In this article, we will describe how to export a simple REST API from Express.js to Wayne.js. We won’t just change a framework; we’ll translate from the cloud paradigm to the edge paradigm. Express.js is a simple web server designed to accommodate a REST API, and, on a smaller scale, it reproduces the concept of having the workload of the REST API executed on a server in a cloud setting. Wayne.js is a small toolkit that allows you to assemble a REST API within the browser.

Amazingly, these days you can see different design paradigms pushing the elaboration in two different directions. It’s possible to appreciate how both radically different visions still make sense. I am referring to the concepts of edge computing and cloud computing which are radically different approaches to deciding where most of the computation of a system is carried out. In cloud computing, the computation is carried out within clouds. In edge computing, the workloads are executed on edge devices, like browsers running on the users’ PC, mobile phones, and more.
I have prepared a GitHub repository with three directories to better understand these mechanisms. First, the basic directory contains the basic implementation of a service worker that will let us explore the simple mechanisms it offers. The second directory is simple-express, a straightforward REST API implemented using Express.js and Node.js. It will be our reference implementation, and I will show you how to migrate it to Wayne.js. The third directory is the Wayne directory, which contains the Wayne.js version of the REST API.
Jump ahead:
Wayne.js was designed to implement an HTTP server in a service worker running within a browser. Service workers host simple proxy mechanisms within the browser to contain the amount of traffic between the browser and the cloud, especially in scenarios where no or crippled internet access is available. Wayne.js leverages the concept of service workers to host more expressive things than simple proxy mechanisms.
Wayne.js uses the exact semantics of Express.js in a service worker to implement a REST API that runs right in the browser. Working with service workers is simple, and it is composed of the code to install them and the logic it implements. The code to install Wayne.js is pretty straightforward.
First, check the availability of the serviceWorker container in the navigator object. This is needed because it might not be available on older browsers or in private browsing mode:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function (registration) {
console.log('Service Worker installation success! Scope:',
registration.scope);
}).catch(function (error) {
console.log('Service Worker installation failed:', error);
});
}
The serviceWorker introduces the register method to tell the browser which JavaScript file to implement for the service worker’s logic. Here’s an example showing the sw.js file:
self.addEventListener('install', event => {
console.log("Service Worker Installed");
});
self.addEventListener('activate', event => {
console.log("Service Worker Activated");
});
self.addEventListener('fetch', event => {
console.log("Requested URL: " + event.request.url);
});
As you can see, it will print a message on each of the events of the lifecycle of a service worker. The first event is install, and it is helpful to do a one-time initialization needed by your service worker.
The second event happens once in a service worker’s life. This differs from install because instead of firing every time a new version of the service worker is installed, activate is only fired when the service worker is installed for the first time. This is because a previous version of the service worker is already running.
To force the activation of a new version of the service worker, you can ask your browser to install and activate on each page, reloading to always have the last version running. For example, the Update on Reload checkbox in Google Chrome is in the Application Tab in the developer window. A good rule of thumb for developing service workers is to always check that you are running the last version, even uninstall and reinstall it, to be sure. This will save a lot of head scratches when things aren’t working.
To check that everything works, serve the page with your web server of choice (I usually use http-server), and you will see the event correctly being fired in the console window:
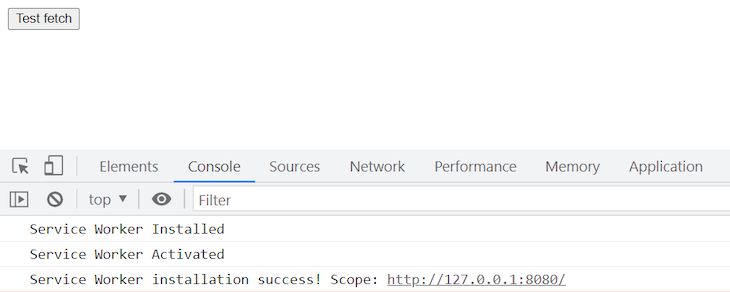
In the repository, in the directory simple-express, you will find a simple REST API. It’s not terribly exciting, but it is more than a “Hello, World!” API that shows the basics of an API. It has two GET services: one getting a parameter on the query string and another without parameters. Additionally, the API has a POST service taking parameters in the body.
It is an Express.js project, so you will be able to execute it with a simple node. that will execute simple-express.js. This will allocate the API services and serve the web application UI in the index.html file. By fiddling with the web app, you will be able to understand what you can do — just add elements to an array and list them.
So far, you should understand where Wayne.js does its magic. Wayne.js is a particular service worker that will mimic the structure of a REST API by redirecting the fetch operations that generally land on a server endpoint toward the methods implemented in the service worker file.
If you look at simple-express/simple-express.js and wayne/wayne-service-worker.js side by side, you will notice they are pretty much the same. Don’t worry. We’ll discuss their small differences shortly, but there is a paradigm shift here.
The Express.js version is executed on the server, while the Wayne.js version lives in the browser. To clarify, the Wayne.js API version is executed by http-server. This is from a server point of view, which shows that the API and the frontend are static files served to the browser. The whole API logic is executed just in the browser. This can be easily verified by checking the HTTP server logs:
![]()
Once index.html and wayne-service-worker.js are served to the browser, every successive interaction with the frontend will happen in the browser, producing no logs on the http-server. This shows the real potential of this approach, as you can even shut down the server. So, interactions and API calls will never leave the browser, making your application capable of running even in an offline mode:
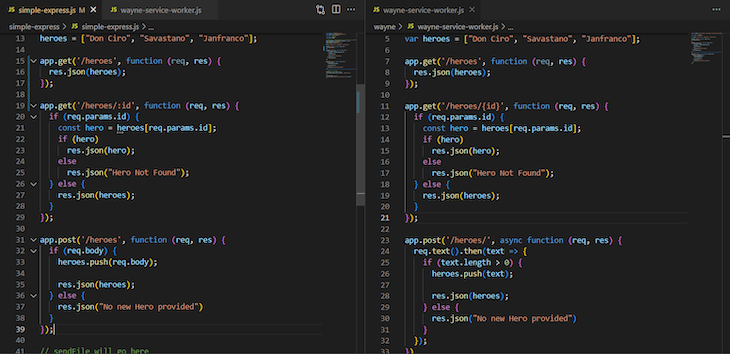
One of the differences between Wayne.js and Express.js for service worker routing is in how query String parameters are handled. In Express.js (right), the parameters are specified with a colon, while in Wayne.js, each parameter is defined by curly brackets (lines 19 on the right and 11 on the left).
Another difference is that the request body is available immediately, while in Wayne.js, it is accessed through a promise (line 32 on the left and line 24 on the right). On this mechanism, the documentation goes a little deeper. It offers various accessors to the body that return it in different formats:
arrayBuffer(): For an ArrayBuffer representationblob(): To get an unstructured Blob representation of the request bodyformData(): For FormDatajson(): That lets you handle the body as JSONtext(): The most straightforward representation of the request body, where any further parsing is left to youAs you can see, through these methods, you will be able to handle all standard formats you would expect to handle in a REST API. Additional functionality available on Wayne is the redirect() operation that lets you redirect API calls toward other endpoints. It works the same as in Express, but considering the different architecture of an in-browser API, you may use this mechanism to do something smart.
Suppose your local API can provide approximated results when the browser is offline and can redirect to a more powerful version of the same API when the browser gets online again, which can be done by redirecting the calls.
This is the proper way of realizing a Progressive Web Application (PWA). These web apps will keep working in limited or absent internet access and working seamlessly when the connection is re-established.
If you have followed me until this point, it should be clear by looking at the code there is no (significant) difference between writing a REST API for Express.js or Wayne.js. The primary difference is that Wayne.js lets you migrate your REST API right in the browser, providing support for a radically different architecture for your web app/API combination. This means that more code is executed in the browser, pushing computation to the edge, and more flexibility can be provided in an extreme situation where your web app can keep working under extreme conditions (i.e., no or unreliable internet connection).
Wayne.js is an intelligent way of designing a REST API and its frontend by letting you migrate any REST API to be run right in the browser without (too many) modifications. This article has described how to export a simple REST API from Express.js to Wayne.js. The idea is to show how it is possible to implement a REST API in a Wayne.js service worker running within a browser. In a more strategic view, Wayne.js can be a step toward developing a PWA that will keep working with a limited internet connection.
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Compare the top AI development tools and models of July 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Learn how to detect unused and ghost dependencies in JavaScript projects using Knip, a project-level linter that keeps your dependency graph accurate.

Learn how Storybook MCP enables AI agents to understand your component library, generate accurate UI, and validate code using documentation, stories, and automated tests.

Debug RSC hydration mismatches in production with Next.js instrumentation, Suspense isolation, HTML diffing, and CI smoke tests.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

