When building applications, you might need to extract data from some website or other source to integrate with your application. Some websites expose an API you can use to get this information while some do not. In this case, you might need to extract the data yourself from the website. This is known as web scraping.

Web scraping is extracting data from websites by getting the data, selecting the relevant parts, and presenting them in a readable or parsable format.
In this tutorial, we will be taking a look at a Go package that allows us to build web scrapers, Colly, and we will be building a basic web scraper that gets product information from an ecommerce store and saves the data to a JSON file. Without further ado, let’s get started!
Colly is a Go framework that allows you to create web scrapers, crawlers, or spiders. According to the official documentation, Colly allows you to easily extract structured data from websites, which can be used for a wide range of applications, like data mining, data processing, or archiving. Here are some of the features of Colly:
Here’s a link to the Colly official website to learn more about it. Now that we know a bit about Colly, let’s build a web scraper with it.
To follow along with this tutorial, you need to have Go installed on your local machine and you need to have at least a basic knowledge of Go. Follow the steps here to install it.
Make sure you can run Go commands in your terminal. To check this, type in the command and go version in the terminal. You should get an output similar to this
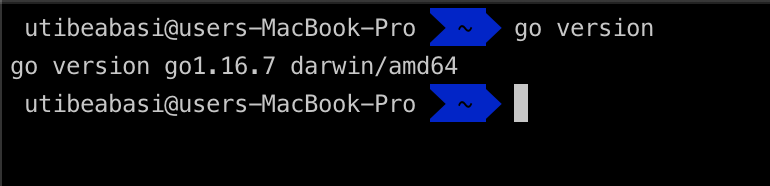
Alright, let’s start writing some code. Create a file called main.go and add the following code:
package main
import (
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.Visit("https://jumia.com.ng")
}
Let’s take a look at what each line of code does. First, the package main directive tells Go that this file is part of the main package. Next, we are importing Colly, and finally, we have our main function. The main function is the entry point of any Go program, and here we are instantiating a new instance of a Colly collector object.
The collector object is the heart of web scraping with Colly. It allows you to trigger certain functions whenever an event happens, such as a request successfully completes, a response is received, etc.
Let’s take a look at some of these methods in action. Modify your main.go file to this:
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.SetRequestTimeout(120 * time.Second)
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Got a response from", r.Request.URL)
})
c.OnError(func(r *colly.Response, e error) {
fmt.Println("Got this error:", e)
})
c.Visit("https://jumia.com.ng/")
}
First, we import the Go fmt package that allows us to print text to the console. We are also importing the time package. This allows us to increase the timeout duration of Colly to prevent our web scraper from failing too quickly.
Next, in our main method, we set the request timeout to 120 seconds and we call three callback functions.
The first is OnRequest. This callback runs whenever Colly makes a request. Here we are just printing out "Visiting" along with the request URL.
The next is OnResponse. This callback runs whenever Colly receives a response. We are printing out "Got a response from" along with the request URL as well.
The final call back we have is OnError. This runs whenever Colly encounters an error while making the request.
Before you run this, here are a couple of things you have to do:
First, initialize Go modules in the current directory. To do this, use the go mod init command:

Next, run go mod tidy to fetch all dependencies:
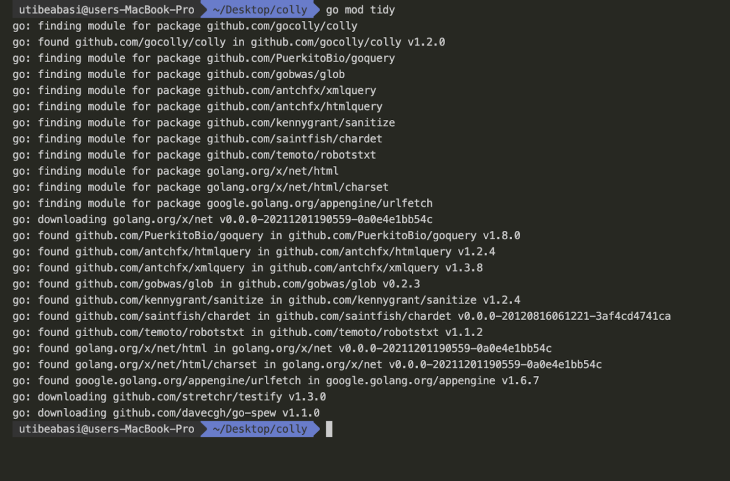
Now, let’s test our code so far. Run go run main.go to run the Go program:

As you have seen, we have successfully made a request to jumia.com.ng and we have gotten a response.
Alright, we have set up the basics of our web scraper, but before we go on, let’s analyze the website we are going to scrape. Navigate to the URL https://jumia.com.ng in your browser and let’s take a look at the DOM structure.
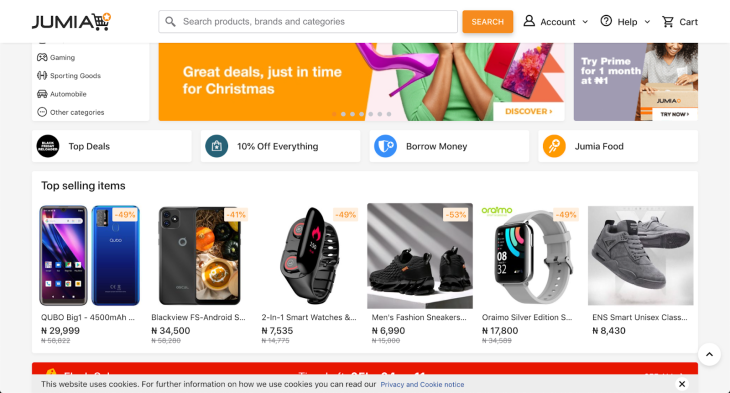
As you can see, the website has a bunch of cards with product information. Let’s inspect these cards in our browser’s dev tools. Open the dev tools by right-clicking on the cards and clicking Inspect or by clicking Shift+Ctrl+J (on Windows) or option+command+J (on Mac).
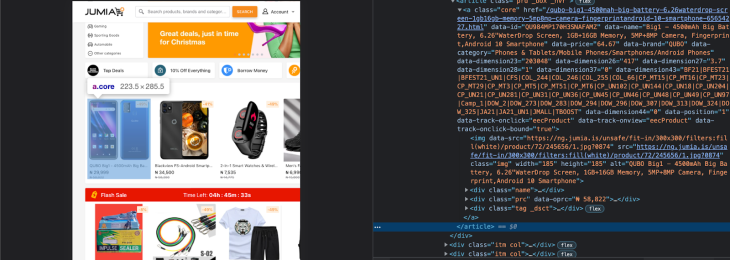
From the above, we can see that a single product card is an a tag with a class of core. This has various div elements nested within with classes of name, prc, and tag _dsct. These divs contain the product name, price, and discount respectively. In Colly, we can use CSS selectors to select these elements and extract the tags.
Now, let’s define the structure of a single product. Above your main method, add the following code:
type Product struct {
Name string
Image string
Price string
Url string
Discount string
}
Here, we are defining a struct to hold the name, image (URL), price, URL, and discount of each product. Now, modify your main method to this:
func main() {
c := colly.NewCollector()
c.SetRequestTimeout(120 * time.Second)
products := make([]Product, 0)
// Callbacks
c.OnHTML("a.core", func(e *colly.HTMLElement) {
e.ForEach("div.name", func(i int, h *colly.HTMLElement) {
item := Product{}
item.Name = h.Text
item.Image = e.ChildAttr("img", "data-src")
item.Price = e.Attr("data-price")
item.Url = "https://jumia.com.ng" + e.Attr("href")
item.Discount = e.ChildText("div.tag._dsct")
products = append(products, item)
})
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Got a response from", r.Request.URL)
})
c.OnError(func(r *colly.Response, e error) {
fmt.Println("Got this error:", e)
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
js, err := json.MarshalIndent(products, "", " ")
if err != nil {
log.Fatal(err)
}
fmt.Println("Writing data to file")
if err := os.WriteFile("products.json", js, 0664); err == nil {
fmt.Println("Data written to file successfully")
}
})
c.Visit("https://jumia.com.ng/")
}
Wow, a lot is going on here. Let’s take a look at what this code is doing.
First, we create an array of products and assign it to the products variable.
Next, we add two more callbacks: OnHTML and OnScraped.
The OnHTML callback runs when the web scraper receives an HTML response. It accepts two arguments: the CSS selector and the actual function to run. This callback selects the elements with the CSS selector and calls the function defined in the second parameter on the response.
The function gets passed the HTML element returned from the CSS selector and performs some operations on it. Here, we are selecting all a elements with a class name of core. Then we loop through the results and again select all divs nested within it with a class of name. From there, we create an instance of the Product struct and assign its name to be the text gotten from the div.
We use the e.ChildAttr function to get the data-src attribute of the first image tag nested within it and assign that as the product’s image. We use the e.Attr function to get the data-price attribute of the element and set that as the product’s price. We get its URL from the href attribute using the same method. Finally, we use the e.ChildText function to select the text from the div element with a class of tag _dsct and set that as the product’s discount.
Next, we append the product to the product list we created earlier.
The second callback we are defining is the OnScraped callback. This runs when the program has successfully finished the web-scraping job and is about to exit. Here, we are printing out `"Finished`" along with the request URL and then converting the products list to a JSON object.
Make sure to import the encoding/json package first. Note that we use the json.MarshalIndent function to do this to apply some formatting and indentation to the JSON object. Finally, we save the scrape results to a file.
Now that the code is all done, let’s run our program. Before we do this though, here’s the full code as a reference:
package main
import (
"encoding/json"
"fmt"
"log"
"os"
"time"
"github.com/gocolly/colly"
)
type Product struct {
Name string
Image string
Price string
Url string
Discount string
}
func main() {
c := colly.NewCollector()
c.SetRequestTimeout(120 * time.Second)
products := make([]Product, 0)
// Callbacks
c.OnHTML("a.core", func(e *colly.HTMLElement) {
e.ForEach("div.name", func(i int, h *colly.HTMLElement) {
item := Product{}
item.Name = h.Text
item.Image = e.ChildAttr("img", "data-src")
item.Price = e.Attr("data-price")
item.Url = "https://jumia.com.ng" + e.Attr("href")
item.Discount = e.ChildText("div.tag._dsct")
products = append(products, item)
})
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Got a response from", r.Request.URL)
})
c.OnError(func(r *colly.Response, e error) {
fmt.Println("Got this error:", e)
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
js, err := json.MarshalIndent(products, "", " ")
if err != nil {
log.Fatal(err)
}
fmt.Println("Writing data to file")
if err := os.WriteFile("products.json", js, 0664); err == nil {
fmt.Println("Data written to file successfully")
}
})
c.Visit("https://jumia.com.ng/")
}
In your terminal, run the command go run main.go.
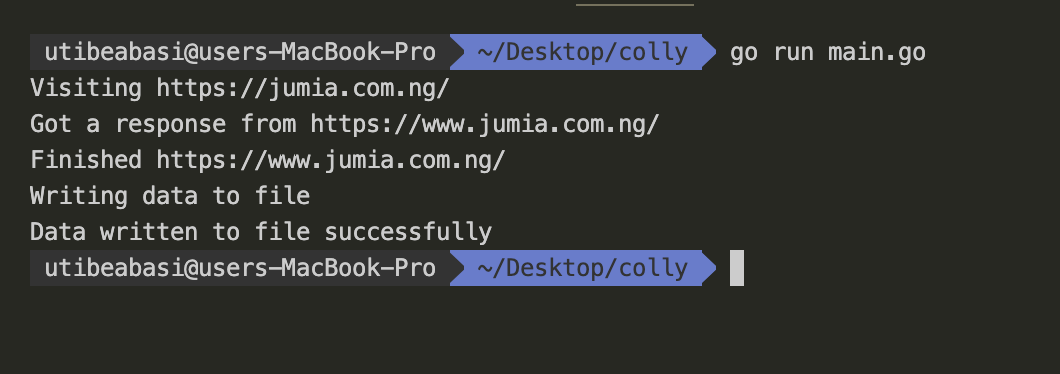
Great! It works! Now, you should see a new file has been created called products.json.
Open this file and you will see the scrape results.
In this article, we have successfully built a web scraper with Go. We looked at how we can scrape product information from an ecommerce store. I hope you learned a lot and will be applying this in your personal projects.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.

Learn how to use Fallow to analyze AI-generated code, detect dead code, duplicate logic, and complexity issues, and integrate automated code quality checks into your AI-assisted development workflow.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

