
GraphQL is an exciting API for ad-hoc queries and manipulation of hierarchical data. It is extremely flexible, has great tooling and provides many benefits compared to REST.
Facebook developed it in 2012 and uses it to power its massive social graph. GraphQL adoption skyrocketed after it was open sourced in 2015.
In this tutorial you’ll learn the principles of GraphQL, how it compares to REST, how to implement queries, and build a cool React application that will access the Github GraphQL.
GraphQL is first and foremost a query language and specification that gives front-end developers serious superpowers to query graph and hierarchical data.
With GraphQL, you can fetch many resources at different depths with a single call. But, GraphQL doesn’t stop there. It also supports mutations on your data, variables and even subscriptions (via WebSockets).
The foundation of GraphQL is its type system. There are basic types like String and Integer and there are complex types that have named attributes. Each attribute has a type, which can be basic or complex.
This is where the hierarchy comes in. When complex types have attributes that are complex types themselves. Specific GraphQL applications have a schema that defines all the types. The best part is that GraphQL supports introspection and you can query its schema to discover all the types and their attributes.
Let’s take a look at a quick example of the schema definition language. Here are two types: Player and Team. A team can have many players and a player belongs to a team. Also, both teams and players have names and the number of championships they won.
type Player {
id: ID
name: String!
team: Team!
championshipCount: Integer!
}
type Team {
id: ID
name: String!
players: [Player!]!
championshipCount: Integer!
}
Note that team’s players attribute is actually an array of player objects. The ID attribute is a basic type provided by GraphQL itself. The exclamation point means the attribute can’t be null. You can find the complete spec here.
Queries are also types. Here is a simple query that returns all the players:
type Query {
allPlayers: [Player!]!
}
To create new players we can define a mutation:
type Mutation {
createPlayer(name: String,
championshipCount: Int,
teamId: String): Player
}
This looks a lot like a function, but it’s a type. It’s the job of the server to parse/resolve the GraphQL expressions sent by the clients and apply them.
Another fun thing about GraphQL is its tooling. I really like the interactive graphical explorer GraphiQL. It lets you try different queries, while showing the target GraphQL schema and even have auto completion and built-in
validation.
Here is an example of querying starships from the star wars movies schema at https://graphql.github.io/swapi-graphql.
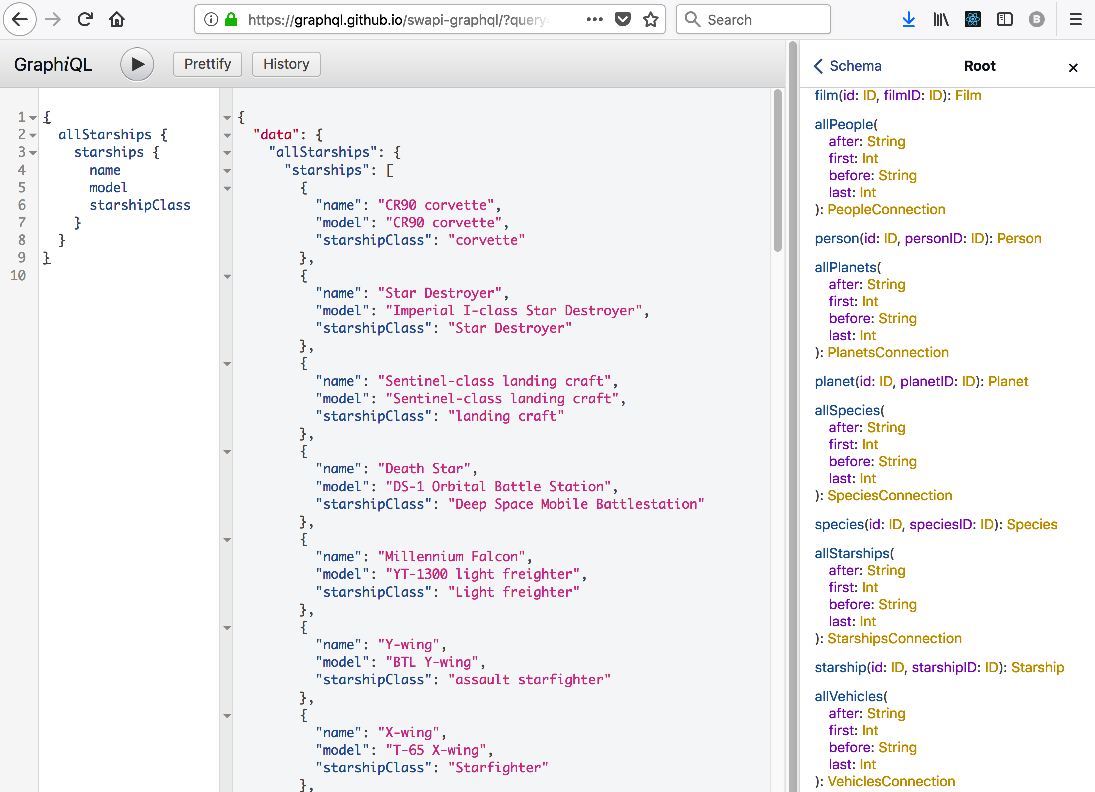
If you squint really hard, REST and GraphQL look pretty similar. Both adhere to a strict conceptual framework, both use HTTP as transport and both typically use JSON as payload.
However, the similarities end here. REST (representational state transfer) views the world as a set of resources that you can perform CRUD (create, read, update, and delete) operations on. It is tightly coupled to HTTP verbs and designed to take advantage of web infrastructure like caching. It is a neat idea, but it proved quite difficult to model real-world domain strictly using the resource-based view. Developers quickly deviated from the pure REST approach for practical reasons, but kept calling their APIs RESTful.
GraphQL, on the other hand, views the world as a graph of connected entities with attributes. This nodes, edges and attributes views is much more natural for modeling the world and is supported by a formal schema.
In addition, GraphQL solves the dreaded N+1 problem that REST APIs always struggled with. Suppose we’re modeling star wars movies as a REST API. We’ll have separate endpoints for movies, characters, directors, starships, planets etc. Each resource will be identified by ID.
Now, let’s try to get some nested information such as for each movie let’s fetch the director’s name, all the characters and for each character their name, eye color and planet name. To get this information, first we’ll need to fetch all the movies (1 query that returns N results). The movie resource will contain the ID of its director and a list of character IDs. Now for for each movie we need to hit the directors endpoint for each movie and fetch the director (N queries returning 1 result) and then we need to aggregate all the character IDs from all the movies, removing duplicates and hitting the characters endpoint for each one. Once we get the characters, we need for each character to hit the planets endpoint and fetch its home planet.
If you follow strict REST doctrine there is no way around it. You could design a bespoke endpoints like movies-with-their-director-and-characters-with-home_planet. But, this is not REST, it feels clunky and you’ll have to keep changing the backend to support different bespoke endpoints whenever the frontend decides that they want some other way to query the data.
Another problem with REST is over-fetching. Whenever you get a resource, you get all its attributes or fields. Often, a resource (or entity) will have many attributes, but you’ll be interested only in the name or title or some other subset of all attributes. With REST there is no way to specify it.
Again, you could come up with a way to encode it in query parameters, but think how cumbersome it would be if you also have bespoke endpoints to fetch hierarchical data. You’ll have to specify which attributes you’re interested in for each entity type in your query. GraphQL’s query language supports fetching exactly what you want naturally with its hierarchical structure and due to its schema can even generate tools and code to validate it automatically.
Last, but not least GraphQL goes beyond HTTP and supports subscriptions over WebSockets. Clients create stable connections to the server, which can push events to the clients.
The programmatic API of basic GraphQL without subscriptions is very simple. There is a single HTTP endpoint, a well-defined schema and a well defined query language that lets you send a single blob of JSON to slice and dice your data however you want. GraphQL supports pagination too of course when you need to iterate through large datasets. So, you can use any HTTP client to query (or mutate) any GraphQL service.
If you don’t need subscriptions (or the GraphQL server you connect to didn’t define any subscriptions) you can go ahead and just use the standard fetch API (or Axios) in your React application. However, if you want to incorporate subscriptions into your application I recommend using the Apollo client library.
The Apollo client adds some other nice capabilities like:
Let’s focus on basic GraphQL React and how to integrate it with React applications. The Apollo client magic would just get in the way and make it more difficult if not impossible to understand what’s going on.
GitHub (or should I say Microsoft GitHub?) exposes a very sophisticated and deep GraphQL API. The schema is pretty elaborate and contains many types that represent the deeply hierarchical object model of GitHub.
Here is a list of the kind of types supported by the Github GraphQL API with a couple of examples of each:
Notably, subscriptions are not supported.
I didn’t count, but there are easily more than a hundred different types that reflect every programmable and searchable aspect of GitHub.
GitHub even embedded a GraphiQL explorer you can play with to get familiar with the rich options it offers. The schema panel on the right side provides instant reference for all the root types and when you combine it with the autocompletion the result is a very discoverable and interactive experience.
Here is a screenshot demonstrating the schema documentation (with hyperlinks) on the right and auto-completion on the left:

Let’s go crazy. Microsoft has become a paragon of open source lately (that’s not the crazy part). How about the following query: get the total number of Microsoft repositories and their accumulated disk usage + the three most popular Microsoft repos based on number of stars sorted by popularity, for each repo display the project’s name, URL, number of stars and the username (url) of the last commit author.
Here is the GraphQL query:
{
organization(login: "Microsoft") {
repositories(first: 3,
orderBy: { field: STARGAZERS,
direction: DESC }) {
totalCount
totalDiskUsage
nodes {
name
homepageUrl
stargazers {
totalCount
}
commitComments(last: 1) {
nodes {
author {
url
}
}
}
}
}
}
}
The result is quite impressive. Microsoft has 1841 Git repositories on Github with a total disk usage of about 44 GB (the unit is kilobyes as I learned from the interactive documentation). The top 3 projects are VSCode (52,314 ★), TypeScript (35,065 ★) and surprisingly the cognitive toolkit (14,590 ★).
Here is the full JSON response:
{
"data": {
"organization": {
"repositories": {
"totalCount": 1841,
"totalDiskUsage": 44528492,
"nodes": [
{
"name": "vscode",
"homepageUrl": "https://code.visualstudio.com",
"stargazers": {
"totalCount": 52314
},
"commitComments": {
"nodes": [
{
"author": {
"url": "https://github.com/CruiseMan"
}
}
]
}
},
{
"name": "TypeScript",
"homepageUrl": "http://www.typescriptlang.org",
"stargazers": {
"totalCount": 35065
},
"commitComments": {
"nodes": [
{
"author": {
"url": "https://github.com/adiebohi"
}
}
]
}
},
{
"name": "CNTK",
"homepageUrl": "https://docs.microsoft.com/cognitive-toolkit/",
"stargazers": {
"totalCount": 14590
},
"commitComments": {
"nodes": [
{
"author": {
"url": "https://github.com/tprimak"
}
}
]
}
}
]
}
}
}
}
I invite you, brave reader, to extract the same information from Github’s REST API. Tell me how many API calls you had to make and how much redundant data you fetched.
Alright, GraphQL is cool. Let’s see how it works inside a React application.
The demo app is ironically stored on GitLab. This is unrelated to the recent Microsoft announcement. I have many projects on GitHub and GitLab and I plan to keep using both. The app queries the GitHub GraphQL API for recent Kubernetes releases and displays them in a table.
I care about Kubernetes releases because PacktPub recently published the second edition of my book Mastering Kubernetes, which is up to date to the latest 1.10 Kubernetes release. I’m closely following the Alpha and Beta releases to stay on top of the latest developments.
Here is the query I’ll use:

And, here is the app itself:

I apologize profusely for my hideous design skills.
Anyway, the app is based off create-react-app. There are very few reasons to start a React project in 2018 in any other way.
Let’s dive right into the code.
There is a main App component, a DataFetchForm component and a ReleaseList component. The App is responsible for all the interaction with the Github API server. The DataFetchForm is a form that is responsible for getting the Github access token necessary to authenticate the application to the Github GraphQL server. The ReleaseList is a simple functional component that displays the table with each release name and when it was published.
This component stores in its state the token (initially empty) and the onFetch callback it receives in its props.
import React, {Component} from 'react'
class DataFetchForm extends Component {
constructor(props) {
super(props)
this.state = {
onFetch: props.onFetch,
token: '',
}
}
The render() method displays the form with a password input field for the auth token (security, first. right?) and a “fetch” submit button. The fetch button is enabled only when you enter a token. Whenever you change the value of the token the onChange() method is called and when you click “fetch” the onFetch() method is called.
render = () => {
return (
<form onSubmit={this.onSubmit}>
<label>
Auth token:
<input type="password"
value={this.state.token}
onChange={this.onChange}
/>
</label>
<input type="submit"
value="Fetch"
disabled={this.state.token === ''}
/>
</form>
)
}
The onChange() method just stores the current auth token in the state:
onChange = event => this.setState({…this.state, token: event.target.value})
The onSubmit() method invokes the onFetch() callback function it received from its parent as a prop, passing it the auth token:
onSubmit = event => {
this.state.onFetch(this.state.token)
event.preventDefault()
}
This component displays a table with release name and publish date in esch row. Its claim to fame is that it can ignore pre-release releases. It also converts the publish timestamp into a more humane date string. Then it constructs an array of rows called unimaginatively “rows” and sticks them in the middle of the table boilerplate.
import React from 'react'
import '../App.css'
const ReleaseList = ({count, releases, includePrerelease}) => {
if (releases.length === 0) {
return null
}
if (!includePrerelease) {
releases = releases.filter(r => !r.isPrerelease)
}
let rows = releases.map(r => <tr key={r.name}>
<td>{r.name}</td>
<td>{(new Date(r.publishedAt)).toDateString()}</td>
</tr>)
return <table>
<thead>
<tr>
<td>Name</td>
<td>Published On</td>
</tr>
</thead>
<tbody>
{rows}
</tbody>
</table>
}
export default ReleaseList
If you must admire this canonical masterpiece of web design you can check out the App.css file.
The App component is the cool kid. It starts quite humbly by importing React, the various components, the css file and Axios (better HTTP client than the built-in fetch API). Then, it defines the GitHub GraphQL API endpoint and the number of requested releases. The state just keeps a list of releases initially empty.
import React, {Component} from 'react'
import './App.css'
import ReleaseList from "./components/ReleaseList"
import DataFetchForm from "./components/DataFetchForm"
import axios from 'axios'
const githubApiUrl = 'https://api.github.com/graphql'
const releaseCount = 10
class App extends Component {
constructor(props) {
super(props)
this.state = {
releases: []
}
}
The render() method is quite pedestrian too. It displays the header, the data fetch form (passing it the onFetch() method) and finally the ReleaseList with the release count, the list of releases from the state and false to ignore pre-release releases.
render() {
return (
<div className="App">
<header className="App-header">
<h1 className="App-title">
React + GraphQL + Github API Demo App
</h1>
</header>
<h2 className="App-intro">
Kubernetes Releases
</h2>
<DataFetchForm onFetch={this.onFetch}/>
<ReleaseList count={releaseCount}
releases={this.state.releases}
includePrerelease={false}/>
</div>
)
}
}
Alright, here we go. The onFetch() method as you recall is invoked when in the DataFetchForm the user clicks the fetch button. The query string is multi-line GraphQL query. Note that it must start with a “query” keyboard that is not needed in the graphiql explorer. The releaseCount is injected from the constant at the top of the file.
Then, it called makes axios.post() passing the jsonified query and the auth token. When the result comes back it just stores the releases as is in the state. Extracting the data requires some drilling with r.data.data.repositorty.releases.nodes, but that’s not too bad. Later the ReleaseList component will make sense out of the data.
onFetch = (token) => {
const query = `
query {
repository(name: kubernetes, owner: kubernetes) {
releases(first: ${releaseCount},
orderBy: { field: CREATED_AT, direction: DESC}) {
totalCount
nodes {
name
publishedAt
isPrerelease
}
}
}
}
`
axios.post(githubApiUrl,
JSON.stringify({query}),
{headers: {Authorization: `bearer ${token}`}})
.then(r => {
this.setState({...this.state, releases: r.data.data.repository.releases.nodes})
})
.catch(e => console.log(e))
}
GraphQL is a powerful and flexible tool for slicing and dicing hierarchical data. It solves some nontrivial problems that REST APIs present and has fantastic tooling and community.
The GitHub API is a comprehensive and well-designed GraphQL API that showcases the benefits of GraphQL in the real world. The demo app I presented shows how easy it is to incorporate GraphQL into React applications, even without fancy libraries like ApolloClient.
Now, it’s your time to play with GraphQL and build cool stuff.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

