Currently, if we want to use HTTP caching in GraphQL, we must use a GraphQL server that supports persisted queries. That’s because the persisted query will already have the GraphQL query stored in the server; as such, we do not need to provide this information in our request.

In order for GraphQL servers to also support HTTP caching via the single endpoint, the GraphQL query must be provided as a URL param. The GraphQL over HTTP specification will hopefully achieve this goal, providing a standardized language for all GraphQL clients, servers, and libraries to interact with each other.
I suspect, though, that all attempts to pass a GraphQL query via a URL param will be far from ideal. This is because a URL param must be provided as a single-line value, so the query will either need to be encoded or reformatted, making it difficult to understand (for us humans, not for machines).
For instance, this is how a GraphQL query looks when replacing all line breaks with spaces to make it fit within a single line:
{ posts(limit:5) { id title @titleCase excerpt @default(value:"No title", condition:IS_EMPTY) author { name } tags { id name } comments(limit:3, order:"date|DESC") { id date(format:"d/m/Y") author { name } content } } }
Can you make sense of it? Me neither.
And this is how the GraphiQL client encodes the simple query { posts { id title } } as a URL param:
%7B%0A%20%20posts%20%7B%0A%20%20%20%20id%0A%20%20%20%20title%0A%20%20%7D%0A%7D
Once again, we don’t know what’s going on here.
Both these examples evince the issue: single-line GraphQL queries can work from a technical point of view, transmitting the information to the server, but it is not easy for people to read and write those queries.
Being able to operate with single-line queries would have many benefits. For instance, we could compose the query directly in the browser’s address bar, doing away with the need for some GraphQL client.
It is not that I dislike GraphQL clients — indeed, I love GraphiQL. But I do dislike the idea that I depend on them.
In other words, we could benefit from a query syntax that allows people to:
This is a formidable challenge. But it is not insurmountable.
In this article, I will introduce an alternative syntax, which supports being “easy to read and write in a single line” by us humans.
I am not really proposing introducing this syntax to GraphQL — I understand that would never happen. But the design process for this syntax can, nevertheless, exemplify what we must pay attention to when designing the GraphQL over HTTP specification.
Let’s first explore what the issue is with the GraphQL syntax and then generalize it to other syntaxes.
As I see it, the difficulty comes from fields in a GraphQL query being nested, wherein the nesting can advance and retreat throughout the query. It is this coming-and-going behavior that makes it hard to grasp when written in a single line.
If the nesting in the query only advances, then it’s not so difficult to understand it. Take this query, for instance:
{
posts {
id
title
excerpt
comments {
id
date
content
author {
id
name
url
posts {
id
title
}
}
}
}
}
Here, the nesting only goes forward:
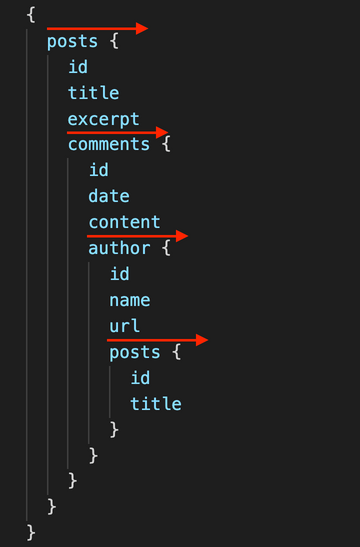
When looking over the always-going-forward query, and scanning it from left to right, we can still understand to what entity every field belongs:
{ posts { id title excerpt comments { id date content author { id name url posts { id title } } } } }
Now, consider the same GraphQL query, but rearranging the fields so that leaves appear after connections:
{
posts {
id
comments {
id
date
author {
posts {
id
title
}
id
name
url
}
content
}
title
excerpt
}
}
In this case, we can say that fields advance and also retreat:
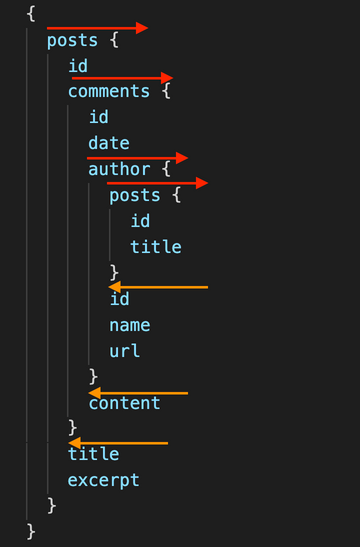
This query can be written in a single line, like this:
{ posts { id comments { id date author { posts { id title } id name url } content } title excerpt } }
Now, understanding the query is not so easy anymore. After a retreating level (i.e., right after a connection), we might not remember which entity came before it, so we won’t grasp where the field belongs:

(I guess this is related to the human brain having a limited short-term memory, able to hold not more than a few items at a time.)
And when there are many levels of going forward and back, then it becomes quite impossible to fully grasp. This query is understandable:
{
posts {
id
comments {
id
date
children {
id
author {
name
url
}
content
}
author {
posts {
id
title
tags {
name
}
}
id
name
friends {
id
name
}
url
}
content
}
title
excerpt
}
author {
name
}
}
But there’s no way we can make sense of its single-line equivalent:
{ posts { id comments { id date children { id author { name url } content } author { posts { id title tags { name } } id name friends { id name } url } content } title excerpt } author { name } }
In conclusion, GraphQL queries cannot be easily represented in a single-line, in such a way that we humans can make sense of it, because of its nesting behavior.
The issue is not specific to GraphQL. Indeed, it will happen for a syntax — any syntax — where the elements advance and retreat.
Take JSON, for instance:
{
"name": "leoloso/PoP",
"description": "PoP monorepo",
"repositories": [
{
"type": "package",
"package": {
"name": "leoloso-pop-api-wp/newsletter-subscriptions-rest-endpoints",
"version": "master",
"type": "wordpress-plugin",
"source": {
"url": "https://gist.github.com/leoloso/6588f6c1bdcce82fc317052616d3dfb4",
"type": "git",
"reference": "master"
}
}
},
{
"type": "package",
"package": {
"name": "leoloso-pop-api-wp/disable-user-edit-profile",
"version": "0.1.1",
"type": "wordpress-plugin",
"source": {
"url": "https://gist.github.com/leoloso/4e367eb8d8014a7aa7580567608bd5b4",
"type": "git",
"reference": "master"
}
}
},
{
"type": "vcs",
"url": "https://github.com/leoloso/wp-muplugin-loader.git"
}
],
"minimum-stability": "dev",
"prefer-stable": true,
"require": {
"php": "~8.0",
"getpop/api-rest": "dev-master",
"getpop/engine-wp-bootloader": "dev-master"
},
"extra": {
"branch-alias": {
"dev-master": "1.0-dev"
},
"installer-types": [
"graphiql-client",
"graphql-voyager"
],
"installer-paths": {
"wordpress/wp-content/mu-plugins/{$name}/": [
"type:wordpress-muplugin"
],
"wordpress/wp-content/plugins/{$name}/": [
"type:wordpress-plugin",
"getpop/engine-wp-bootloader"
]
}
},
"config": {
"sort-packages": true
}
}
Converting it to a single line makes it really difficult to comprehend:
{ "name": "leoloso/PoP", "description": "PoP monorepo", "repositories": [ { "type": "package", "package": { "name": "leoloso-pop-api-wp/newsletter-subscriptions-rest-endpoints", "version": "master", "type": "wordpress-plugin", "source": { "url": "https://gist.github.com/leoloso/6588f6c1bdcce82fc317052616d3dfb4", "type": "git", "reference": "master" } } }, { "type": "package", "package": { "name": "leoloso-pop-api-wp/disable-user-edit-profile", "version": "0.1.1", "type": "wordpress-plugin", "source": { "url": "https://gist.github.com/leoloso/4e367eb8d8014a7aa7580567608bd5b4", "type": "git", "reference": "master" } } }, { "type": "vcs", "url": "https://github.com/leoloso/wp-muplugin-loader.git" } ], "minimum-stability": "dev", "prefer-stable": true, "require": { "php": "~8.0", "getpop/api-rest": "dev-master", "getpop/engine-wp-bootloader": "dev-master" }, "extra": { "branch-alias": { "dev-master": "1.0-dev" }, "installer-types": [ "graphiql-client", "graphql-voyager" ], "installer-paths": { "wordpress/wp-content/mu-plugins/{$name}/": [ "type:wordpress-muplugin" ], "wordpress/wp-content/plugins/{$name}/": [ "type:wordpress-plugin", "getpop/engine-wp-bootloader" ] } }, "config": { "sort-packages": true } }
What’s more, when the syntax uses spacing to nest its elements, it won’t be even possible to write it in a single line.
That’s the case, for instance, with YAML:
services:
_defaults:
public: true
autowire: true
autoconfigure: true
PoPAPIPersistedQueriesPersistedQueryManagerInterface:
class: PoPAPIPersistedQueriesPersistedQueryManager
# Override the service
PoPComponentModelSchemaFieldQueryInterpreterInterface:
class: PoPAPISchemaFieldQueryInterpreter
PoPAPIHooks:
resource: '../src/Hooks/*'
I will describe the design for an alternative to the GraphQL syntax: the PQL syntax, used by GraphQL by PoP (the GraphQL server in PHP that I’ve authored) to accept URL-based queries passed via GET.
Since the problem with the GraphQL syntax arises from retreating nested fields, the solution seems evident: the flow of the query must be always-forward.
How does PQL achieve this? In order to demonstrate, let’s explore the PQL syntax.
In GraphQL, a field is written like this:
{
alias:fieldName(fieldArgs)@fieldDirective(directiveArgs)
}
In PQL, a field is written like this:
fieldName(fieldArgs)[@alias]<fieldDirective(directiveArgs)>
So it’s quite similar, but there are a few differences:
:, but with @ (and, optionally, surrounded by [...] for “bookmarks,” explained later on)@, but surrounded with <...>These differences are directly related to the always-forward flow required for the query.
In my own experience, when writing queries directly in the browser’s address bar, I always think of the need for the alias after having written the field name, not before. Therefore, using the order as in GraphQL, I had to backtrack to that position (pressing the left arrow key), add the alias, and go back to the final position (pressing the right arrow key).
That was quite cumbersome. It made much more sense to place the alias after the field name, making it a natural flow.
When defining the alias after the field name, it doesn’t make sense anymore to use :. This symbol is used by GraphQL to have the JSON response respect the shape of the query. Once the order between field and alias is inverted, using @ seems a natural fit.
This, in turn, meant we couldn’t use @ to identify directives anymore. Instead, I chose a surrounding syntax <...> (e.g., <directiveName>) so that directives can also be nested (e.g., <directive1<directive2>>), making it possible for GraphQL by PoP to support the composable directives feature.
In GraphQL, we can add two or more fields by adding a space or line break between them:
{
foo
bar
}
In PQL, we use the character | to separate fields:
foo|bar
We can already visualize how the query is composed as a single line:
{} charsWe can also appreciate that the query can be composed directly in the browser, passed via URL param query.
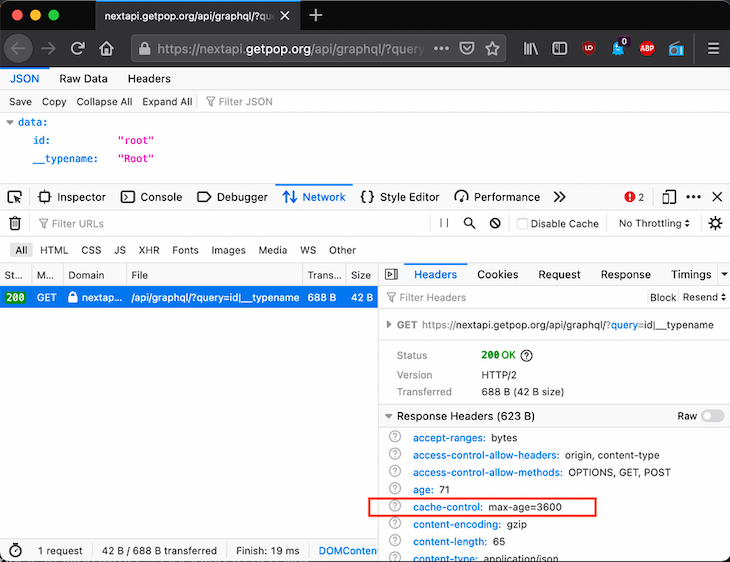
For instance, the URL to execute query id|__typename is: ${endpoint}?query=id|__typename.
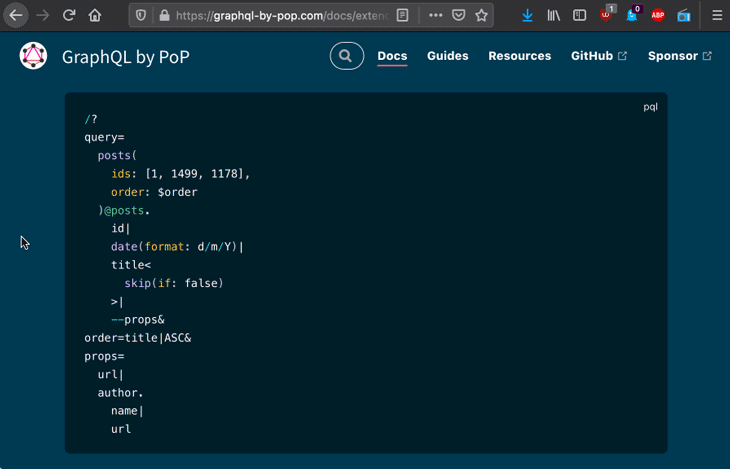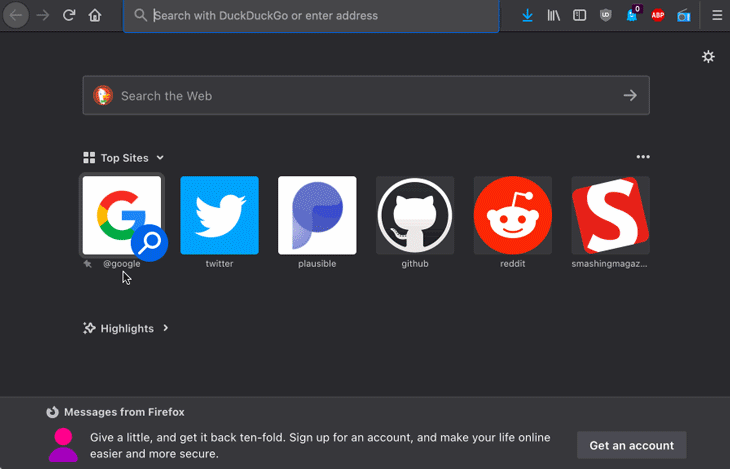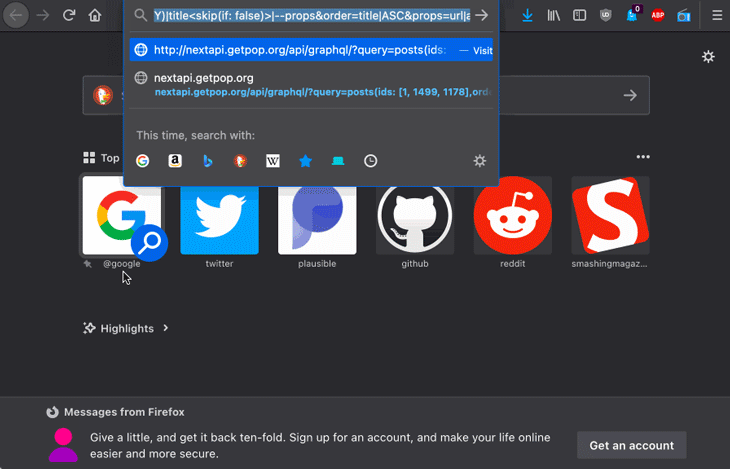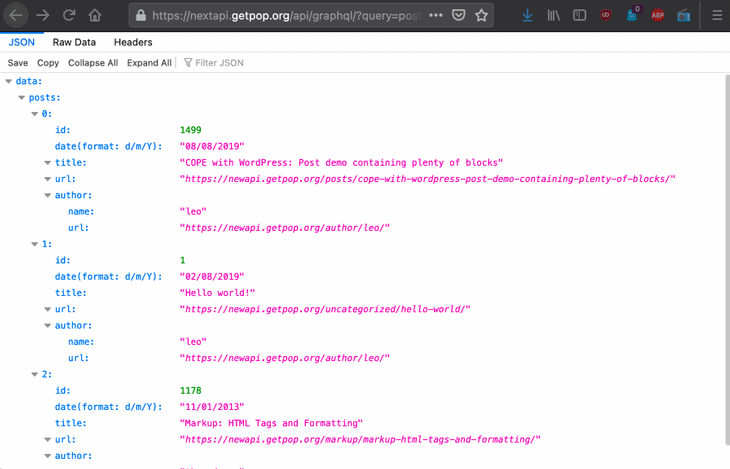
Using DevTools, we can see how HTTP caching is supported for the GraphQL single endpoint:
For all queries demonstrated below, there will be a link Execute query in browser. Click on them to visualize how PQL works on an actual site in production.
Similar to GraphQL, newlines (and also spaces) add no semantic meaning. Thus, we can conveniently add line breaks to help visualize the query:
foo| bar
When using Firefox, this query can be copied (from a text editor, a webpage, etc.) and pasted into the browser’s address bar, and all line breaks will be automatically removed, creating the equivalent single-line query.
GraphQL uses characters {} to define data for connections:
{
posts {
author {
id
}
}
}
In PQL, the query only advances, never retreats. So there is an equivalent for {, which is ., but there is no equivalent for } since it will not be needed.
posts.
author.
id
We can combine | and . to fetch multiple fields for any entity. Consider this GraphQL query:
{
posts {
id
title
author {
id
name
url
}
}
}
Its equivalent in PQL would be:
posts.
id|
title|
author.
id|
name|
url
At this point, we can face the challenge: How does PQL accept only advancing fields?
The queries seen above were always advancing. Let’s now tackle queries that also need to retreat, like this GraphQL query:
{
posts {
id
author {
id
name
url
}
comments {
id
content
}
}
}
PQL makes use of character , to join elements. It is similar to | for joining fields, but with a fundamental difference: the field to the right of , starts traversing the graph again from the root.
Then, the query above has this equivalent in PQL:
posts.
id|
author.
id|
name|
url,
posts.
comments.
id|
content
Notice how, to make it visually appealing, name| and url have the same padding to their left since | keeps their same path posts.author.. But there is no left padding right after , because the query starts again from the root.
We may think that this query does also retreat:
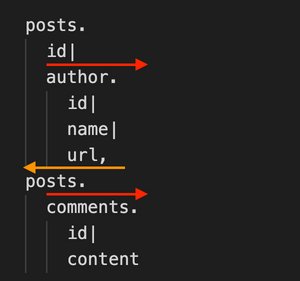
However, this not so much a retreat as it is a “reset.” In GraphQL, we can go back to the previous position in the query — i.e., the parent node in the graph — as many times as levels down we have traversed. In PQL, though, we can’t: we always go back all the way up to the root of the graph.
Starting from the root again, we must once again specify the complete path to the node to keep adding fields. This makes the query more verbose. For instance, the posts path in the query above appears once in GraphQL but twice in PQL.
This redundancy forces us humans to recreate the path when reading and writing the query for every level in the graph. Doing so allows us to understand the query when expressed in a single line:
posts.id|author.id|name|url,posts.comments.id|content
Because we’re recreating the path anew in our heads, we don’t suffer the short-term memory problem that causes us to get lost when looking at the GraphQL query.
Having to recreate the whole path to the node may become a nuisance.
Consider this GraphQL query:
{
users {
posts {
author {
id
name
}
comments {
id
content
}
}
}
}
And its equivalent in PQL:
users.
posts.
author.
id|
name,
users.
posts.
comments.
id|
content
To retrieve the comments field, we again need to add users.posts.. The further the level down the graph, the longer the path to replicate.
To address this issue, PQL introduces a new concept: a “bookmark,” which provides a shortcut to an already-traversed path so we can conveniently keep loading data from that point on.
We define a bookmark by enclosing its name with [...] when iterating down some path, and then that path is automatically retrieved when referencing its bookmark, again by enclosing its name with [...], from the root of the query.
In the query above, we can bookmark users.posts as [userposts]:
users.
posts[userposts].
author.
id|
name,
[userposts].
comments.
id|
content
To make it easier to visualize, we can also add the equivalent padding to the left of the applied bookmark, matching the same padding of its path (so that comments appears below posts):
users.
posts[userposts].
author.
id|
name,
[userposts].
comments.
id|
content
With bookmarks, we can still understand the query when expressed in a single line:
users.posts[userposts].author.id|name,[userposts].comments.id|content
If we need to define both a bookmark and an alias, we can have the @ symbol embedded within the [...]:
users.
posts[@userposts].
author.
id|
name,
[userposts].
comments.id|
content
In GraphQL, String values in field arguments must be enclosed with quotes "...":
{
posts {
id
title
date(format: "d/m/Y")
}
}
Having to type those quotes when composing the query in the browser proved very annoying; I would often forget them and then have to navigate left and right with the arrow keys to add them.
Hence, in PQL, string quotes can be omitted:
posts. id| title| date(format:d/m/Y)
String quotes are necessary when the query would otherwise be disrupted:
posts. id| title| date(format:"d M, Y")
In addition, the field argument could sometimes be made implicit; for instance, when the field has only one field argument. In this case, PQL allows omitting it:
posts. id| title| date(d/m/Y)
In GraphQL the variables are defined within the body of the request as an encoded JSON:
{
"query":"query ($format: String) {
posts {
id
title
date(format: $format)
}
}",
"variables":"{
"format":"d/m/Y"
}"
}
Instead, PQL uses the HTTP standard inputs, passing variables via $_GET or $_POST:
?query=
posts.
id|
title|
date($format)
&format=d/m/Y
We can also pass variables under input variables:
?query=
posts.
id|
title|
date($format)
&variables[format]=d/m/Y
GraphQL employs fragments to reuse query sections:
{
users {
...userData
posts {
comments {
author {
...userData
}
}
}
}
}
fragment userData on User {
id
name
url
}
In PQL, fragments follow the same method as variables for their definition: as inputs in $_GET or $_POST. They are referenced with --:
?query=
users.
--userData|
posts.
comments.
author.
--userData
&userData=
id|
name|
url
The fragment can also be defined under input fragments:
?query=
users.
--userData|
posts.
comments.
author.
--userData
&fragments[userData]=
id|
name|
url
PQL is a superset of the GraphQL query syntax. Thus, any query written using the standard GraphQL syntax can also be written in PQL.
Conversely, not every query written in PQL can be written using the GraphQL syntax because PQL supports features such as composable fields and composable directives that are not supported by GraphQL.
PQL comprises most of the same elements:
The elements it does not support are:
on element, to indicate what type/interface a fragment must be applied onEven though these elements are not supported, their underlying functionality is supported via a different method.
The operation is missing because there’s no need for it anymore: we now have the option to request the query using either GET (for queries) or POST (for mutations).
The operation name is only needed in GraphQL when the document contains many operations, and we need to specify which one to execute, or maybe execute several of them together, tying them via @export.
In the previous case, there’s no need for it for PQL — we only pass the query that must be executed, not all of them.
In the latter case, the multiple operations can be executed together in a single request, while guaranteeing their execution order, by joining them with ; like so:
posts.
author.
id|
name|
url;
posts.
comments.
id|
content
In GraphQL, the variable definition is used to define the type of the variable, enabling clients like GraphiQL to show an error whenever the type is different. This is a nice-to-have, but not really needed for executing the query itself.
Default variable values can be defined like any variable: via a URL param.
The on element is not needed since we can instead use the directive @include, passing a composable field isType as argument, to find out the type of the object and, based on this value, apply the intended fragment or not.
For instance, take this GraphQL query:
{
customPosts {
__typename
... on Post {
title
}
}
}
This is the PQL equivalent:
customPosts. __typename| title<include(if:isType(Post))>
Let’s convert the introspection query used by GraphiQL (and other clients) to obtain the schema metadata from the GraphQL syntax to PQL.
The introspection query is this one:
query IntrospectionQuery {
__schema {
queryType {
name
}
mutationType {
name
}
subscriptionType {
name
}
types {
...FullType
}
directives {
name
description
locations
args {
...InputValue
}
}
}
}
fragment FullType on __Type {
kind
name
description
fields(includeDeprecated: true) {
name
description
args {
...InputValue
}
type {
...TypeRef
}
isDeprecated
deprecationReason
}
inputFields {
...InputValue
}
interfaces {
...TypeRef
}
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
possibleTypes {
...TypeRef
}
}
fragment InputValue on __InputValue {
name
description
type {
...TypeRef
}
defaultValue
}
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
}
}
}
}
Its equivalent PQL query is this one:
?query=
__schema[schema].
queryType.
name,
[schema].
mutationType.
name,
[schema].
subscriptionType.
name,
[schema].
types.
--FullType,
[schema].
directives.
name|
description|
locations|
args.
--InputValue
&fragments[FullType]=
kind|
name|
description|
fields(includeDeprecated: true)[@fields].
name|
description|
args.
--InputValue,
[fields].
type.
--TypeRef,
[fields].
isDeprecated|
deprecationReason,
[fields].
inputFields.
--InputValue,
[fields].
interfaces.
--TypeRef,
[fields].
enumValues(includeDeprecated: true)@enumValues.
name|
description|
isDeprecated|
deprecationReason,
[fields].
possibleTypes.
--TypeRef
&fragments[InputValue]=
name|
description|
defaultValue|
type.
--TypeRef
&fragments[TypeRef]=
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name|
ofType.
kind|
name
Execute query in browser. (Note that the query in this link is slightly different than the one above since I still need to add support for the , token within fragments.)
And this is the query written in a single line:
?query=__schema[schema].queryType.name,[schema].mutationType.name,[schema].subscriptionType.name,[schema].types.--FullType,[schema].directives.name|description|locations|args.--InputValue&fragments[FullType]=kind|name|description|fields(includeDeprecated: true)[@fields].name|description|args.--InputValue,[fields].type.--TypeRef,[fields].isDeprecated|deprecationReason,[fields].inputFields.--InputValue,[fields].interfaces.--TypeRef,[fields].enumValues(includeDeprecated: true)@enumValues.name|description|isDeprecated|deprecationReason,[fields].possibleTypes.--TypeRef&fragments[InputValue]=name|description|defaultValue|type.--TypeRef&fragments[TypeRef]=kind|name|ofType.kind|name|ofType.kind|name|ofType.kind|name|ofType.kind|name|ofType.kind|name|ofType.kind|name|ofType.kind|name
This query has a fragment containing nested paths, variables, directives, and other fragments:
?query=
posts(limit:$limit, order:$order).
--postData|
author.
posts(limit:$limit).
--postData
&postData=
id|
title|
--nestedPostData|
date(format:$format)
&nestedPostData=
comments<include(if:$include)>.
id|
content
&format=d/m/Y
&include=true
&limit=3
&order=title
This query applies a directive to a fragment, which is consequently applied on all the fields within the fragment:
?query=
posts.
id|
--props<include(if:hasComments())>
&fragments[props]=
title|
date
Finally, there are many examples of single-line queries embedded directly as a URL param, and containing additional properties from the PQL syntax (not described in this article), in this blog post.
In order to support HTTP caching, we must currently use GraphQL servers that support persisted queries.
But what about the GraphQL single endpoint? Could it also support HTTP caching? And if so, could it be done in a way that people can write the query instead of having to depend on a client or library?
The response to these questions is: yes, it can be done. However, the GraphQL syntax currently stands in the way due to its nesting behavior.
In this article I demonstrated an alternative syntax, called PQL, that would enable GraphQL servers to accept the query via the URL param, while enabling people to read and write the query in a single line, even directly in the browser’s address bar.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

