These days, writing software requires you to choose a programming language that can handle high scalability. When it comes to scalability, the best options are Go, Elixir, and Rust. Of course, there are other programming languages that achieve similar results. But when it comes to concurrency, which is one of the most important aspects of writing web applications, nothing compares to Elixir, Rust, and Go.

In this article, we will compare these three languages according to their functionalities, pros and cons, and code examples. Hopefully after reading this article, you’ll have a better idea of which programming language fits your needs.
Jump ahead:
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Elixir is a functional programming language that runs on the Erlang VM. It uses the same scripting style as Ruby; the only difference is that Ruby follows the object-oriented language paradigm, and Elixir follows the functional paradigm.
Here are some of the key features that make Elixir unique:
Elixir is a powerful and versatile programming language that is well-suited for building scalable, fault-tolerant applications. Its functional programming paradigm, concurrency features, and compatibility with the Erlang ecosystem make it a popular choice for various domains and industries.
Elixir is used by a variety of companies and organizations, including Pinterest, Bleacher Report, and Discord. Its ability to handle large amounts of traffic and its fault-tolerance make it a popular choice for building web applications and distributed systems.
Here are some notable Elixir users, according to their documents:
Let’s take a look the advantages and disadvantages of Elixir.
Elixir’s code runs through processes, which are lightweight and cheaper than threads, allowing you to create thousands or even millions of them. In Elixir, processes are isolated and don’t share memory; they communicate by sending messages to each other.
To create a new process using the spawn/1 function, which takes a function as an argument and returns a process identifier (PID), following the code block below:
process_pid = spawn(fn ->
IO.puts("Starting process")
end)
IO.puts("PID: #{inspect(process_pid)}") # PID: #PID<0.98.0>
To send a message from one process to another, you can use the send/2 function, specifying the recipient’s PID and the message. To receive messages, you can use the receive/1 function, which waits for a message matching a specified pattern. Messages are matched against patterns sequentially, allowing you to be selective of which messages you receive based on the message contents.
This is how we can send a message in Elixir:
send(process_pid, {:print_hello})
Elixir processes run concurrently, which means they can execute in an overlapping manner but they don’t necessarily run in parallel across multiple CPU cores. The concurrency model is based on the actor model, where processes communicate by passing messages. The model simplifies concurrent programming by eliminating shared state and focusing on isolated processes that communicate through messages.
To execute tasks in concurrency, Elixir provides the Task module, which schedules tasks on different processes. Here’s how we can run multiple tasks in parallel with the Task module:
tasks = [
Task.async(fn -> IO.puts("Doing work 1") end),
Task.async(fn -> IO.puts("Doing work 2") end)
]
for task <- tasks do
Task.await(task)
end
Now, let’s explore Go’s concurrency mechanisms.
We’ll start with goroutines, which are lightweight threads of execution in Go. You can think of goroutines as functions that run concurrently with other functions. To create a goroutine, you can simply use the go keyword followed by a function call:
func main() {
go myFunctionTask() // Start a new goroutine
// ...
}
Next up, we have channels. In Go, channels are used for communication and synchronization between goroutines. They allow you to safely send and receive values between goroutines.
You can create a channel using the make function and the chan keyword, specifying the type of data it will carry:
func main() {
ch := make(chan int) // Create an integer channel
go func() {
ch <- 42 // Send a value to the channel
}()
value := <-ch // Receive a value from the channel
fmt.Println(value) // Output: 42
}
By default, Go’s channels are unbuffered, meaning that sending and receiving operations is blocked until both the sender and receiver are ready. However, you can create buffered channels with a specific capacity.
Buffered channels allow you to send values without blocking until the channel is full. Here’s an example:
func main() {
ch := make(chan int, 2) // Create a buffered channel with capacity 3
ch <- 1 // Send values without blocking
ch <- 3
fmt.Println(<-ch) // Receive values from the channel
fmt.Println(<-ch)
}
In Go, the select statement is used to choose between multiple channel operations. It allows you to wait on multiple channels simultaneously and perform actions based on the first channel that becomes ready. Here’s an example:
func main() {
ch1 := make(chan int)
ch2 := make(chan string)
go func() {
time.Sleep(time.Second)
ch1 <- 42
}()
go func() {
time.Sleep(time.Second)
ch2 <- "Hello"
}()
select {
case value := <-ch1:
fmt.Println("Received from ch1:", value)
case message := <-ch2:
fmt.Println("Received from ch2:", message)
}
}
Now that we know the difference between the building blocks for implementing concurrency in Elixir and Go, let’s try to create a more complex concurrency model. This time, we will attempt to build a web crawler that will find all the links for a given URL.
The crawler that we’re building will crawl all the links for the given URLs, with the goal of getting all the links from the given URL. Here are the things that we want to avoid:
This tutorial won’t include all the code, but it will demonstrate the most important parts. To start, because Elixir is a functional language, we will be doing a recursive crawl of the website:
def run(start_url, scraper_fun, max_concurrency) do
Stream.resource(
fn -> {[start_url], []} end,
fn
{[], _found_urls} ->
{:halt, []}
{urls, found_urls} ->
{new_urls, data} = crawl(urls, scraper_fun, max_concurrency)
new_urls =
new_urls
|> List.flatten()
|> Enum.uniq()
|> Enum.reject(&diff_host?(URI.parse(start_url), &1))
|> Enum.map(&to_string/1)
|> Enum.reject(&Enum.member?(found_urls, &1))
{data, {new_urls, new_urls ++ found_urls}}
end,
fn _ -> IO.puts("Finished crawling for '#{start_url}'.") end
)
end
defp crawl(urls, scraper_fun, max_concurrency) when is_list(urls) do
urls
|> Task.async_stream(&crawl(&1, scraper_fun, max_concurrency),
ordered: false,
timeout: 15_000 * max_concurrency,
max_concurrency: max_concurrency
)
|> Enum.into([], fn {_key, value} -> value end)
# |> Enum.map(&crawl(&1, scraper_fun)) # To run without concurrency
|> Enum.reduce({[], []}, fn {scraped_urls, scraped_data}, {acc_urls, acc_data} ->
{scraped_urls ++ acc_urls, scraped_data ++ acc_data}
end)
end
So the crawler will filter the duplicate links to crawl, limit the crawler to the current domain only, and run on concurrency. Here’s the memory usage of our crawler in Elixir:
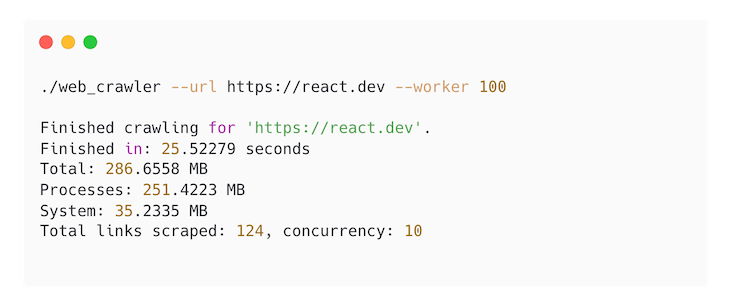
You can see the full code here. Now, let’s take a look a crawler implemented in Go:
type WebCrawler struct {
startURL *url.URL
visitedURL map[string]bool
mutex sync.RWMutex
wg sync.WaitGroup
semaphore chan struct{}
}
func (w *WebCrawler) crawl(rawURL string) {
w.mutex.Lock()
if _, found := w.visitedURL[rawURL]; found {
w.mutex.Unlock()
return
}
w.visitedURL[rawURL] = true
w.mutex.Unlock()
fmt.Printf("Start crawling: %s \n", rawURL)
parsedRawUrl, err := url.Parse(rawURL)
if err != nil {
fmt.Println(err)
return
}
bodyContent, err := utils.Request(rawURL)
if err != nil {
fmt.Println(err)
return
}
links, err := utils.ExtractLinks(string(bodyContent))
if err != nil {
log.Fatal(err)
}
host := parsedRawUrl.Scheme + "://" + parsedRawUrl.Host
for _, link := range links {
parsedLink, err := url.Parse(link)
if err != nil {
continue
}
absoluteLink := parsedRawUrl.ResolveReference(parsedLink)
absoluteLink.Fragment = ""
absoluteLink.RawQuery = ""
if !strings.HasPrefix(absoluteLink.String(), host) {
continue
}
w.wg.Add(1)
go func(link string) {
w.semaphore <- struct{}{} // Acquire semaphore
defer func() {
<-w.semaphore // Release semaphore
w.wg.Done()
}()
w.crawl(link)
}(absoluteLink.String())
}
}
This crawler is essentially doing the same thing as the one we have using Elixir. We use a wait group for syncing Go coroutines. Then, channels are managing the multiple processes, like how many concurrencies we want to run. We’re also using an RWMutex to manage the state of the links that we have already crawled, ensuring that we don’t visit a link that has already been visited:
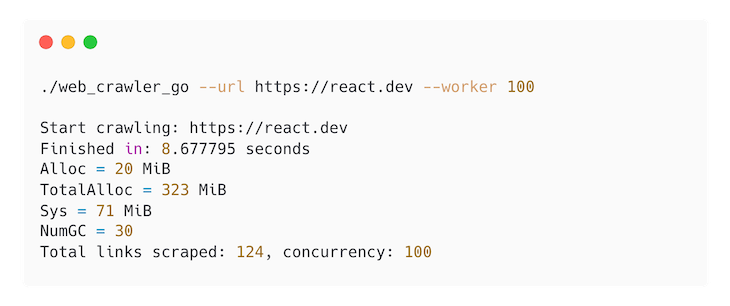
You can see the full code for the crawler here.
Rust is a programming language that builds reliable and efficient software. One of Rust’s focuses is to ensure that its programs are memory-safe. While Rust doesn’t support threads or coroutines like Elixir or Go, it provides lower-level building blocks to implement the runtime.
Today, we’re not going to build a concurrent runtime, but we will use one of the most popular async runtimes in Rust: Tokio. Async and concurrent are different, but we can use part of the Tokio library to make it work like a concurrent runtime.
Here’s how we can use Tokio crates to create a concurrent program:
tokio::spawn. Tokio will handle whether to run it in the current thread or another thread. We can also configure it to run on only one thread or multiple threadstokio::sync::mpsc, which will work like a channel in Goltokio::sync::Mutex to make sure that we can access shared state safelyHere’s an example of a simple asynchronous task using Tokio:
use tokio::time::{sleep, Duration};
#[tokio::main] // this starts a new Tokio runtime
async fn main() {
let task = tokio::spawn(async {
// simulate some work
sleep(Duration::from_millis(50)).await;
println!("Task is complete");
});
// wait for the task to complete
task.await.unwrap();
}
In this example, tokio::spawn starts a new task in the Tokio runtime, and tokio::time::sleep creates a future that completes after a certain amount of time. The await keyword is used to wait for these futures to complete, but it does not block the thread; instead, it allows other tasks to run.
In concurrency programming, you often need to share state between multiple tasks. The preferred way to do this is generally using message passing, as it’s safer and makes it easier to reason about the code. However, there are times when shared state is necessary.
To share state across tasks, you can use types such as Arc, RwLock, Mutex, and Semaphore, which are part of the tokio::sync module except Arc, which is part of std::sync. These types allow you to safely share mutable state across multiple tasks:
Arc, we can wrap any type or struct to be shared across the task or thread. For example, Arc<User> will store User in the heap. Then we can clone that instance to create a new arc instance that references User in the heapHere’s an example of shared state concurrency using Arc and Mutex:
use std::sync::Arc;
use tokio::sync::Mutex;
use tokio::spawn;
#[tokio::main]
async fn main() {
let data = Arc::new(Mutex::new(0));
let data1 = Arc::clone(&data);
let task1 = spawn(async move {
let mut lock = data1.lock().await;
*lock += 1;
});
let data2 = Arc::clone(&data);
let task2 = spawn(async move {
let mut lock = data2.lock().await;
*lock += 1;
});
task1.await.unwrap();
task2.await.unwrap();
assert_eq!(*data.lock().await, 2);
}
In this example, Arc<Mutex<i32>> is created to hold some data. Then, two tasks are spawned that each increment the data. Because Mutex ensures that only one task can access the data at a time, there are no data races, and the final result is as expected.
It’s worth noting that the locks provided by Tokio (such as Mutex and RwLock) are asynchronous, and they do not block the entire thread when contention occurs. Instead, they only block the current task, allowing other tasks to continue running on the same thread.
Now let’s build a simple web crawler using Rust and Tokio. First, lets define traits to run our crawler:
use crate::error::Error;
use async_trait::async_trait;
pub mod web;
#[async_trait]
pub trait Spider: Send + Sync {
type Item;
fn name(&self) -> String;
fn start_url(&self) -> String;
async fn scrape(&self, url: String) -> Result<Vec<Self::Item>, Error>;
}
Then, here’s the spider implementation:
impl WebSpider {
pub fn new(start_url: String, worker: usize) -> Self {
let http_timeout = Duration::from_secs(4);
let http_client = Client::builder()
.timeout(http_timeout)
.user_agent(
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0",
)
.pool_idle_timeout(http_timeout)
.pool_max_idle_per_host(worker)
.build()
.expect("WebSpider: Building HTTP client");
WebSpider {
http_client,
start_url,
}
}
}
#[async_trait]
impl super::Spider for WebSpider {
type Item = String;
fn name(&self) -> String {
String::from("WebSpider")
}
fn start_url(&self) -> String {
self.start_url.to_string()
}
async fn scrape(&self, url: String) -> Result<Vec<String>, Error> {
println!("Scraping url: {}", &url);
let raw_url = Url::parse(&url)?;
let host = raw_url.scheme().to_owned() + "://" + raw_url.host_str().unwrap();
let start = Instant::now();
let body_content = self.http_client.get(&url).send().await?.text().await?;
let seconds = start.elapsed().as_secs_f64();
if seconds > 3.0 {
println!(
"Parsing res body: {} in \x1B[32m{:.2}s\x1B[0m",
&url, seconds
);
}
let parser = Html::parse_document(body_content.as_str());
let selector = Selector::parse("a[href]").unwrap();
let links: Vec<String> = parser
.select(&selector)
.filter_map(|element| element.value().attr("href"))
.filter_map(|href| {
let parsed_link = raw_url.join(href);
match parsed_link {
Ok(link) => {
let mut absolute_link = link.clone();
absolute_link.set_fragment(None);
absolute_link.set_query(None);
if absolute_link.to_string().starts_with(&host) {
Some(absolute_link.to_string())
} else {
None
}
}
Err(_) => None,
}
})
.collect();
Ok(links)
}
}
Here’s the memory usage of our crawler in Rust. You can see the full code here.

So far, we have implemented our web crawler to Rust, Go, and Elixir. Now let’s run a benchmark to see how they each perform. We want to measure two things: how long it takes to complete a task, and how much memory will be used during the test. The crawler will fetch all the links in the domain https://react.dev. There are 127 links we expect to be fetched.
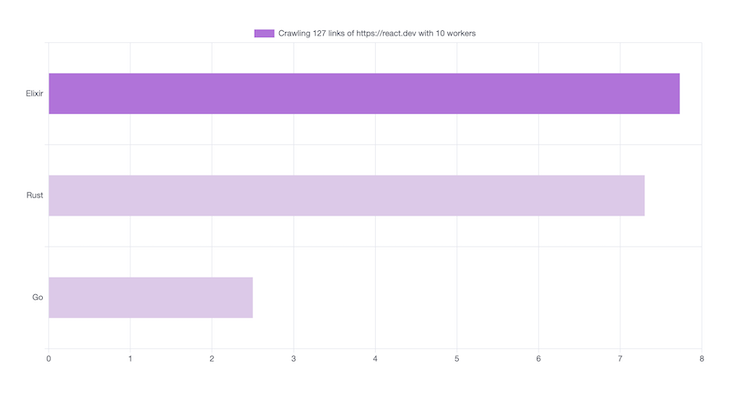
Using 10 concurrency workers, here is how long it took each web crawler to fetch the links:
HTTP requests take time to perform. This is because an SSL/TLS Handshake is created on each connection. The native Go HTTP library runs this concurrently out of the box, which is why Go performs the best in this scenario.
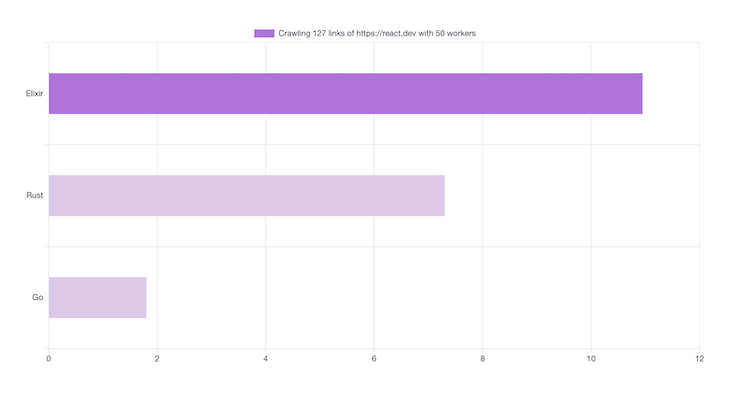
We still can optimize both Elixir and Rust to only make TLS/SSL Handshake once and use it across the workers:
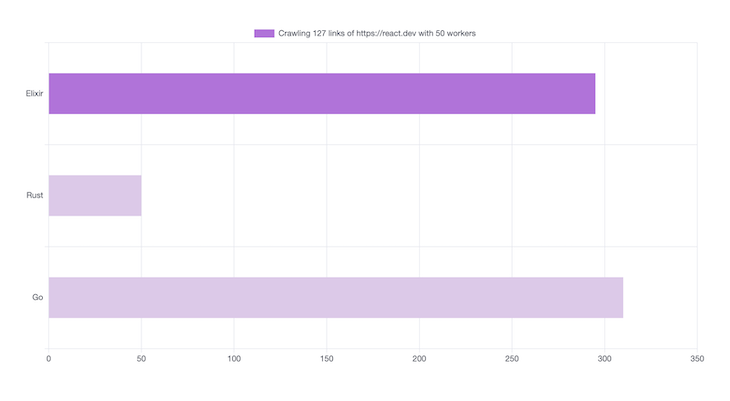
Here’s the result of 50 workers. Using more concurrency workers doesn’t mean that we can improve the speed of our crawler because it will be limited by the network latency:
Here’s the benchmark without concurrency:
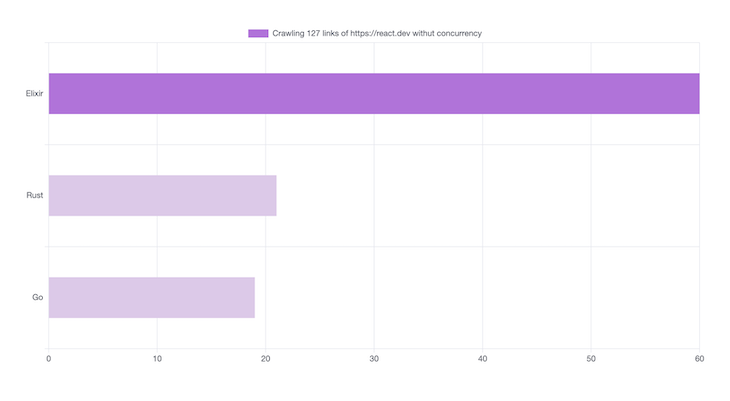
When it comes to memory usage, we have something interesting:
We can see that Rust performs better on memory usage, while Go and Elixir similarly perform worse:
In this tutorial, we learned how to work with Elixir, Go, and Rust to run concurrent programs. While each language has their own idea for how to handle concurrency, we were able to see that Go’s native library has great support for concurrency, but that it uses a lot of memory. This is because it allocates memory on heap and uses Garbage Collection to clean it up. This will cause large memory usage and some glitches when GC is performing the clean up.
In Elixir, we saw how easy it is to spawn processes and manage sharing state between processes. Yet, at the same time, it isn’t easy to make the concurrent program in Elixir perform better. Elixir uses Garbage Collection to manage memory so it performs similarly to Go.
While it isn’t easy to write concurrent programs in Rust, this language comes with the benefit that it will have memory-safety thanks to Rust’s ownership and type systems. Rust doesn’t use Garbage Collection like Golang and Elixir so it is more efficient when it comes to memory usage.
You can check out the full source code for this article here. Don’t forget to let me know if you have any questions or additional information you want to share.
Debugging Rust applications can be difficult, especially when users experience issues that are hard to reproduce. If you’re interested in monitoring and tracking the performance of your Rust apps, automatically surfacing errors, and tracking slow network requests and load time, try LogRocket.
LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.

Modernize how you debug your Rust apps — start monitoring for free.

Learn how Vite+ unifies Vite, Vitest, Oxlint, Oxfmt, Rolldown, and Node.js management in one CLI.

AI companies are buying developer tools as coding agents turn runtimes, package managers, and linters into strategic infrastructure.

Learn how AI-assisted development governance uses rules, agents, hooks, and protocols to help AI coding tools produce safer, more consistent code.

A step-by-step guide to building your first MCP server using Node.js, covering core concepts, tool design, and upgrading from file storage to MySQL.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

