variables needed for our Elasticsearch connection.
Now, let’s go ahead and connect to our Elasticsearch cluster with these parameters. To do so, we can copy the following to the esConfig.js file:
'use strict'
const { Client } = require('@elastic/elasticsearch');
const config = require('./config');
const client = new Client({ node: `https://${config.es_user}:${config.es_pass}@${config.es_host}:${config.es_port}`});
module.exports.esClient= client;
Here we are adding a reference to the official Elasticsearch Node.js client library, then we are using the contents contained in our config.js file created earlier to instantiate a new ES client connection to our cluster.
Now that our cluster is set up, we can go ahead and create a new file that contains the JSON data we intend to write to our Elasticsearch index. We can go ahead and create the new file, dataToEs.json, if we haven’t done so earlier. The contents of the file can be credited to this source on GitHub. It basically contains the JSON-based dataset we will be writing to our ES index based on the given parameters required to connect to our cluster.
After we are done with the above, we can create a utility.js file, which would contain the functions required to create our ES index; create a new mapping based on the available fields with their respective data types for our datasets; and then, finally, write the JSON data to the index we created on our cluster.
Note that Elasticsearch is schemaless by default, but we can go ahead and define our own schema beforehand to help define a standard structure and format for our data. This, of course, has its own advantages, like data uniformity and so on. Now let’s understand what is going on in the utility.js file:
const fs = require('fs');
const esconfig = require('./esConfig');
const client = esconfig.esClient;
const data = JSON.parse(fs.readFileSync(__dirname + '/dataToEs.json'));
const config = require('./config');
const index= config.es_index;
const type = config.es_type;
async function writeCarDataToEs(index, data){
for (let i = 0; i < data.length; i++ ) {
await client.create({
refresh: true,
index: index,
id: i,
body: data[i]
}, function(error, response) {
if (error) {
console.error("Failed to import data", error);
return;
}
else {
console.log("Successfully imported data", data[i]);
}
});
}
};
async function createCarMapping (index, type) {
const carSchema = {
"Acceleration": {
"type": "long"
},
"Cylinders": {
"type": "long"
},
"Displacement": {
"type": "long"
},
"Horsepower": {
"type": "long"
},
"Miles_per_Gallon": {
"type": "long"
},
"Name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"Origin": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"Weight_in_lbs": {
"type": "long"
},
"Year": {
"type": "date"
}
}
return client.indices.putMapping({index, type, body:{properties:carSchema}});
}
module.exports = {
async resetIndex(){
if (client.indices.exists({ index })) {
client.indices.delete({ index });
}
client.indices.create({ index });
createCarMapping(client, index, type);
writeCarDataToEs(index, data);
}
};
In the file above, we are first dynamically reading the JSON data contained in the dataToEs.json file we talked about earlier. As shown, we have made use of the native filesystem package for Node.js.
We are also making use of __dirname to get access to the directory name of the current module and appending the relative file path of the dataset to it. Additionally, we are importing a reference to our ES client connection. The first function, writeCarDataToEs, loops through the entire JSON dataset and writes it to our Elasticsearch index.
Note that there is a caveat here, as for very large datasets, we should instead make do with the ES bulk API instead of the create API. However, for our current use case, this should work fine. To see how to use the ES bulk API, you can check the official example provided in this GitHub repo.
After that, we can now create mappings for our data, which represent the expected data type and format. We do so by calling the putMapping API while passing the index, type, and the JSON body.
Lastly, we create the function resetIndex, which checks if the index we are trying to create already exists and, if it does, deletes it for us. Otherwise, we create a new index with the name we pass from our env variable, create the mappings for our JSON dataset, and call the writeDataToEs() function, which then writes the data to the index in accordance with the mappings already specified.
Now we can go ahead and create our server.js file, which is basically a simple Express server.
const express = require('express');
const bodyParser = require('body-parser')
require("dotenv").config();
require("./utility").resetIndex();
const app = express();
const esconfig = require('./esConfig');
const client = esconfig.esClient;
const router = require("./router");
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json());
app.use("/",router);
app.set('port', process.env.APP_PORT || 3000);
client.ping({}, function(error) {
if (error) {
console.log('ES Cluster is down', error);
} else {
console.log('ES Cluster is up!');
}
});
app.listen(app.get('port'), ()=>{
console.log(`Express server listening on port, ${app.get('port')}`);
} );
Here, we are importing the resetIndex() function from the utility.js file, which will make it run automatically when we spin up our app. We can decide to comment that import out, as it won’t be needed for subsequent app restarts since we should already have our index, mappings, and data all created and set up in our ES cluster.
Now we can get to writing queries for our data. Let’s begin by writing a multiple match query that matches a car’s name and its origin, while its weight is greater than or equal to a particular number (rangeQuery). We can check out the service.js file to understand how this query works:
async fetchMatchMultipleQuery(origin, name,weight){
const requestBody = esb.requestBodySearch()
.query(
esb.boolQuery()
.must([
esb.matchQuery(
'Origin', origin,
),
(
esb.matchQuery(
'Name', name,
)
),
])
.filter(esb.rangeQuery('Weight_in_lbs').gte(weight))
)
return client.search({index: index, body: requestBody.toJSON()});
}
Looking at the above function, it is quite clear what we are trying to achieve. This query is a boolean that must match cars from a particular origin and a specific name. Also, we are filtering the cars using a range query, where the weight must be greater than or equal to the particular weight we specify.
As an aside, let’s take a look at the equivalent raw query for the above:
{
"bool": {
"must": [
{
"match": {
"Origin": "https://elastic-builder.js.org"
}
},
{
"match": {
"Name": "name"
}
}
],
"filter": {
"range": {
"Weight_in_lbs": {
"gte": "weight"
}
}
}
}
}
As we can see, this is prone to mistakes due to the deeply nested nature of the query, which we pointed out earlier. Now that we have a visual cue for this, let’s understand the flow in actually calling this API.
First of all, check out the services.js file. This file handles everything related to building our queries using the builder syntax, and then calling our ES client to actually perform those calls. Also, inside the file, we fill find the same function above.
The controller.js file takes care of routing our requests based on the app route specified in the routes.js file. When requests are routed, the functions in the controller.js file call those in the services.js files.
Let’s illustrate this with a simple example. For the previous query defined above, the corresponding call in the controller file is shown below:
async fetchMatchMultipleQuery(req,res) {
const origin = req.query.Origin;
const name = req.query.Name;
const weight = req.query.Weight_in_lbs;
try {
const result = await Services.fetchMatchMultipleQuery(origin, name, weight);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({status_code: 200, success: true, data: data, messsage: "fetch match query for multiple requests successful!" });
} catch (err) {
res.json({status_code: 500, success: false, data: [], message: err});
}
}
Subsequently, the routing for this call is contained in the routes.js file:
routes.route("/search-by-multiple").get(controller.fetchMatchMultipleQuery);
We can now go ahead and test our implementation. First, let’s start our server by running npm start. Then we can visit this URL to run our query with the provided filters: name, origin, and weight_in_lbs.
http://localhost:3000/search-by-multiple?Name=ford&Origin=USA&Weight_in_lbs=3000
Note that the request above is a GET request, and the parameters after the URL are the query parameters required to give us our desired filtered results. The results for the API call are shown below:
{
"status_code": 200,
"success": true,
"data": [
{
"id": "221",
"data": {
"Name": "ford f108",
"Miles_per_Gallon": 13,
"Cylinders": 8,
"Displacement": 302,
"Horsepower": 130,
"Weight_in_lbs": 3870,
"Acceleration": 15,
"Year": "1976-01-01",
"Origin": "USA"
}
},
{
"id": "99",
"data": {
"Name": "ford ltd",
"Miles_per_Gallon": 13,
"Cylinders": 8,
"Displacement": 351,
"Horsepower": 158,
"Weight_in_lbs": 4363,
"Acceleration": 13,
"Year": "1973-01-01",
"Origin": "USA"
}
},
{
"id": "235",
"data": {
"Name": "ford granada",
"Miles_per_Gallon": 18.5,
"Cylinders": 6,
"Displacement": 250,
"Horsepower": 98,
"Weight_in_lbs": 3525,
"Acceleration": 19,
"Year": "1977-01-01",
"Origin": "USA"
}
},
{
"id": "31",
"data": {
"Name": "ford f250",
"Miles_per_Gallon": 10,
"Cylinders": 8,
"Displacement": 360,
"Horsepower": 215,
"Weight_in_lbs": 4615,
"Acceleration": 14,
"Year": "1970-01-01",
"Origin": "USA"
}
},
"messsage": "fetch match query for multiple requests successful!"
}
Note that the above query result has been truncated for brevity. When we run this query locally, you should get the entire result. Not to worry, the link to the collections on POSTMAN is here. You can copy it, import it to your POSTMAN, and test as well.
The entire code for the services.js file, which contains all the queries made to our data in the cluster, is shown below:
const esconfig = require('./esConfig');
const client = esconfig.esClient;
const config = require('./config');
const index = config.es_index;
const esb = require('elastic-builder'); //the builder
module.exports = {
async search(){
const requestBody = esb.requestBodySearch()
.query(esb.matchAllQuery())
.size(10)
.from(1);
return client.search({index: index, body: requestBody.toJSON()});
},
async filterCarsByYearMade(param) {
const requestBody = esb.requestBodySearch()
.query(
esb.boolQuery()
.must(esb.matchAllQuery())
.filter(esb.rangeQuery('Year').gte(param).lte(param))
)
.from(1)
.size(5);
return client.search({index: index, body: requestBody.toJSON()});
},
async filterCarsByName(param) {
const requestBody = esb.requestBodySearch()
.query(
esb.termQuery('Name', param))
.sort(esb.sort('Year', 'asc')
)
.from(1)
.size(10);
return client.search({index: index, body: requestBody.toJSON()});
},
async fetchCarByName(param) {
const requestBody = esb.requestBodySearch()
.query(
esb.boolQuery()
.must(esb.matchPhraseQuery('Name', param))
);
return client.search({index: index, body: requestBody.toJSON()});
},
async fetchMatchMultipleQuery(origin, name,weight){
const requestBody = esb.requestBodySearch()
.query(
esb.boolQuery()
.must([
esb.matchQuery(
'Origin', origin,
),
(
esb.matchQuery(
'Name', name,
)
),
])
.filter(esb.rangeQuery('Weight_in_lbs').gte(weight))
)
return client.search({index: index, body: requestBody.toJSON()});
},
async aggregateQuery(origin,cylinder,name,horsePower) {
const requestBody = esb.requestBodySearch()
.query(
esb.boolQuery()
.must(esb.matchQuery('Origin', origin))
.filter(esb.rangeQuery('Cylinders').gte(cylinder))
.should(esb.termQuery('Name', name))
.mustNot(esb.rangeQuery('Horsepower').gte(horsePower))
// .agg(esb.avgAggregation('avg_miles', 'Miles_per_Gallon'))
)
return client.search({index: index, body: requestBody.toJSON()});
},
};
As we can see in the file above, the queries are quite readable and easy to grasp. We have made use of the matchQuery, rangeQuery, termQuery, matchPhraseQuery, boolQuery, and matchAllQuery queries provided by the builder library. For other available queries and how to use them, we can check out the query sections of the elastic-builder documentation.
The sort command, as the name implies, sorts the queries in either an ascending or descending order, whatever the case may be. The from and size parameters help with controlling the output of our data by paginating the returned result.
Also, the code for the controller.js file is shown below:
const Services = require('./services');
module.exports = {
async search(req, res) {
try {
const result = await Services.search();
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({ status_code: 200, success: true, data: data, message: "Cars data successfully fetched!" });
} catch (err) {
res.json({ status_code: 500, success: false, data: [], message: err});
}
},
async filterCarsByYearMade(req, res) {
let {year} = req.query;
try {
const result = await Services.filterCarsByYearMade(year);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({ status_code: 200, success: true, data: data, message: "Filter Cars by year made data fetched successfully" });
} catch (err) {
res.json({ status_code: 500, success: false, data: [], message: err});
}
},
async filterCarsByName(req,res) {
let param = req.query.Name;
try {
const result = await Services.filterCarsByName(param);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({status_code: 200, success: true, data:data , message: "Filter cars by name data fetched successfully!" });
} catch (err) {
res.json({ status_code: 500, success: false, data: [], message: err});
}
},
async filterCarByName(req,res) {
const param = req.query.Name;
try {
const result = await Services.fetchCarByName(param);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({ status_code: 200, success: true, data: data , message: "Filter a car by name query data fetched successfully!"});
} catch (err) {
res.json({ status_code: 500, success: false, data: [], message: err});
}
},
async fetchMatchMultipleQuery(req,res) {
const origin = req.query.Origin;
const name = req.query.Name;
const weight = req.query.Weight_in_lbs;
try {
const result = await Services.fetchMatchMultipleQuery(origin, name, weight);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({status_code: 200, success: true, data: data, messsage: "fetch match query for multiple requests successful!" });
} catch (err) {
res.json({status_code: 500, success: false, data: [], message: err});
}
},
async aggregateQuery(req,res) {
const origin = req.query.Origin;
const cylinder = req.query.Cylinder;
const name = req.query.Name;
const horsePower = req.query.Horsepower;
try {
const result = await Services.aggregateQuery(origin, cylinder, name, horsePower);
const data = result.body.hits.hits.map((car)=>{
return {
id: car._id,
data: car._source
}
})
res.json({ status_code: 200, success: true, data: data, message: "Data successfully fetched!" });
} catch (err) {
res.json({ status_code: 500, success: false, data: [], message: err});
}
},
}
The above file contains the code that calls our services.js file and helps route the requests. As we can see, for each query above, we are doing a map on the returned data and outputting the id and the _source fields alone.
The routes for all the queries as contained in the routes.js file are shown below:
const express = require("express");
const controller = require("./controller");
const routes = express.Router();
routes.route("/search-all").get(controller.search);
routes.route("/search-by-year").get(controller.filterCarsByYearMade);
routes.route("/search-by-name").get(controller.filterCarsByName);
routes.route("/search-by-name-single").get(controller.filterCarByName);
routes.route("/search-by-multiple").get(controller.fetchMatchMultipleQuery);
routes.route("/seach-avg-query").get(controller.aggregateQuery);
module.exports = routes;
This file helps in calling and routing all the functions provided in the controller.js file. Note that the entire code for this project can be found on GitHub.
Elasticsearch is necessary if we intend to perform data aggregation, metrics, complex filters, and full-text search capabilities for highly search-intensive applications. The bonus here is that we have been able to go a step further and build upon writing your own search engine using Node.js and Elasticsearch by extending our queries with the builder syntax to write even more advanced queries and filters for our dataset.
While there are other builder libraries out there, elastic-builder is quite reliable, stable, and has a clear, readable, easily understandable syntax.
In case you have any questions, feedback, or comments on this piece, please don’t hesitate to reply in the comments section below or reach out to me on Twitter. Thank you for taking the time to read!
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Why the future of DX might come from the web platform itself, not more tools or frameworks.

A hands-on test of Claude Code Review across real PRs, breaking down what it flagged, what slipped through, and how the pipeline actually performs in practice.

CSS art once made frontend feel playful and accessible. Here’s why it faded as the web became more practical and prestige-driven.

Learn how inline props break React.memo, trigger unnecessary re-renders, and hurt React performance — plus how to fix them.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

