The observability of today’s complex, dynamic systems is predicated on domain knowledge or, more so, on the unknown “unknowns” that arise from incomplete domain knowledge. In other words, the cases that fall between the cracks and surprise us, as illuminated in the below quote:

It took us no more than an hour to figure out how to restore the network; several additional hours were required because it took so long for us to gain control of the misbehaving IMPs and get them back to normal. A built-in software alarm system (assuming, of course, that it was not subject to false alarms) might have enabled us to restore the network more quickly, significantly reducing the duration of the outage. This is not to say that a better alarm and control system could ever be a replacement for careful study and design which attempts to properly distribute the utilization of important resources, but only that it is a necessary adjunct, to handle the cases that will inevitably fall between the cracks of even the most careful design – (Rosen, RFC 789)
At its heart, observability is how we expose a system’s behavior (in some disciplined way, hopefully) and make sense of such behavior.
In this article, we’ll discuss the importance of observability and we’ll investigate composing the underpinnings of an observable Rust application.
Jump ahead:
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Our systems have become more complicated due to the proliferation of microservice deployments and orchestration engines, where major companies are running thousands of microservices, and even startups are operating in the hundreds.
The harsh reality of microservices is that they suddenly force every developer to become a cloud/distributed systems engineer, dealing with the complexity that is inherent in distributed systems. Specifically, partial failure, where the unavailability of one or more services can adversely impact the system in unknown ways. – (Meiklejohn, et. al., Service-Level Fault Injection Testing)
In these complex times, achieving observability goes a long way into architecting, troubleshooting, and benchmarking our systems for the long haul. Delivering observability starts with the gathering of our output data (telemetry and instrumentation) from our running systems at the right level of abstraction, normally organized around a request path, so that we can then explore and dissect data patterns and find cross-correlations.
On paper, this sounds somewhat easy to achieve. We gather our three pillars — logs, metrics, and traces — and we’re done. However, these three pillars on their own are just bits, whereas gathering the most helpful kinds of bits and analyzing the collection of bits together holds the most complexity.
Forming the right abstractions is the hard part. It can be very domain-specific and relies on building a model for our systems’ behavior, which is open to change and prepared for surprises. It involves the developer having to get more involved with how events in their applications and systems are generated and diagnosed.
Throwing log statements everywhere and collecting every possible metric loses long-term value and causes other concerns. We need to expose and augment meaningful output, so that data correlation is even possible.
This is a Rust article after all, and while Rust was built with safety, speed, and efficiency in mind, exposing system behavior was not one of its founding principles.
Starting from the first principles, how do we go about instrumenting code, collecting meaningful trace information, and deriving data to help us explore unknown “unknowns”? If everything is driven by events and we have traces that capture a series of events/operations, which include requests/responses, database reads/writes, and/or cache misses, etc., what’s the trick to go from nothing to something for a Rust application that has to communicate with the outside world in order to achieve end-to-end observability? What do the building blocks look like?
Sadly, there’s not just one trick or silver bullet here, especially when writing Rust services, which leaves a lot for the developer to piece together. First, the only thing we can truly rely on to understand and debug an unknown “unknown” is telemetry data, and we should make sure we surface meaningful, contextual telemetry data (e.g., correlatable fields like request_path, parent_span, trace_id, category, and subject). Second, we need a way to explore that output and correlate it across systems and services.
In this post, we’ll mainly be concerned with collecting and gathering meaningful, contextual output data, but we’ll also discuss how best to hook into platforms that provide further processing, analysis, and visualization. Luckily, the core tool(s) are out there for instrumenting Rust programs to collect structured event data and process and emit trace information, for async and sync communication alike.
We’ll focus on the most standard and flexible framework, tracing, which is situated around spans, events, and subscribers, and how we can take advantage of its composability and customizability.
However, even though we have an extensive framework like tracing at our disposal to help us write the underpinnings of observable services in Rust, meaningful telemetry doesn’t come “out of the box” or “fall out for free.”
Getting to the right abstraction in Rust is not as straightforward as it may be in other languages. Instead, a robust application must be built upon layered behaviors, all of which provide exemplary controls for developers in the know, but can be cumbersome for those more inexperienced.
We’re going to break up our problem space into a series of composable layers which function over four different units of behavior:
Akin to how the original QuickCheck paper on property-based testing relied on users to specify properties and provide instances for user-defined types, building end-to-end observable Rust services comes with having to have some understanding of how traces are generated, how data is specified and maintained, and what telemetry makes sense as applications grow. This is particularly true when it comes time to debug and/or explore inconsistencies, partial failures, and dubious performance characteristics.
Trace collection will drive everything in this post’s examples, where spans and events will be the lens through which we tie together a complete picture of known quantities. We’ll have logs, but we’ll treat them as structured events. We’ll gather metrics, but have them automated via instrumentation and spans, and we’ll export OpenTelemetry-compatible trace data for emission to a distributed tracing platform like Jaeger.
Before we get into the implementation details, let’s start with some terms and concepts we need to be familiar with, such as spans, traces, and events.
A span represents operations or segments that are part of a trace and acts as the primary building block of distributed tracing. For any given request, the initial span (without a parent) is called the root span. It is typically represented as the end-to-end latency of an entire user request of a given distributed trace.
There can also be subsequent child spans, which can be nested under other various parent spans. The total execution time of a span consists of the time spent in that span as well as the entire subtree represented by its children.
Here’s an example of a purposefully condensed parent span log for a new request:
level=INFO span name="HTTP request" span=9008298766368774 parent_span=9008298766368773 span_event=new_span timestamp=2022-10-30T22:30:28.798564Z http.client_ip=127.0.0.1:61033 http.host=127.0.0.1:3030 http.method=POST http.route=/songs trace_id=b2b32ad7414392aedde4177572b3fea3
This span log contains important pieces of information and metadata like the request path (http.route), timestamp (2022-10-30T22:30:28.798564Z), request method (http.method), and trace identifiers (span, parent_span, and trace_id respectively). We’ll use this information to demonstrate how a trace is tied together from start to completion.
Why is it called a span? Ben Sigelman, an author of Google’s Dapper tracing infrastructure paper, considered these factors in A Brief History of “The Span”: Hard to Love, Hard to Kill:
- Within the code itself, the API feels like a timer
- When one considers the trace as a directed graph, the data structure seems like a node or vertex
- In the context of structured, multi-process logging (side note: at the end of the day, that’s what distributed tracing is), one might think of a span as two events
- Given a simple timing diagram, it’s tempting to call the concept a duration or window
An event represents a single operation in time, where something occurred during the execution of some arbitrary program. In contrast to out-of-band, unstructured log records, we will treat events as a core unit of ingest happening within the context of a given span, and structured with key-value fields (akin to the span log above). More precisely, these are called span events:
level=INFO msg="finished processing vendor request" subject=vendor.response category=http.response vendor.status=200 vendor.response_headers="{\"content-type\": \"application/json\", \"vary\": \"Accept-Encoding, User-Agent\", \"transfer-encoding\": \"chunked\"}" vendor.url=http://localhost:8080/.well-known/jwks.json vendor.request_path=/.well-known/jwks.json target="application::middleware::logging" location="src/middleware/logging.rs:354" timestamp=2022-10-31T02:45:30.683888Z
Our application can also have arbitrary structured log events that take place outside of a span context. For example, to display configuration settings at startup or monitor when a cache is flushed.
A trace is a collection of spans that represent some workflow, like a server request or queue/stream processing steps for an item. Essentially, a trace is a Directed Acyclic Graph of spans, where the edges connecting spans indicate causal relationships between spans and their parent spans.
Here’s an example of a trace visualized within Jaeger UI:
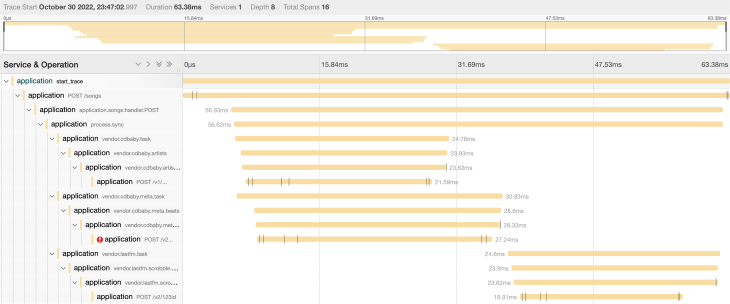
If this application were part of a larger, distributed trace, we’d see it nested within a larger parent span.
Now, with the terms out of the way, how do we even get started implementing the skeleton of an observability-ready Rust application?
The tracing framework is split up into different components (as crates). We’ll focus on this set of .toml dependencies for our purposes:
opentelemetry = { version = "0.17", features = ["rt-tokio", "trace"] }
opentelemetry-otlp = { version = "0.10", features = ["metrics", "tokio", "tonic", "tonic-build", "prost", "tls", "tls-roots"], default-features = false}
opentelemetry-semantic-conventions = "0.9"
tracing = "0.1"
tracing-appender = "0.2"
tracing-opentelemetry = "0.17"
tracing-subscriber = {version = "0.3", features = ["env-filter", "json", "registry"]}
The tracing_subscriber crate gives us the ability to compose tracing subscribers from smaller units of behavior, called layers, for collecting and augmenting trace data.
The Subscriber itself is responsible for registering new spans when created (with a span id), recording and attaching field values and follow-from annotations to spans, and filtering out spans and events.
When composed with a subscriber, layers tap into hooks triggered throughout a span’s lifecycle:
fn on_new_span(&self, _attrs: &Attributes<'_>, _id: &span::Id, _ctx: Context<'_, C>) {...}
fn on_record(&self, _span: &Id, _values: &Record<'_>, _ctx: Context<'_, S>) { ... }
fn on_follows_from(&self, _span: &Id, _follows: &Id, _ctx: Context<'_, S>) { ... }
fn event_enabled(&self, _event: &Event<'_>, _ctx: Context<'_, S>) -> bool { ... }
fn on_event(&self, _event: &Event<'_>, _ctx: Context<'_, S>) { ... }
fn on_enter(&self, _id: &Id, _ctx: Context<'_, S>) { ... }
fn on_exit(&self, _id: &Id, _ctx: Context<'_, S>) { ... }
fn on_close(&self, _id: Id, _ctx: Context<'_, S>) { ... }
How are layers composed in code? Let’s start with a setup method, producing a registry that’s defined with four with combinators, or layers:
fn setup_tracing(
writer: tracing_appender::non_blocking::NonBlocking,
settings_otel: &Otel,
) -> Result<()> {
let tracer = init_tracer(settings_otel)?;
let registry = tracing_subscriber::Registry::default()
.with(StorageLayer.with_filter(LevelFilter::TRACE))
.with(tracing_opentelemetry::layer()...
.with(LogFmtLayer::new(writer).with_target(true)...
.with(MetricsLayer)...
);
...
The setup_tracing function would typically be called upon initialization of a server’s main() method in main.rs. The storage layer itself provides zero output and instead acts as an information store for gathering contextual trace information to augment and extend downstream output for the other layers in the pipeline.
The with_filter method controls which spans and events are enabled for this layer, and we’ll want to capture essentially everything, as LevelFilter::TRACE is the most verbose option.
Let’s examine each layer and see how each operates over trace data collected and hooks into the span lifecycle. Customizing each layer’s behavior involves implementing lifecycle hooks associated with the Layer trait, like on_new_span below.
Along the way, we’ll demonstrate how these units of behavior augment span- and event-log formatting, derive some metrics automatically, and send what we’ve gathered to downstream, distributed-tracing platforms like Jaeger, Honeycomb, or Datadog. We’ll start with our StorageLayer, which provides contextual information from which other layers can benefit.
impl<S> Layer<S> for StorageLayer
where
S: Subscriber + for<'span> LookupSpan<'span>,
{
fn on_new_span(&self, attrs: &Attributes<'_>, id: &Id, ctx: Context<'_, S>) {
let span = ctx.span(id).expect("Span not found");
// We want to inherit the fields from the parent span, if there is one.
let mut visitor = if let Some(parent_span) = span.parent() {
let mut extensions = parent_span.extensions_mut();
let mut inner = extensions
.get_mut::<Storage>()
.map(|v| v.to_owned())
.unwrap_or_default();
inner.values.insert(
PARENT_SPAN, // "parent_span"
Cow::from(parent_span.id().into_u64().to_string()),
);
inner
} else {
Storage::default()
};
let mut extensions = span.extensions_mut();
attrs.record(&mut visitor);
extensions.insert(visitor);
}
...
When a new span (via on_new_span) is initiated, for example, a POST request into our application to an endpoint like /songs, our code checks to see if we’re already within a parent span. Otherwise, it will default to a newly created, empty Hashmap, which is what Storage::default() wraps under the hood.
For simplicity, we default the map to keys of string references and values of copy-on-write (Cow) smart pointers around string references:
#[derive(Clone, Debug, Default)]
pub(crate) struct Storage<'a> {
values: HashMap<&'a str, Cow<'a, str>>,
}
Storage persists fields across layers in a registry within the lifecycle of the span due to a span’s extensions, giving us the ability to mutably associate arbitrary data to a span or immutably read from persisted data, including our own data structure.
Many of these lifecycle hooks involve wrestling with extensions, which can be somewhat verbose to work with. The registry is what actually collects and stores span data, which can then bubble through to other layers via the implementation of LookupSpan.
The other code to highlight is attrs.record(&mut visitor) which will record field values of various types by visiting each type of value, which is a trait that must be implemented:
// Just a sample of the implemented methods
impl Visit for Storage<'_> {
/// Visit a signed 64-bit integer value.
fn record_i64(&mut self, field: &Field, value: i64) {
self.values
.insert(field.name(), Cow::from(value.to_string()));
}
... // elided for brevity
fn record_debug(&mut self, field: &Field, value: &dyn fmt::Debug) {
// Note: this is invoked via `debug!` and `info! macros
let debug_formatted = format!("{:?}", value);
self.values.insert(field.name(), Cow::from(debug_formatted));
}
...
Once we’ve recorded all the values for each type, all of this is stored within the Storage Hashmap by the visitor, which will be available for downstream layers to use for lifecycle triggers in the future.
impl<S> Layer<S> for StorageLayer
where
S: Subscriber + for<'span> LookupSpan<'span>,
{
... // elided for brevity
fn on_record(&self, span: &Id, values: &Record<'_>, ctx: Context<'_, S>) {
let span = ctx.span(span).expect("Span not found");
let mut extensions = span.extensions_mut();
let visitor = extensions
.get_mut::<Storage>()
.expect("Visitor not found on 'record'!");
values.record(visitor);
}
... // elided for brevity
As we continue through each lifecycle trigger, we’ll notice that the pattern is similar. We get a mutable, scoped handle into the span’s storage extension, and we record values as they arrive.
This hook notifies a layer that a span with a given identifier has recorded the given values, via calls like debug_span! or info_span!:
let span = info_span!(
"vendor.cdbaby.task",
subject = "vendor.cdbaby",
category = "vendor"
);
impl<S> Layer<S> for StorageLayer
where
S: Subscriber + for<'span> LookupSpan<'span>,
{
... // elided for brevity
fn on_event(&self, event: &Event<'_>, ctx: Context<'_, S>) {
ctx.lookup_current().map(|current_span| {
let mut extensions = current_span.extensions_mut();
extensions.get_mut::<Storage>().map(|visitor| {
if event
.fields()
.any(|f| ON_EVENT_KEEP_FIELDS.contains(&f.name()))
{
event.record(visitor);
}
})
});
}
... // elided for brevity
For our contextual storage layer, hooking into events, like tracing::error! messages, is generally unnecessary. But, this can become valuable for storing information on event fields we’d like to keep that may be useful in another layer later in the pipeline.
One example is to store an event if it was attributed to an error so that we can keep track of errors in our metrics layer (e.g., ON_EVENT_KEEP_FIELDS is an array of fields tied to error keys).
impl<S> Layer<S> for StorageLayer
where
S: Subscriber + for<'span> LookupSpan<'span>,
{
... // elided for brevity
fn on_enter(&self, span: &Id, ctx: Context<'_, S>) {
let span = ctx.span(span).expect("Span not found");
let mut extensions = span.extensions_mut();
if extensions.get_mut::<Instant>().is_none() {
extensions.insert(Instant::now);
}
}
fn on_close(&self, id: Id, ctx: Context<'_, S>) {
let span = ctx.span(&id).expect("Span not found");
let mut extensions = span.extensions_mut();
let elapsed_milliseconds = extensions
.get_mut::<Instant>()
.map(|i| i.elapsed().as_millis())
.unwrap_or(0);
let visitor = extensions
.get_mut::<Storage>()
.expect("Visitor not found on 'record'");
visitor.values.insert(
LATENCY_FIELD, // "latency_ms"
Cow::from(format!("{}", elapsed_milliseconds)),
);
}
... // elided for brevity
Spans are inherently tagged time intervals, with a clear-cut beginning and end. For the scope of a span, we want to capture the elapsed time between when the span with a given id was entered (Instant::now) until it is closed for a given operation.
Storing the latency for each span within our extensions enables other layers to derive metrics automatically and benefits exploratory purposes while debugging event logs for a given span id. Below, we can see the opening and closing of a vendor task/process span with id=452612587184455697, which took 18ms from start to finish:
level=INFO span_name=vendor.lastfm.task span=452612587184455697 parent_span=span=452612587184455696 span_event=new_span timestamp=2022-10-31T12:35:36.913335Z trace_id=c53cb20e4ab4fa42aa5836d26e974de2 http.client_ip=127.0.0.1:51029 subject=vendor.lastfm application.request_path=/songs http.method=POST category=vendor http.host=127.0.0.1:3030 http.route=/songs request_id=01GGQ0MJ94E24YYZ6FEXFPKVFP
level=INFO span_name=vendor.lastfm.task span=452612587184455697 parent_span=span=452612587184455696 span_event=close_span timestamp=2022-10-31T12:35:36.931975Z trace_id=c53cb20e4ab4fa42aa5836d26e974de2 latency_ms=18 http.client_ip=127.0.0.1:51029 subject=vendor.lastfm application.request_path=/songs http.method=POST category=vendor http.host=127.0.0.1:3030 http.route=/songs request_id=01GGQ0MJ94E24YYZ6FEXFPKVFP
Now we will get a glimpse into how our storage data can be tapped into for actual telemetry output by looking at our event log formatting layer:
.with(LogFmtLayer::new(writer).with_target(true)...
When it comes to writing custom layers and subscriber implementations, many examples tend toward custom formatters:
logfmtN.B., the log examples above use this same format, inspired by an implementation from InfluxDB)
We recommend using published layers or libraries or following tutorials like those listed above for diving into the specifics of generating data in a preferred format.
For this article, which builds up our own custom formatter layer, we’ll re-familiarize ourselves with the span lifecycle, specifically for span and event logs, which will now take advantage of our storage map.
impl<S, Wr, W> Layer<S> for LogFmtLayer<Wr, W>
where
Wr: Write + 'static,
W: for<'writer> MakeWriter<'writer> + 'static,
S: Subscriber + for<'span> LookupSpan<'span>,
{
fn on_new_span(&self, _attrs: &Attributes<'_>, id: &Id, ctx: Context<'_, S>) {
let mut p = self.printer.write();
let metadata = ctx.metadata(id).expect("Span missing metadata");
p.write_level(metadata.level());
p.write_span_name(metadata.name());
p.write_span_id(id);
p.write_span_event("new_span");
p.write_timestamp();
let span = ctx.span(id).expect("Span not found");
let extensions = span.extensions();
if let Some(visitor) = extensions.get::<Storage>() {
for (key, value) in visitor.values() {
p.write_kv(
decorate_field_name(translate_field_name(key)),
value.to_string(),
)
}
}
p.write_newline();
}
... // elided for brevity
The above code is using the MakeWriter trait to print formatted text representations of span events. The call to decorate_field_name and all the printer write methods execute specific formatting properties under the hood (again, in this case, logfmt).
Going back to our previous span log example, it’s now more apparent where keys like level, span, and span_name are set. One piece of code to call out here is how we loop, for (key, value), over the values read from our storage map, lifting information we observed and collected in the previous layer.
We use this to provide context to augment our structured log events in another layer. Put another way, we’re composing specific sub-behaviors on trace data via layers in order to build out a singular subscriber to the overall trace. Field keys like http.route and http.host are lifted from this storage layer for example.
impl<S, Wr, W> Layer<S> for LogFmtLayer<Wr, W>
where
Wr: Write + 'static,
W: for<'writer> MakeWriter<'writer> + 'static,
S: Subscriber + for<'span> LookupSpan<'span>,
{
... // elided for brevity
fn on_event(&self, event: &Event<'_>, ctx: Context<'_, S>) {
let mut p = self.printer.write();
p.write_level(event.metadata().level());
event.record(&mut *p);
//record source information
p.write_source_info(event);
p.write_timestamp();
ctx.lookup_current().map(|current_span| {
p.write_span_id(¤t_span.id());
let extensions = current_span.extensions();
extensions.get::<Storage>().map(|visitor| {
for (key, value) in visitor.values() {
if !ON_EVENT_SKIP_FIELDS.contains(key) {
p.write_kv(
decorate_field_name(translate_field_name(key)),
value.to_string(),
)
}
}
})
});
p.write_newline();
}
... // elided for brevity
Though somewhat tedious, the pattern for implementing these span lifecycle methods is getting easier and easier to make out. Field key-value pairs like target and location are formatted from source information, giving us the target="application::middleware::logging" and location="src/middleware/logging.rs:354" seen previously. Keys like vendor.request_path and vendor.url are also lifted from contextual storage.
While more work would probably go into implementing any formatting specification correctly, we can now see the granular control and customization that the tracing framework provides. This contextual information is how we’ll eventually be able to form correlations within a request lifecycle.
Metrics, in particular, are actually quite hostile to observability on their own, and the cardinality of a metric, the number of unique combinations of metric names and dimension values, can easily be abused.
Charity Majors on Twitter: “The event is the connective tissue for metrics, logs and tracing, because you can derive the first two from events and you can visualize the third from events.But it doesn’t go in reverse: you can never work backwards from metrics, logs, and/or traces to get your event back. / Twitter”
The event is the connective tissue for metrics, logs and tracing, because you can derive the first two from events and you can visualize the third from events.But it doesn’t go in reverse: you can never work backwards from metrics, logs, and/or traces to get your event back.
We’ve already shown how structured logs can be derived from events. Metrics themselves should be formed from the event, or span, that encompassed them.
We will still need out-of-band metrics like those geared around process collection (e.g., CPU usage, disk bytes written/read). However, if we’re already able to instrument our code at the function level to determine when something occurred, couldn’t some metrics “fall out for free?” As mentioned previously, we have the tooling, but we just need to thread it through.
Tracing provides accessible ways to annotate functions a user wants to instrument, which means creating, entering, and closing a span each time the annotation function executes. The rust compiler itself makes heavy use of these annotated instrumentations all over the codebase:
#[instrument(skip(self, op), level = "trace")]
pub(super) fn fully_perform_op<R: fmt::Debug, Op>(
&mut self,
locations: Locations,
category: ConstraintCategory<'tcx>,
op: Op) -> Fallible<R>
For our purposes, let’s look at a straightforward, async database save_event function that’s been instrumented with some very specific field definitions:
#[instrument(
level = "info",
name = "record.save_event",
skip_all,
fields(category="db", subject="aws_db", event_id = %event.event_id,
event_type=%event.event_type, otel.kind="client", db.system="aws_db",
metric_name="db_event", metric_label_event_table=%self.event_table_name,
metric_label_event_type=%event.event_type)
err(Display)
)]
pub async fn save_event(&self, event: &Event) -> anyhow::Result<()> {
self.db_client
.put_item()
.table_name(&self.event_table_name)
.set(Some(event))
.send()
.await...
}
Our instrumentation function has metric prefixed fields like name, event_type, and event_table. These keys correspond to metric names and labels typically found in a Prometheus monitoring setup. We’ll come back to these prefixed fields shortly. First, let’s expand the MetricsLayer that we set up initially with some additional filters.
Essentially, these filters do two things: 1) produce metrics for all trace-log-level or higher events (even though they may not be logged to stdout based on a configured log level); and, 2) pass through events for instrumented functions with the record prefix attached, as in name = "record.save_event" above.
After this, all that’s left in order to automate metric derivation is to return to our metrics-layer implementation.
const PREFIX_LABEL: &str = "metric_label_";
const METRIC_NAME: &str = "metric_name";
const OK: &str = "ok";
const ERROR: &str = "error";
const LABEL: &str = "label";
const RESULT_LABEL: &str = "result";
impl<S> Layer<S> for MetricsLayer
where
S: Subscriber + for<'span> LookupSpan<'span>,
{
fn on_close(&self, id: Id, ctx: Context<'_, S>) {
let span = ctx.span(&id).expect("Span not found");
let mut extensions = span.extensions_mut();
let elapsed_secs_f64 = extensions
.get_mut::<Instant>()
.map(|i| i.elapsed().as_secs_f64())
.unwrap_or(0.0);
if let Some(visitor) = extensions.get_mut::<Storage>() {
let mut labels = vec![];
for (key, value) in visitor.values() {
if key.starts_with(PREFIX_LABEL) {
labels.push((
key.strip_prefix(PREFIX_LABEL).unwrap_or(LABEL),
value.to_string(),
))
}
}
... // elided for brevity
let name = visitor
.values()
.get(METRIC_NAME)
.unwrap_or(&Cow::from(span_name))
.to_string();
if visitor.values().contains_key(ERROR)
labels.push((RESULT_LABEL, String::from(ERROR)))
} else {
labels.push((RESULT_LABEL, String::from(OK)))
}
... // elided for brevity
metrics::increment_counter!(format!("{}_total", name), &labels);
metrics::histogram!(
format!("{}_duration_seconds", name),
elapsed_secs_f64,
&labels
);
... // elided for brevity
There are a lot of bits being pushed around in this example, and some of it is elided. Nonetheless, on_close, we always have access to the end of a span interval via elapsed_secs_f64, which can drive our histogram calculation via the metrics::histogram! macro.
Note that we’re leveraging the metrics-rs project here. Anyone can model this function the same way with another metrics library that provides counter and histogram support. From our storage map, we pull out all metric_*-labeled keys and use those to generate labels for the automatically derived incremented counter and histogram.
Also, if we’ve stored an event that errored out, we’re able to use that as part of the label, distinguishing our resulting functions based on ok/error. Given any instrumented function, we’ll derive metrics from it with this same code behavior.
The output we’d encounter from a Prometheus endpoint would show a counter that looks something like this:
db_event_total{event_table="events",event_type="Song",result="ok",span_name="save_event\"} 8
A question that does come up from time to time is how to instrument code with spans that reference an indirect, non-parent-to-child relationship, or what’s called a follows from reference.
This would come into play for async operations that spawn requests to side-effecting downstream services or processes that emit data to service buses where the direct response or returned output has no effect within the operation that spawned it itself.
For these cases, we can instrument async closures (or futures) directly by entering into a given span (captured as a follows_from reference below) associated with our async future each time it’s polled and exited every time the future is parked, as shown below with .instrument(process_span):
// Start a span around the context process spawn
let process_span = debug_span!(
parent: None,
"process.async",
subject = "songs.async",
category = "songs"
);
process_span.follows_from(Span::current());
tokio::spawn(
async move {
match context.process().await {
Ok(r) => debug!(song=?r, "successfully processed"),
Err(e) => warn!(error=?e, "failed processing"),
}
}
.instrument(process_span),
);
Much of the usefulness of observability comes from the fact that most services today are actually made up of many microservices. We should all be thinking distributed.
If all kinds of services have to connect to one another, across networks, vendors, clouds, and even edge-oriented or local-first peers, some standards and vendor-agnostic tooling should be enforced. This is where OpenTelemetry (OTel) comes into play, and many of the known observability platforms are more than happy to ingest OTel-compliant telemetry data.
While there’s a whole suite of open source Rust tooling for working within the OTel ecosystem, many of the well-known Rust web frameworks haven’t adopted the incorporation of OTel standards in a baked-in sort of way.
Popular, encompassing web frameworks like Actix and Tokio’s axum rely on custom implementations and external libraries to provide integration (actix-web-opentelemetry and axum-tracing-opentelemetry, respectively). Third-party integration has been the favored choice thus far, and while that promotes flexibility and user control, it can make it more difficult for those expecting to add the integration almost seamlessly.
We won’t cover writing a custom implementation here in detail, but canonical HTTP middleware like Tower allows for overriding the default implementation of span creation on a request. If implemented to spec, these fields should be set on a span’s metadata:
http.client_ip: The client’s IP addresshttp.flavor: The protocol version used (HTTP/1.1, HTTP/2.0, etc.)http.host: The value of the Host headerhttp.method: The request methodhttp.route: The matched routehttp.request_content_length: The request content lengthhttp.response_content_length: The response content lengthhttp.scheme: The URI scheme used (HTTP or HTTPS)http.status_code: The response status codehttp.target: The full request target including path and query parametershttp.user_agent: The value of the User-Agent headerotel.kind: Typically server, find more hereotel.name: Name consisting of http.method and http.routeotel.status_code: OK if the response is success; ERROR if it is a 5xxtrace_id: The identifier for a trace, used to group all spans for a specific trace together across processesTracing via tracing-opentelemetry and rust-opentelemetry exposes another layer with which we can compose our subscriber in order to add OTel contextual information to all spans and connect and emit these spans to observability platforms like Datadog or Honeycomb or directly to a running instance of Jaeger or Tempo, which can sample trace data for manageable consumption.
Initializing a [Tracer]() to produce and manage spans is pretty straightforward:
pub fn init_tracer(settings: &Otel) -> Result<Tracer> {
global::set_text_map_propagator(TraceContextPropagator::new());
let resource = Resource::new(vec![
otel_semcov::resource::SERVICE_NAME.string(PKG_NAME),
otel_semcov::resource::SERVICE_VERSION.string(VERSION),
otel_semcov::resource::TELEMETRY_SDK_LANGUAGE.string(LANG),
]);
let api_token = MetadataValue::from_str(&settings.api_token)?;
let endpoint = &settings.exporter_otlp_endpoint;
let mut map = MetadataMap::with_capacity(1);
map.insert("x-tracing-service-header", api_token);
let trace = opentelemetry_otlp::new_pipeline()
.tracing()
.with_exporter(exporter(map, endpoint)?)
.with_trace_config(sdk::trace::config().with_resource(resource))
.install_batch(runtime::Tokio)
.map_err(|e| anyhow!("failed to intialize tracer: {:#?}", e))?;
Ok(trace)
}
Including it within our pipeline of layers is straightforward as well. We can also filter based on level and use a dynamic filter to skip events that we’d like to avoid in our traces:
.with(
tracing_opentelemetry::layer()
.with_tracer(tracer)
.with_filter(LevelFilter::DEBUG)
.with_filter(dynamic_filter_fn(|_metadata, ctx| {
!ctx.lookup_current()
// Exclude the rustls session "Connection" events
// which don't have a parent span
.map(|s| s.parent().is_none() && s.name() == "Connection")
.unwrap_or_default()
})),
)
With this pipeline initialization, all of our application traces can be ingested by a tool like Jaeger, as we demonstrated earlier in this article. Then, all that’s left is data correlation, slicing, and dicing.
By composing these tracing layers together, we can expose system behavior information in a refined and granular way, all the while gaining enough output and enough context to start making sense of such behavior. All this customization still comes at a price: it’s not completely automatic all the way through, but the patterns are idiomatic, and there are open-source layers available to drop in for lots of normal use cases.
Of all things, this post should help make it easier for users to attempt customizing application interaction with trace collection and demonstrate how far it can go in preparing our applications to handle cases that inevitably fall between the cracks. This is just the beginning of our beautiful friendship with our events and when they happen, and thereby, observability. How we go about debugging and solving problems with it, in the long run, is always going to be ongoing work.
I’d like to offer my sincere thanks to Paul Cleary, Daniel Jin, Lukas Jorgensen, Jonathan Whittle, Jared Morrow, John Mumm, Sean Cribbs, Scott Fritchie, and Cuyler Jones for all their help, edits, and collaboration on this article.
Another major thank you to my team at fission.codes, especially Brian Ginsburg and Quinn Wilton, for all their backing on this, and to my advisor Frank Pfenning for putting up with me while I did some non-research work!
Debugging Rust applications can be difficult, especially when users experience issues that are hard to reproduce. If you’re interested in monitoring and tracking the performance of your Rust apps, automatically surfacing errors, and tracking slow network requests and load time, try LogRocket.
LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.

Modernize how you debug your Rust apps — start monitoring for free.

Learn how to build advanced Next.js forms with rule engines, client-side previews, Server Actions, and server-validated form logic.

AI is reshaping engineering teams emotionally as well as technically. A CTO shares insights on fear, trust, burnout, identity, and leading through AI change.

Learn what context rot is, why AI agent sessions degrade over time, and how to fix it with compaction, prompt anchoring, context files, plan files, and RAG.

Learn about TypeScript v6’s breaking changes, new ES2025 features, and deprecated options. A complete migration guide from v5 to prepare for v7.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

