Puppeteer is a high-level abstraction of headless Chrome with an extensive API. This makes it very convenient to automate interactions with a web page.

This article will walk you through an example use case where we are going to search for a keyword on GitHub and fetch the title of the first result.
This is a basic example purely for the sake of demonstration, and it can even be done without Puppeteer. Because the keyword can sit in the URL and the page listing on GitHub’s page, you can directly navigate to the results.
However, assume that the interaction you have on the web page is not reflected in the page URL and that there is no public API to fetch the data, then automation through Puppeteer comes in handy.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Let’s initialize a Node.js project inside a folder. On your system terminal, navigate to the folder you want to have the project in and run the following command:
npm init -y
This will generate a package.json file. Next, install the Puppeteer npm package.
npm install --save puppeteer
Now, create a file named service.mjs. This file format allows us to use ES modules and is going to be responsible for scraping the page by using Puppeteer. Let’s complete a quick test with Puppeteer to see it works.
First, we launch a Chrome instance and pass the headless: false argument to display it instead of running it headless without the GUI. Now create a page with the newPage method and use the goto method to navigate to the URL passed as a parameter:
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.github.com');
When you run this code, a Chrome window should pop up and should navigate to the URL in a new tab.
For Puppeteer to interact with the page, we need to manually inspect the page and specify the DOM elements to target.
We need to determine the selectors, i.e., the class name, id, element type, or a combination of several of these. In case we need a high level of specificity, we can use these selectors with various Puppeteer methods.
Now, let’s inspect www.github.com with a browser. We need to be able to focus the search input field at the top of the page and then type the keyword we want to search for. Then we need to Git Enter button on the keyboard.
Open www.github.com on the browser you prefer — I use Chrome, but any browser would do it — right-click on the page and click Inspect. Then, under the Elements tab, you can see the DOM tree. Using the inspection tool on the left top corner of the inspection pane, you can click on elements to highlight them in the DOM tree:
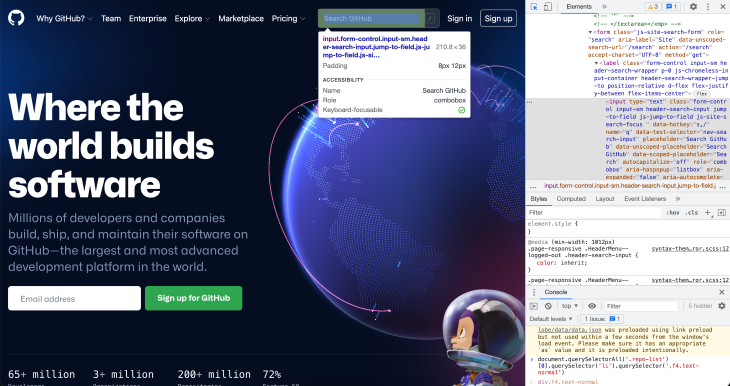
The input field element we are interested in has several class names but it is sufficient to only target .header-search-input. To ensure we are referring to the correct element, we can test it quickly on the browser console. Click on the Console tab and use the querySelector method on the Document object:
document.querySelector('.header-search-input')
If this returns the correct element, then we know it will work with Puppeteer.
Note that there might be several elements matching the same selector. In that case, querySelector returns the first matching element. To refer to the correct element, you need to use querySelectorAll and then pick the correct index from the NodeList of elements returned.
There is one thing we should pay attention to here. If you resize the GitHub webpage, the input field becomes invisible and available in the hamburger menu instead.
Because it is not visible unless the hamburger menu is open, we cannot focus on it. To make sure the input field will be visible, we can explicitly set the browser window size by passing the defaultViewport object to the settings.
const browser = await puppeteer.launch({
headless: false,
defaultViewport: {
width: 1920,
height: 1080
}
});
Now it’s time to use the query to target the element. Before attempting to interact with the element, we have to make sure that it is rendered on the page and ready. Puppeteer has the waitForSelector method for this reason.
It takes the selector string as the first argument and the options object as the second argument. Because we are going to interact with the element, i.e., focus and then type in the input field, we need to have it visible on the page, hence the visible: true option.
const inputField = '.header-search-input';
await page.waitForSelector(inputField, { visible: true });
As mentioned earlier, we need to focus on the input field element and then simulate typing. For these purposes, Puppeteer has the following methods:
const keyword = 'react'; await page.focus(inputField); await page.keyboard.type(keyword);
So far service.mjs looks as follows:
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({
headless: false,
defaultViewport: {
width: 1920,
height: 1080
}
});
const page = await browser.newPage();
await page.goto('https://www.github.com');
const inputField = '.header-search-input';
const keyword = 'react'
await page.waitForSelector(inputField);
await page.focus(inputField);
await page.keyboard.type(keyword);
When you run the code, you should see the search field focused and that it has the react keyword typed in.
Now, simulate the Enter keypress on the keyboard.
await page.keyboard.press('Enter');
After we press the Enter key, Chrome will navigate to a new page. If we manually search for a keyword and inspect the page we are navigated to, we will figure out the selector for the element we are interested in is .repo-list.
At this point, we need to make sure that navigation to the new page is complete. To do so, there is a page.waitForNavigation method. After navigating, we once again need to wait for the element by using the page.waitForSelector method.
However, if we are only interested in scraping some data from the element, we do not need to wait until it is visually visible. So, this time, we can omit the { visible: true } option, which is set to false by default.
const repoList = '.repo-list'; await page.waitForNavigation(); await page.waitForSelector(repoList);
Once we know that the .repo-list selector is in the DOM tree, then we can scrape the title by using the page.evaluate method.
First, we select the .repo-list by passing the repoList variable to a querySelector. Then we cascade querySelectorAll to get all the li elements and select the first element from the NodeList of elements.
Finally, we add another querySelector that targets the .f4.text-normal query, which has the title that we access through innerText.
const title = await page.evaluate((repoList) => (
document
.querySelector(repoList)
.querySelectorAll('li')[0]
.querySelector('.f4.text-normal')
.innerText
), repoList);
Now we can wrap everything inside a function and export it to be used in another file, where we will set up the Express server with an endpoint to serve the data.
The final version of service.mjs returns an async function that takes the keyword as an input. Inside the function, we use a try…catch block to catch and return any errors. In the end, we call browser.close to close the browser we have launched.
import puppeteer from 'puppeteer';
const service = async (keyword) => {
const browser = await puppeteer.launch({
headless: true,
defaultViewport: {
width: 1920,
height: 1080
}
});
const inputField = '.header-search-input';
const repoList = '.repo-list';
try {
const page = await browser.newPage();
await page.goto('https://www.github.com');
await page.waitForSelector(inputField);
await page.focus(inputField);
await page.keyboard.type(keyword);
await page.keyboard.press('Enter');
await page.waitForNavigation();
await page.waitForSelector(repoList);
const title = await page.evaluate((repoList) => (
document
.querySelector(repoList)
.querySelectorAll('li')[0]
.querySelector('.f4.text-normal')
.innerText
), repoList);
await browser.close();
return title;
} catch (e) {
throw e;
}
}
export default service;
We need a single endpoint to serve the data where we capture the keyword to be searched as a route parameter. Because we defined the route path as /:keyword, it’s exposed in the req.params object with the key of keyword. Next, we call the service function and pass this keyword as the input parameter to run Puppeteer.
Content of server.mjs is as follows:
import express from 'express';
import service from './service.mjs';
const app = express();
app.listen(5000);
app.get('/:keyword', async (req, res) => {
const { keyword } = req.params;
try {
const response = await service(keyword);
res.status(200).send(response);
} catch (e) {
res.status(500).send(e);
}
});
In the terminal, run node server.mjs to start the server. In another terminal window, send a request to the endpoint by using curl. This should return the string value from the entry title.
curl localhost:5000/react
Note that this server is the bare minimum. In production, you should secure your endpoint and set the CORS in case you need to send a request from a browser instead of a server.
Now we are going to deploy this service to a serverless cloud function. The main difference between a cloud function and a server is that cloud functions are quickly invoked upon request and stay up for some time to respond to subsequent requests, whereas a server is always up and running.
Deploying to Google Cloud Functions is very straightforward. However, there are some settings you should be aware of in order to run Puppeteer successfully.
First of all, allocate enough memory to your cloud function. According to my tests, 512MB is sufficient for Puppeteer, but if you run into a memory-related problem, allocate more.
The package.json content should be as follows:
{
"name": "puppeteer-example",
"version": "0.0.1",
"type": "module",
"dependencies": {
"puppeteer": "^10.2.0",
"express": "^4.17.1"
}
}
We added puppeteer and express as dependencies and set “type”: “module” in order to use ES6 syntax.
Now create a file named service.js and fill it with the same content that we used in service.mjs.
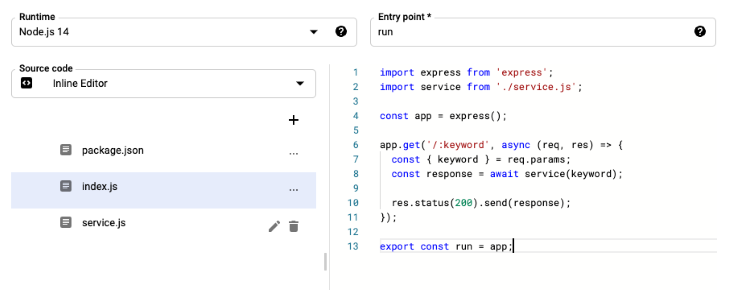
The content of index.js is as follows:
import express from 'express';
import service from './service.js';
const app = express();
app.get('/:keyword', async (req, res) => {
const { keyword } = req.params;
try {
const response = await service(keyword);
res.status(200).send(response);
} catch (e) {
res.status(500).send(e);
}
});
export const run = app;
Here, we imported the express package and our function from server.js.
Unlike the server code we tested on the localhost, we don’t need to listen on a port because this is handled automatically.
And, unlike the localhost, we need to export the app object in cloud functions. Set the Entry point to run or whatever variable name you are exporting, as shown below. This is set to helloWorld by default.
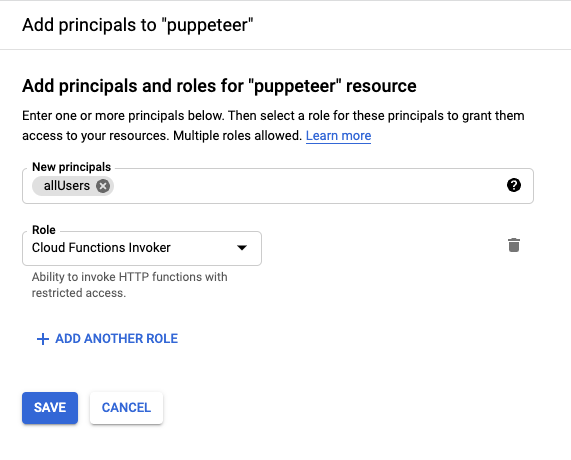
To easily test our cloud function, let’s make it public. Select the cloud function (note: it has the checkbox next to it) and click the permissions button from the top bar menu. This will show a side panel where you can add principals. Click add principal and search for allUsers in the New principal field. Finally, select Cloud Function Invoker as the Role.
Note that once this principal is added, anyone with the trigger link can invoke the function. For testing, this is fine, but make sure to implement authentication for your cloud function to avoid undesired invokes, which would be reflected in the bill.
Now click on your function to see the function details. Navigate to the Trigger tab, where you will find the trigger URL. Click this link to invoke the function, which returns the title of the first repository in the list. You can now use this link in your application to fetch the data.
We have covered how to use Puppeteer in order to automate basic interactions with a webpage and scrape the content to serve it with the Express framework on a Node server. Then, we deployed it on Google Cloud Functions in order to make it a microservice, which then can be integrated and used in another application.

Learn about TypeScript v6’s breaking changes, new ES2025 features, and deprecated options. A complete migration guide from v5 to prepare for v7.

Learn how Vite+ unifies Vite, Vitest, Oxlint, Oxfmt, Rolldown, and Node.js management in one CLI.

AI companies are buying developer tools as coding agents turn runtimes, package managers, and linters into strategic infrastructure.

Learn how AI-assisted development governance uses rules, agents, hooks, and protocols to help AI coding tools produce safer, more consistent code.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

